
Что такое анализ тональности текста?
Анализ тональности текста (Sentiment Analysis) — это процесс автоматического определения эмоциональной окраски содержания текста. В классическом варианте он часто используется в прикладных задачах классификации в области обработки естественного языка (NLP).
Подобная задача обычно выглядит так: дано множество текстов, которые необходимо разделить на несколько заранее заданных групп, исходя из их содержания. Обычно выделяют три основные категории: позитивная, нейтральная и негативная. Используя эту классификацию, можно настроить фильтрацию комментариев, отзывов или добавить дополнительную информацию о текстовых данных для моделей машинного обучения, что может быть полезно в рекомендательных системах и поисковой выдаче.
Первые задачи анализа тональности решались с использованием заранее размеченных словарей, например, таких как kartaslovsent, где каждому слову соответствовала определённая эмоциональная оценка. Классификация же производилась алгоритмами машинного обучения, такими как Naïve Bayes и SVM (Support Vector Machine).
С развитием технологий нейронных сетей появились более точные методы, основанные на эмбеддингах. Современные модели используют предобученные нейросети-энкодеры, такие как BERT, которые способны учитывать контекст и взаимосвязь между словами, что особенно важно для сложных текстов. Теперь классификаторы могут даже понимать иронию и сарказм, относя текст к нужной группе.
Некоторые подходы выходят за рамки традиционной дискретной классификации. Если поменять тип задачи с классификации на регрессию и научить нейросети присваивать текстам количественную оценку по шкале тональности, можно добиться более тонкой оценки содержания с учётом градации, например, слабоположительных или гневных отзывов и комментариев.
Гораздо менее распространено построение кривых эмоциональной тональности. Это графическое представление изменений тональности текста на протяжении его длины. Такие кривые отображают, как эмоциональный фон текста колеблется между положительными, нейтральными и отрицательными значениями, позволяя визуализировать эмоциональную динамику. С большой долей вероятности идея создания подобных кривых принадлежит Курту Воннегуту. В своей лекции писатель с невероятной точностью описал процесс, который будет разобран в этом гайде.
Одна из первых работ, описывающих построение кривых эмоциональной тональности на практике, принадлежат Эндрю Рейгану из Вермонтского университета и его коллегам [1].
Её содержание гораздо проще описать картинкой ниже, нежели словами:
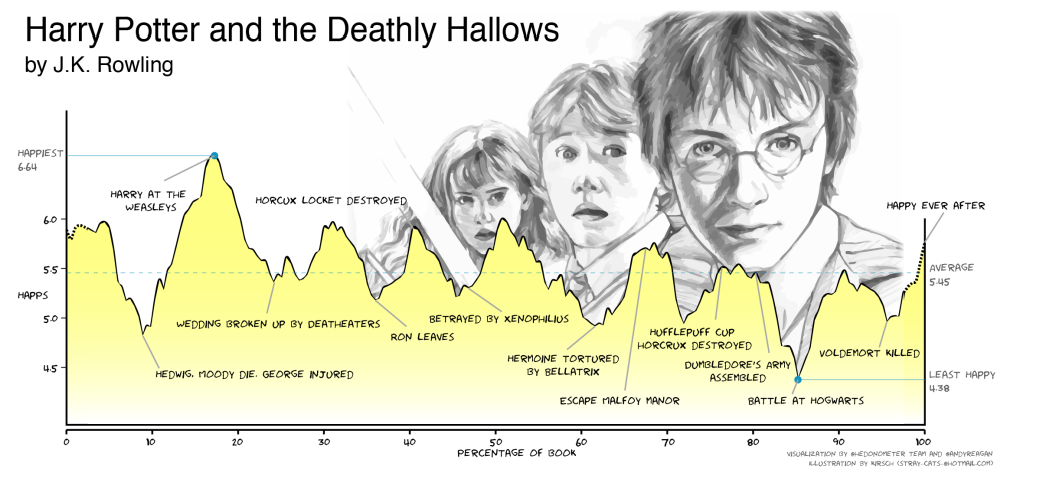
Кривая эмоциональной тональности книги «Гарри Поттер и Дары Смерти» из упомянутой статьи Рейгана [1]
В этом гайде будет показано, как повторить результаты Рейгана и его коллег, используя Python и нейросеть RuBERT для русского языка.
Как построить кривые эмоциональной тональности текста с помощью Python и RuBERT
Рейган строил свои кривые эмоциональной тональности, используя размеченный словарь, поскольку тогда ещё не существовало нейросетей-энкодеров. Конечно, мы тоже могли бы пользоваться словарём, но давайте лучше применим нейросеть RuBERT, которая справляется с оценкой тональности гораздо лучше.
Сначала импортируем библиотеки и функции, которые нам понадобятся:
# Регулярные выражения потребуются для очистки текста
import re
# Библиотека razdel потребуется для разбиения текста на предложения
# перед отправкой в нейросеть
from razdel import sentenize
# Без torch невозможна работа с нейросетями
import torch
# Библиотека transformers нужна для работы с нейросетями-трансформерами,
# которые мы будем использовать для анализа тональности
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# Библиотека matplotlib позволит построить графики кривых тональности
from matplotlib import pyplot as plt
# Фильтр Савицкого-Голея понадобится нам для обработки результатов,
# которая будет описана позже
from scipy.signal import savgol_filterЕсли в ходе импорта возникли ошибки, то, скорее всего, на компьютере отсутствуют какие-то из перечисленных библиотек. Установите их, следуя гайдам, официальной документации или воспользуйтесь готовым блокнотом в Google Colab.
Можно начинать! Создайте в директории проекта (папке, где находится сам файл с кодом) файл c расширением .txt и поместите туда текст, кривую эмоциональной тональности которого вы хотите построить.
В качестве примера текста в гайде будет использоваться «Герой нашего времени» М. Ю. Лермонтова:
# Считываем текст из целевого файла text.txt
with open('text.txt') as file:
text = file.read()Вполне возможно, что вместе с самим текстом считались символы переноса строки (\n). Определим функцию clean_text, которая очистит от них текст:
def clean_text(text: str) -> str:
# Заменяем переносы строк на пробелы
text = text.replace('\n', ' ')
# Убираем лишние пробелы
cleaned_text = re.sub(r'\s+', ' ', cleaned_text).strip()
return cleaned_textПрименим функцию clean_text и получим очищенный от служебных символов текст, записанный в строковую переменную cleaned_text:
# Очищаем текст
cleaned_text = clean_text(text)Чтобы провести динамический анализ тональности, нужно разбить текст на атомарные единицы, которые будут подаваться на вход нейросети. Они не должны быть слишком маленькими, так как в этом случае модель перестанет чувствовать контекст и потеряет своё главное преимущество перед словарём. Они не должны быть и слишком большими, так как размерности входного слоя нейросети может не хватить. В случае книг в качестве этих атомарных единиц лучше всего использовать предложения. Предложения достаточно маленькие по размеру, но выражают законченную мысль. То, что нужно!
Воспользуемся функцией sentenize из razdel, чтобы произвести разбиение, и запишем сами предложения в список sentences:
# Разбиваем текст на предложения и загружаем их в список
sentences = []
for substring in list(sentenize(cleaned_text)):
sentences.append(substring.text)Текст подготовлен для загрузки в сеть. Выберем модель для оценки тональности на сайте HuggingFace, хранилище готовых к использованию предобученных моделей. Создадим её экземпляр в коде и определим функцию estimate_sentiment, которая принимает на вход списки с предложениями, а выдаёт списки с оценками тональности.
# Загрузим модель с сайта HuggingFace и создадим ее экземпляр
model_checkpoint = 'cointegrated/rubert-tiny-sentiment-balanced'
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint)
if torch.cuda.is_available():
model.cuda()
# Сложная функция, которая заставит модель работать
def estimate_sentiment(messages: list) -> list:
sentiment_out = []
for text in messages:
with torch.no_grad():
inputs = tokenizer(text, return_tensors='pt', truncation=True, padding=True).to(model.device)
proba = torch.sigmoid(model(**inputs).logits).cpu().numpy()[0]
sentiment_out.append(proba.dot([-1, 0, 1]))
return sentiment_outНеобязательно ограничиваться нейросетью rubert-tiny-sentiment-balanced. На сайте есть огромное количество других моделей для оценки тональности с информационными карточками и готовыми примерами использования.
Теперь воспользуемся нашей готовой моделью:
# Произведем нейросетевую оценку тональности
sentiments = estimate_sentiment(sentences)Придётся немного подождать. От 10 до 60 секунд — в зависимости от объёма текста и мощности компьютера. За это время RuBERT поставит в соответствие каждому предложению вещественное число от -1 до 1, отражающее тональность этого предложения
Построим график, чтобы посмотреть, как меняется тональность текста в динамике.
# Построим график кривой эмоциональной тональности
plt.figure(figsize=(8,6), dpi=300)
plt.plot(sentiments)
plt.xlabel('Номер предложения')
plt.ylabel('Тональность')
plt.grid()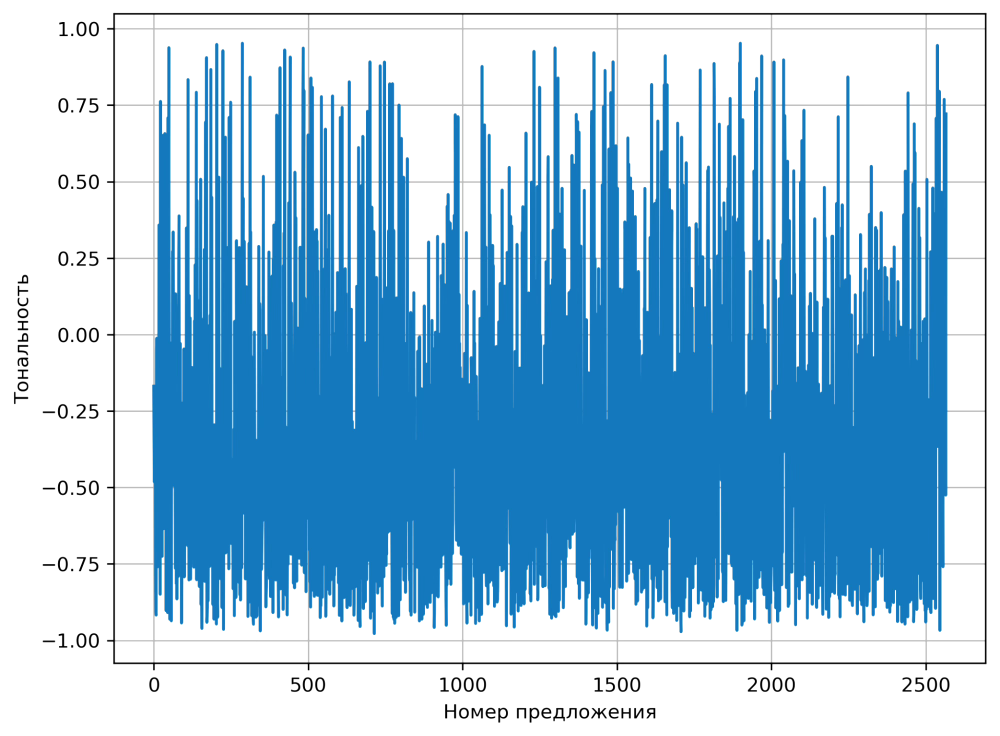
Зашумлённая кривая эмоциональной тональности «Героя нашего времени»
Будем честны, получилось не очень. При внимательном рассмотрении можно разглядеть очертания некоторой формы, сильно искажённой скачками и перепадами. Дело в том, что тональность предложений внутри текста может испытывать резкие перепады, а нейросеть может иногда ошибаться. В результате возникают шумы и некоторая неустойчивость оценки.
Как избавиться от шума. Фильтр Савицкого-Голея
Проблему можно было бы решить, используя в качестве атомарных единиц фрагменты текста большего размера, например, главы. Это не универсальный подход, так как его результаты станут сильно разниться в зависимости от объёмов текста. Решим задачу более изящно и применим фильтры, пришедшие к нам из теории обработки сигналов и призванные отделять полезный сигнал от шумов, которые возникают при его передаче. Выберем фильтр Савицкого-Голея. Это улучшенная версия скользящего среднего, которое использовал Рейган. Страничка о фильтре на Википедии может напугать неподготовленного зрителя весьма сложным математическим описанием фильтра, однако наглядные анимации помогут интуитивно разобраться с принципом его работы.
Фильтр уже реализован в Python. Отфильтруем сигнал кривой тональности и построим график заново:
# Произведем фильтрацию сигнала фильтром Савицкого-Голея
filtered_sentiments = savgol_filter(sentiments, window_length=len(sentiments)//15, polyorder=0)
# Построим график кривой эмоциональной тональности
plt.figure(figsize=(8, 6), dpi=300)
plt.plot(filtered_sentiments)
plt.xlabel('Номер предложения')
plt.ylabel('Тональность')
plt.grid()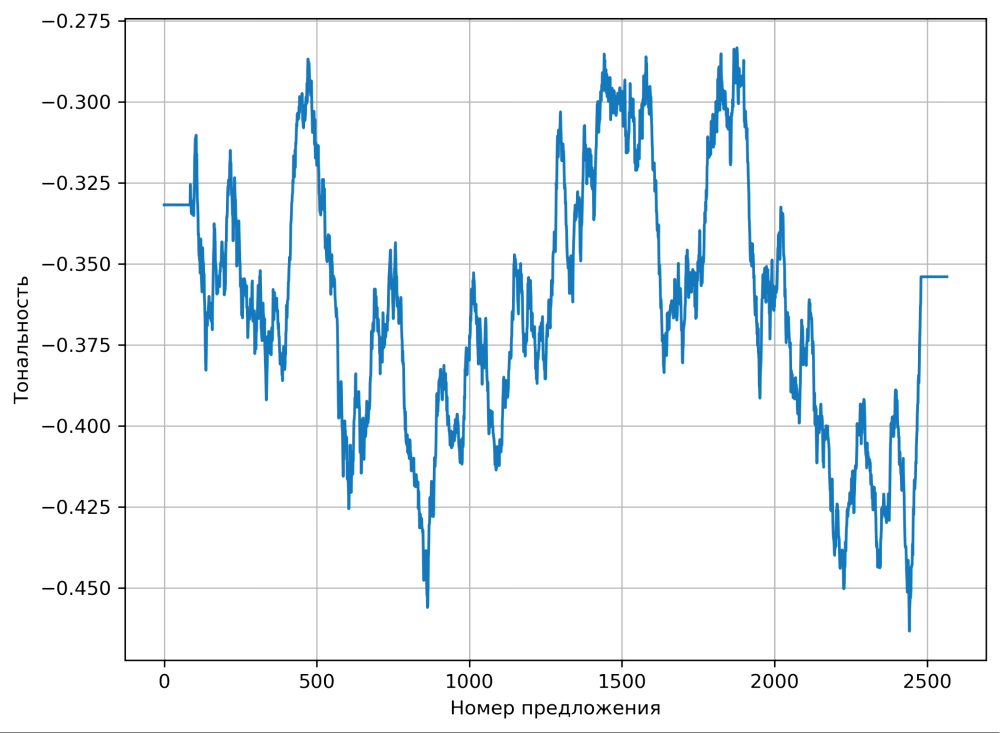
Отфильтрованная кривая эмоциональной тональности «Героя нашего времени»
Вот! Так гораздо лучше. В целом, можно остановиться и на этом, но есть одна небольшая проблема. У фильтра Савицкого-Голея есть параметр window_size, который отвечает за размер окна сглаживания. Выбранное нами по умолчанию значение даёт хорошую картинку, но результаты использования фильтра во многом зависят от выбранного размера окна.
Малые окна сглаживают высокочастотный шум, устраняя мелкие флуктуации, а большие окна сглаживают более крупные колебания и тренды сигнала, оставляя только общие тенденции его поведения. Как найти баланс между размерами окна?
Чтобы получить более гладкую кривую, учитывающую основные тренды исходного графика, можно использовать ансамблевый фильтр. Для этого нужно параллельно обработать зашумлённую кривую несколькими фильтрами Савицкого-Голея с различными размером окна, после чего усреднить результаты всех фильтров. Предполагается, что наиболее значимые изгибы зашумленной кривой тональности окажутся наиболее устойчивыми к сглаживанию большинства фильтров, поэтому будут отражены в окончательном результате.
Напишем функцию для работы ансамблевого фильтра:
# Ансамблевый фильтр
def ensemble_filter(data: list, n_filters=100, polyorder=0, **savgol_args) -> list:
"""
Применяет ансамблевый фильтр к входным данным
Parameters:
data (list): входной массив данных
n_filters (int, optional): число фильтров участвующих в сглаживании
"""
filt = 0
start = len(data)//10
stop = len(data)//4
step = (stop-start)//n_filters
if step == 0:
step = 1
# Варьируем размер окна и усредняем результат
for window_size in range(start, stop, step):
res = savgol_filter(data, window_length=window_size, polyorder=polyorder, **savgol_args)
filt += res
return filt/n_filtersПостроим график ещё раз:
# Произведем фильтрацию сигнала ансамблевым фильтром
filtered_sentiments = ensemble_filter(sentiments, polyorder=0)
# Построим график кривой эмоциональной тональности
plt.figure(figsize=(8, 6), dpi=300)
plt.plot(filtered_sentiments)
plt.xlabel('Номер предложения')
plt.ylabel('Тональность')
plt.grid()Полученный результат выглядит более привлекательно. Можно даже отметить ключевые точки развития сюжета, которые будут соответствовать пикам кривой:
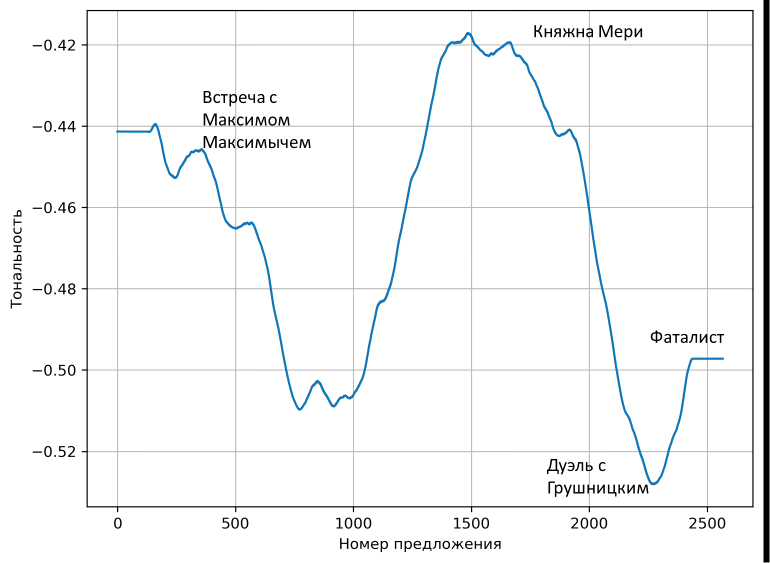
Кривая эмоциональной тональности «Героя нашего времени» после использования ансамблевого фильтра
Как использовать?
Теперь можно искать расстояния между кривыми анализа тональности или кластеризовать их, как сделал это Рейган и его коллеги, получив шесть типовых сюжетов литературы с точки зрения тональности текстов.
Кривые анализа тональности текстов можно использовать для контент-анализа, скачивая посты из социальных сетей или переписки из мессенджеров, датируя их и наблюдая за тем, как меняется тональность сообщений, постов или новостей в зависимости от общественных событий, изменений в экономике или политике.
Становится ли русская литература в целом более жизнерадостной или, наоборот, депрессивной? Каково усреднённое эмоциональное содержание классического русскоязычного текста? Отличается ли оно от текста на английском или французском?
Стали ли ваши сообщения в переписке с другом более жизнерадостными? Каковы кривые тональности ваших взаимоотношений, если судить по сообщениям из Telegram или «ВКонтакте»? Какие события и каким образом сказываются на кривой тональности новостей?
Теперь вы сами можете ответить на эти вопросы!
Источник: Andrew J. Reagan et al. The emotional arcs of stories are dominated by six basic shapes // EPJ Data Science. 2016. T. 5. № 1. С. 1–12.

