
Важная характеристика
Стремительный рост вычислительных возможностей компьютеров позволил человечеству обучать нейронные сети, содержащие огромное количество преобразований (их также называют «слоями»). Количество слоёв, из которых состоит нейросеть, называют её глубиной. Выяснилось, что именно благодаря увеличению глубины нейросети способны качественно решать сложные задачи. Однако от глубины зависит не только качество решения задач, но и многие важные свойства нейросети, а также сложность процедуры обучения. Это наблюдение породило большое количество исследовательских и инженерных вопросов, что привело к образованию области глубинного обучения, которая занимается исключительно изучением глубоких нейросетей.
Небольшая предыстория
Первые нейросети были разработаны ещё в 1950-х, однако их доминирование в практически всех сферах анализа и обработки данных началось на 60 лет позже. В 2006 году Алекс Крижевский выигрывает ImageNet Large Scale Visual Recognition Challenge – соревнование по распознаванию образов на изображениях. Каждое изображение принадлежит одной из 1000 категорий, задача модели – по изображению предсказать его категорию. Новая модель ошибалась на 10.8% реже, чем предыдущее лучшее решение. Секрет успеха AlexNet – большая глубина нейросети и использование видеокарт для обучения вместо процессора. Победа AlexNet продемонстрировала потенциал нейросетей и послужила мощным толчком для развития глубинного обучения.
Машинное обучение, нейросети и глубинное обучение – кто есть кто?
Зачастую вышеперечисленные термины для обычного человека означают примерно одно и то же (чаще что-то одинаково непонятное). Однако на самом деле эти термины означают разные вещи.
Машинное обучение – это набор методов, который позволяет на основе данных «обучить» компьютер решать сложные задачи, снимая с человека необходимость создавать точный алгоритм решения. Например, создать пошаговый алгоритм, по которому компьютер будет отличать кошек и собак на изображениях, крайне сложно из-за большой вариативности изображений с животными, а обучить модель на выборке таких изображений относительно просто. Узнать больше о машинном обучении, задачах, которые оно решает, моделях и их обучении можно в нашем материале.
Нейросеть – это одна из моделей машинного обучения, способная объяснять сложные зависимости в данных. Под зависимостями в данных можно понимать связь между входными данными и выходными: между изображением и его категорией, между аудиодорожкой и её транскрипцией, между корпусом текстов и векторными представлениями слов. Было доказано, что нейросети способны объяснить, или другими словами, моделировать любую зависимость с наперёд заданной точностью [1]. Способность модели объяснять зависимости называется выразительностью. Выразительность нейросети определяется многими факторами, одним из которых является глубина.
Нейросеть состоит из последовательности математических преобразований, которые также называют слоями. Примеры слоёв: линейный слой (как модель линейной регрессии), свёрточный слой, который особенно эффективен для обработки изображений. Глубина нейросети – это количество слоёв, из которых она состоит.
Глубина модели – крайне важная характеристика модели. Можно ли сказать, что чем больше слоёв, тем более выразительна нейросеть?

Однозначно дать ответ на этот вопрос нельзя. Помимо глубины модели существует ряд факторов, которые определяют её: например, порядок и тип слоёв, количество данных, на которых происходит обучение, параметры обучения – поэтому простое добавление слоёв чаще всего не приводит к хорошим результатам.
Возможность работать с глубокими моделями поставила ряд нетривиальных вопросов: Как подбирать архитектуру модели (выбирать тип слоёв, их порядок и количество)? Как эффективно обучать глубокие модели? На что и как влияет глубина? – именно на эти вопросы пытается ответить подобласть машинного обучения – глубинное обучение.
Глубже – сложнее
Как говорилось выше, нейросеть состоит последовательности слоёв – различных математических преобразований. Каждый слой на вход получает результат работы предыдущего слоя и на выходе выдаёт промежуточное представление данных.
Рассмотрим этот процесс более конкретно на примере нейросети для распознавания лиц. Для изображений наиболее часто используются модели со свёрточными слоями. Основная функция этого слоя – выделение определённых фрагментов или узоров на изображении. Такое выделение осуществляется с помощью применения фильтра к исходному изображению. Фильтр – это изображение, которое содержит в себе образец элементов, которые необходимо выделить. На изображении снизу можно видеть результат применения фильтра границ:
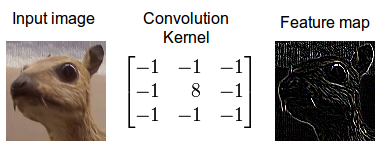
Свёрточный слой может содержать сразу несколько разных фильтров и, соответственно, генерировать несколько выходных изображений, на каждом из которых выделены те или иные признаки. Фильтры подбираются без участия человека в процессе обучения нейросети.
Через визуализацию фильтров разных слоёв обученной нейросети можно проследить зависимость их абстрактности и сложности от глубины слоя:

Можно видеть, что на первом слое фильтры детектируют простые изгибы, на втором – части лица, а на третьем – целые лица. То есть чем глубже слой, тем более сложные и информативные признаки извлекает нейросеть. Однако важно отметить, что это выполняется, если все остальные характеристики модели (порядок и тип слоёв), а также параметры обучения подобраны оптимально. В противном случае добавление слоёв либо никак не повлияет на информативность извлекаемых признаков, либо даже ухудшит их качество.
Подбор оптимальных характеристик и настройка процедуры обучения глубоких нейросетей – непростая задача. Так, до выхода статьи Deep Residual Learning for Image Recognition [2] исследователям удавалось обучать только сети средней глубины. Помимо этого есть зависимость между глубиной модели и размером обучающей выборки – чем больше слоёв с обучаемыми параметрами в сети, тем больше данных необходимо для обучения. Глубокую нейросеть не обучишь на «маленьких» данных.
Последний ингредиент успешного обучения глубокой нейросети – графический процессор (видеокарта). Большинство программ на компьютере выполняются обычным процессором (CPU), но для некоторых задач оказалось удобнее использовать видеокарты. Все дело в том, что в отличие от обычного процессора графический процессор способен эффективно выполнять операции параллельно. А это как раз то, что нужно для глубоких нейросетей. Распараллеливание в десятки раз ускоряет процесс обучения и позволяет обучать очень глубокие модели.
Помимо сложностей описанных выше исследователи встречаются и с другими проблемами глубоких сетей. Одна из таких проблем – сложность или невозможность интерпретации модели. В редких случаях (как в примере с распознаванием лиц) получается понять, какие признаки извлекает модель и какую важность она им присваивает. Понимание, как модель работает «внутри», важно не только в исследованиях, но и в практических применениях: например, если решение о выдаче кредита генерируется моделью, то необходимо иметь возможность объяснить клиенту, почему модель вынесла именно такой вердикт.
Источники
[1] Hornik, K., Stinchcombe, M., & White, H. (1989). Multilayer feedforward networks are universal approximators. Neural networks, 2(5), 359-366.
[2] He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).



