
«Мы убиваем людей, основываясь на метаданных» — генерал Майкл Хейден, бывший директор АНБ, 2014 г.
Что такое метаданные? — Когда речь идет о текстовом сообщении или звонке, под метаданными понимается точное время коммуникации, имя отправителя и получателя сообщения, их географические положения и вообще любые сведения, кроме непосредственно содержания письма или звонка. Спецслужбы собирают метаданные огромного числа людей и делают всевозможные выводы на их основе. А как найти шпиона по метаданным среди 20 000 корреспондентов архива писем эпохи Тюдоров, если вам лень читать архив вручную?
Чем опасны метаданные: историки против спецслужб
5 июня 2013 газета Guardian опубликовала материал от Эдварда Сноудена, рассказавшего о слежке за гражданами США со стороны Агентства национальной безопасности. АНБ собирало метаданные электронных писем и телефонных звонков оператора Verizon. Потом выяснилось, что сведения поступали в спецслужбу в рамках масштабной программы под названием Prism, позволяющей Агентству через следить за цифровой активностью зарубежных целей, сотрудничая с девятью крупными интернет-компаниями.
АНБ отвергло обвинения в нарушении Четвертой поправки к Конституции США, сославшись на разницу между данными и метаданными: непосредственно содержание звонков, электронных писем и прочих сообщений якобы оставалось в секрете. Вспомнили постановление Верховного Суда от 1979 года, подтвердившее, что государство имеет право записывать имена корреспондентов, точное время и дату коммуникации в интернете или по телефону, а также геолокацию сторон. Майк Помпео, успевший побывать главой ЦРУ при Дональде Трампе, заявлял, что «Конгрессу следует принять закон, вновь разрешающий сбор всех видов метаданных и их слияние с данными об образе жизни и финансах в единую базу, по которой можно проводить поиск».
Не слишком понятно, из-за чего беспокоиться. Что именно, в конце-концов, могут раскрыть о вас метаданные? Так вот, статья Рута Анерта и Себастьяна Э. Анерта «Метаданные, слежка и эпоха Тюдоров» в History Workshop Journal направлена как раз на то, чтобы показать на примере архива государственной и частной переписки Англии XVI-XVII вв, какие глубокие выводы можно сделать, применив простые методы сетевого анализа к историческим письмам.
Анализ архива позволяет предсказать паттерны в коммуникации людей и выявить аномалии, сделать предположения о лицах, состоящих в заговорах или собирающих разведданные. Стоит помнить, что приведенный опыт является лишь тенью возможностей современных спецслужб, а значит, предостерегает и предупреждает о том, что может случиться с метаданнными, что мы ежедневно генерируем.
Не-чтение
Основой исследования послужил архив бумаг главного королевского секретаря (что-то вроде современного министра иностранных дел). В числе документов — письма, договоры, доклады, прошения, меморандумы, судебные решения, международные соглашения и посольские донесения.
Исследователи рассматривали только письма: уникальных писем в архиве нашлось 132 747 штук. Авторы столкнулись со множеством проблем: некоторые письма были разбросаны по частным коллекциям, другие утеряны, третьи — скопированы и учтены несколько раз. Фонд State Papers Online проделал большую работу по оцифровке документов, снабдив каждое письмо метаданными по типу использованных АНБ, а именно: имя отправителя, имя получателя, дата составления, адрес составления, ID документа и описание содержания.
Похоже, что при создании фонда предполагалось, что исследователи станут пользоваться им как аналоговым, то есть искать отдельные письма по имени получателя или дате отправления. На деле оказалось, что вычислительные методы позволяют исследовать подобные массивы данных целиком. Подходы к таким исследованиям называются по-разному: «макроанализом», «дальним чтением» или «культурной аналитикой». Суть одна и та же: вместо ручного чтения материала можно обработать его численно.
Подобный подход выглядит очень привлекательно, если вы работаете с огромными массивами данных. Так что когда АНБ говорило, что не читает электронные письма американцев, это было не столько из опасения нарушить Четвертую поправку, сколько из необходимости как-то рационально работать с миллиардами сообщений. Писем в архиве State Papers Online, конечно, не миллиарды, но прочитать их вручную у одного исследователя на полном рабочем дне заняло бы примерно 16 лет. Это если не учитывать праздники, неразборчивый почерк или трудности чтения писем на иностранном языке. К тому же прочтение столь большого архива неизбежно сгенерировало бы новые данные (соображения исследователя), которые нужно было бы куда-нибудь записать (и совершенно непонятно, как их структурировать и исследовать). В общем, наш метод — «не-чтение».
Чтобы «не-прочитать» весь архив, исследователи сперва при помощи XML-файлов отделили письма от других видов сообщений, выбрав только те, где были заполнены поля «автор» и «получатель». Здесь тоже были свои трудности. Многие адресаты появлялись под несколькими именами, в течение жизни накапливая титулы. Другие имели несколько вариантов написания имени, третьи — просто множество тезок. Потребовалась кропотливая ручная работа (восемнадцать месяцев), чтобы разобрать, кто есть кто. Чтобы представить: изначальный архив содержал 37 101 уникальное имя корреспондентов, в процессе выяснилось, что на самом деле переписывалось только 20 656 человек.
Зато после «очистки» архива стало возможным применить к нему методы сетевого анализа, похожие на те, что АНБ проделывает с данными мобильников. На самом деле не только письма или мобильные телефоны могут стать объектом подобного исследования. Авторы работы отмечают, что в 90-х и 2000-х годах ряд исследователей писал о возможности сетевого анализа любой структуры, сводимой к метаданным ее элементов: нейронные сети, транспортные сети, регуляторные биологические сети или социальные сети обладают схожей внутренней структурой, а потому могут быть рассмотрены с помощью одних и тех же математических инструментов. В данном случае анализ архива позволит выявить не только особенности поведения отдельных корреспондентов, но и особенности составления выборки, то есть исторических перекосов в сборе и хранении писем — в конце-концов архив королевского секретаря несет на себе отпечаток личности его владельца.
Погодите. Что вообще такое сетевой анализ?
Если коротко — построение графа и его рассмотрение. Граф — это система взаимосвязанных точек. Чтобы проанализировать архив писем, не читая его, мы ставим точку на бумаге, (этой точкой был автор письма), ставим другую точку, (это был получатель), и проводим между ними линию, потому что один отправил другому сообщение. Получился простейший граф из двух узлов и одной связи. Потом рисуем точки еще для ста человек, соединяем линиями всех, кто писал друг другу письма, и начинаем смотреть, какие точки получились самыми «центральными», то есть через кого проходило больше всего информации. Теория графов — это хорошо изученная область математики, поэтому тут для всего есть специальные названия, и некоторые мы расшифруем:
- Узлом графа называется некая единица сети, в нашем случае — корреспондент
- Ребро: связь между единицами, в данном случае ребро означает отправленное письмо
- Степень: количество ребер у данного узла, то есть количество людей, которые получали или отправляли письма данному человеку
- Промежуточность: мера инфраструктурной важности узла. Между любыми двумя узлами сети существует кратчайший путь, и промежуточность показывает, сколько таких путей пролегает через конкретный узел. Центры коммуникации и «мосты» обладают высокой степенью промежуточности
- Центральность собственного вектора: мера, определяющая близость узла к важному узлу сети
Итак, получившийся граф имеет 20656 узлов (то есть уникальных корреспондентов) и 37087 связей (каждая связь — это одно или несколько писем). Можно измерить степень каждого узла. Так, во время правления Генриха VIII наибольшая степень узла — у Томаса Кромвеля, королевского секретаря и казначея. Он переписывался с 2149 людьми. Следом идет король (с ним переписывались 1134 человека), затем кардинал Томас Уолси (682 связи). Поскольку архив принадлежал королевскому секретарю, неудивительно, что большая часть писем принадлежала ему. Удивительно, что из 5785 корреспондентов эпохи Генриха только 17 человек имеют более ста разных связей, и только 127 — более двадцати. 5225 человек имеют менее пяти связей, а 3937 — лишь одну. Среди людей с единственной связью — мелкие администраторы или податчики петиций, обычно писавшие королевскому секретарю с какой-либо просьбой.
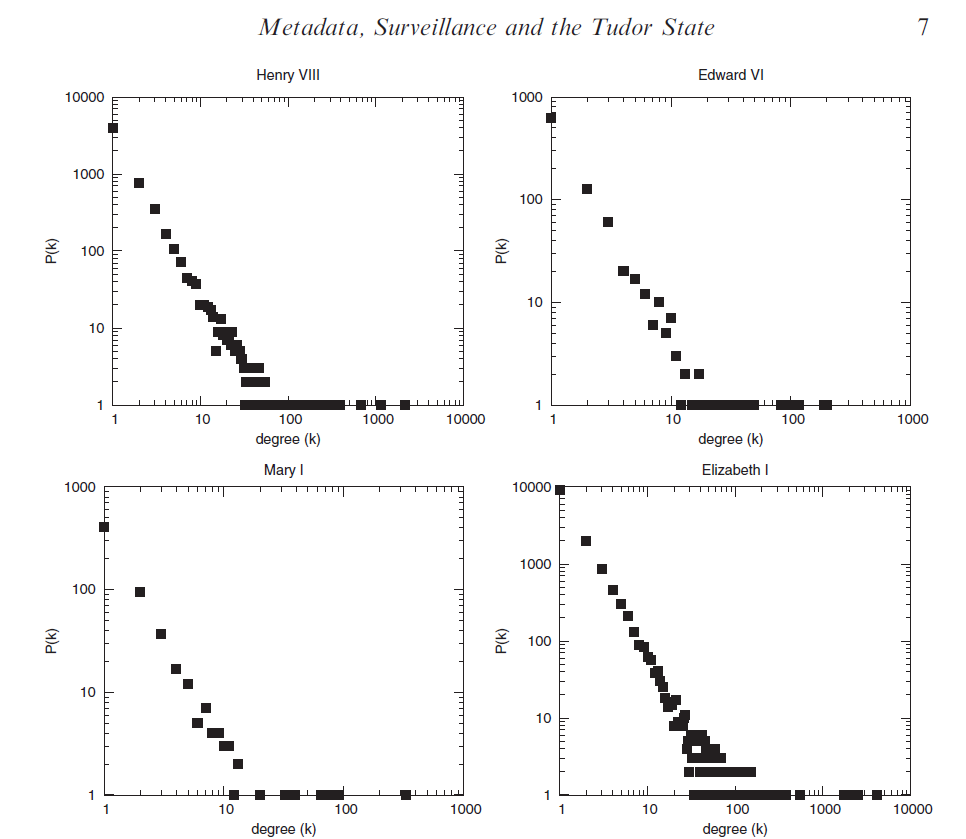
Если нанести степени всех корреспондентов эпохи Генриха VIII на график, мы увидим, что распределение степеней очень неравномерно. Чтобы поместить данные на одну картинку, исследователи сделали координатные оси неравномерными, то есть цена одного деления каждый раз умножается на десять. На такой оси график выглядит диагональной линией с несколькими хорошо соединенными «островками», или «хабами». Распределение, которое мы видим на картинке, называется степенным, потому что для любой точки верно, что существует в N раз меньше точек, у которых в M раз больше связей. При этом N — это число M, которое возвели в некоторую степень. К примеру, если М возводили в квадрат, то для любой точки верно, что существует в четыре раза меньше точек, у которых в два раза больше связей, или в девять раз меньше точек, у которых в три раза больше связей.
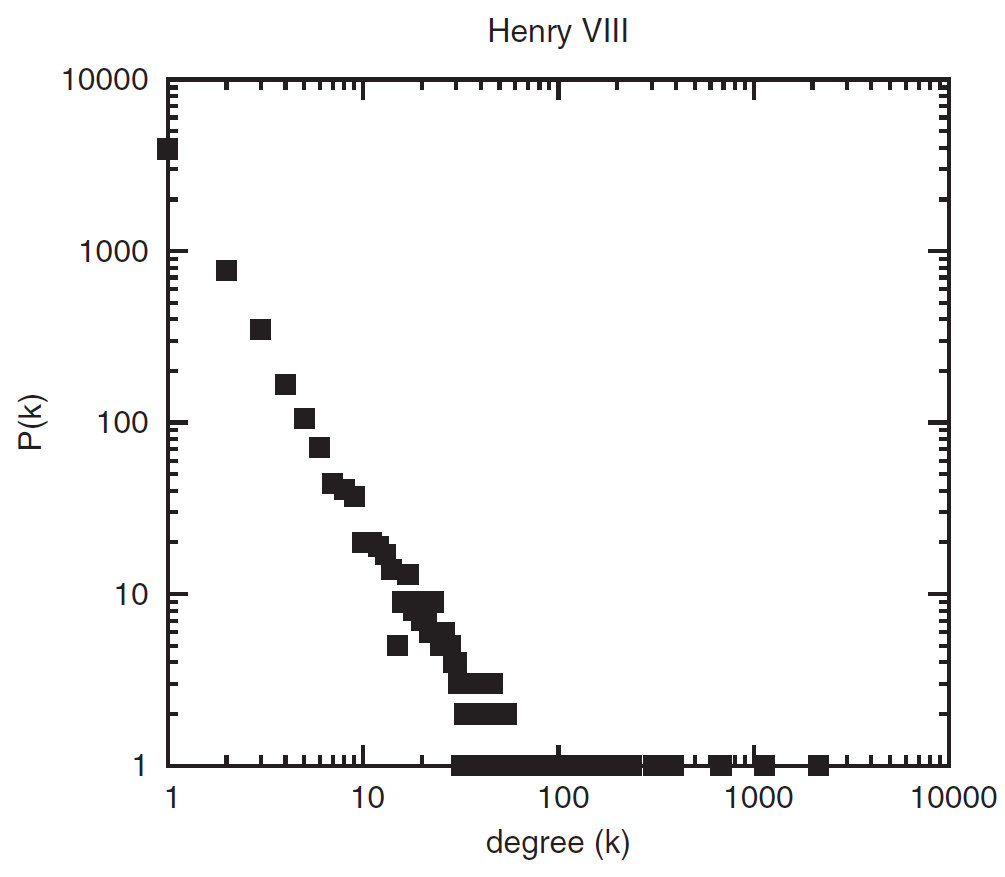
Такое распределение характерно не только для архива с письмами: очень многие сети подчиняются ему. Довольно здорово, что паттерн появляется не только во время правления Генриха, но справедлив также для периодов правления Эдуарда VI, Марии I и Елизаветы I. Даже с учетом того, что объемы дошедших до нас писем и число корреспондентов в каждом случае разное.
Давайте уже к интересному. Как ловить шпионов?
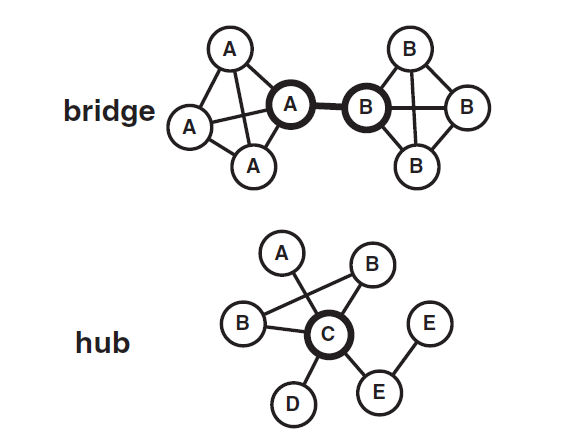
Чтобы найти аномалии в поведении корреспондентов, авторы статьи построили другой график, где степень узла ставится в зависимость от его промежуточности (betweenness). Бывает два типа узлов с высокой промежуточностью: так называемые «хабы» и так называемые «мосты», оба типа показаны на картинке ниже. Через такие узлы проходит много кратчайших путей между другими узлами.
Оказалось, что если ранжировать узлы по промежуточности от первого, «самого промежуточного» (в нижней части вертикальной оси) до последнего, можно нарисовать график, показанный на картинке снизу. (Горизонтальная ось показывает степень узла)
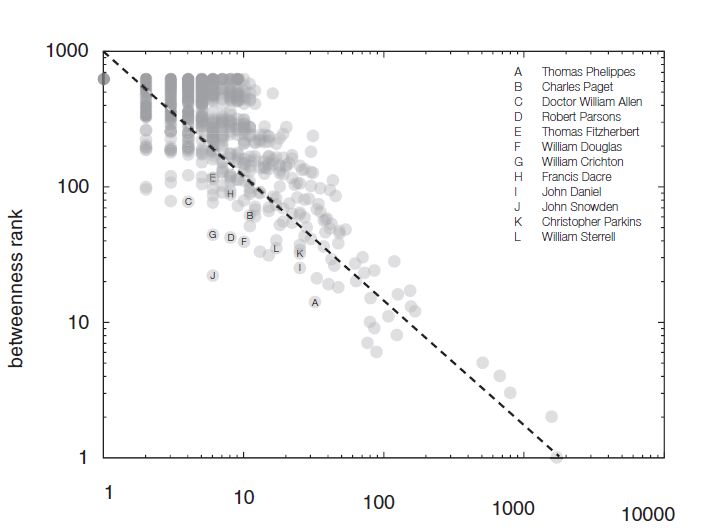
На графике можно провести линию, тренд, вдоль которого обычно располагаются точки. Иными словами, обычно можно предсказать промежуточность узла, зная его степень. И вот тут начинается самое интересное: существует ряд точек, чья промежуточность значительно выше, чем должна быть при данной степени. Эти точки лежат ниже линии тренда, и они как раз отмечены буквами на графике, каждая буква соответствует одной исторической личности. Если пересказывать кратко, они все были заговорщиками, собирали разведданные или как-то шпионили за короной. Среди попавших в этот список лиц — миссионеры, священники, дипломаты и послы. Совсем коротко: шпионов выдало то, что через них курсировала информация от слишком большого числа людей.
Авторы не останавливаются на достигнутом и показывают еще более интересный прием: если собрать у каждого узла сети ряд параметров, среди которых степень, промежуточность, количество исходящих и входящих писем, близость к важным узлам сети, и скомпилировать их в некий «общий счет» при помощи нейросети, то можно предсказывать узлы с похожим счетом! Похожий счёт при этом получится у людей, занимавшихся похожим делом, то есть, зная параметры узла одного священника, можно найти кластер священников, зная параметры узла дипломата — других дипломатов, что важнее — зная параметры узла одного заговорщика — можно вскрыть всю его преступную сеть. Метод работает не идеально и требует ручной проверки, но в целом дает интересные результаты, которые авторы разбирают на примерах конкретных исторических фигур.
Например, часть статьи посвящена увлекательной истории Джона Сноудена — двойного агента, параллельно работавшего на иезуитов, мечтавших о реставрации католицизма в Англии, и на противостоявшего им государственного секретаря. Сноудена выдала как раз необычно высокая промежуточность — в сочетании с небольшой степенью узла.
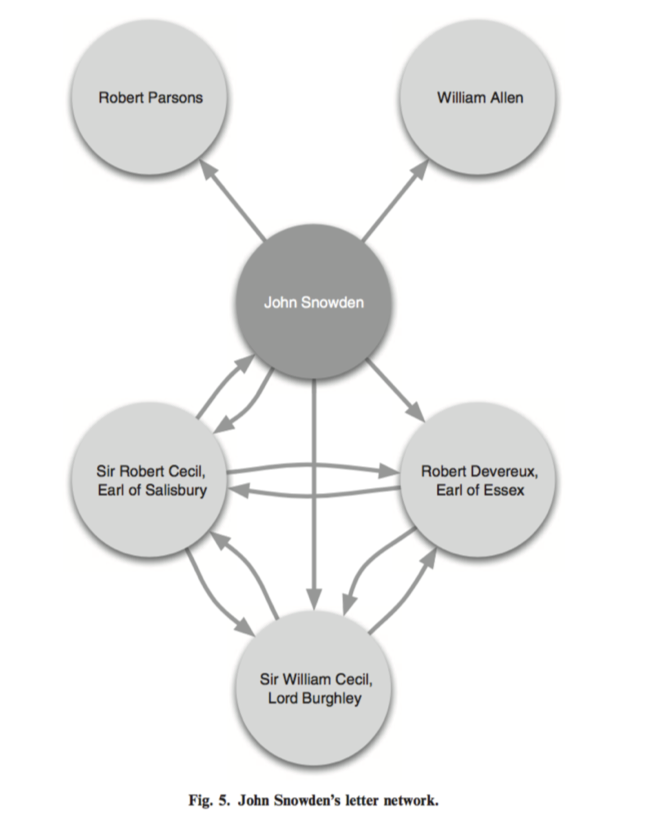
Наконец, заключительная часть статьи посвящена интересному наблюдению: исследуя кластеры узлов с похожим набором параметров, авторы задались вопросом о пути, которым письма попали в архив. Выяснилось, что сравнивая сумму параметров узлов и их удаленность от центральных фигур архива, то есть короля и его секретаря, можно найти кластеры перехваченных писем. Перехваченные письма, или письма людей, за которыми была установлена слежка, группируются в «хабы», мало связанные с другими участками сети. Так государственная слежка оставляет след в истории: теперь на основе набора метаданных можно ретроспективно предположить, чьими делами интересовался королевский двор. Свою находку авторы называют «слежкой за слежкой».
Интересно бывает узнать, какие возможности открываются для массового наблюдения, даже когда само содержание сообщений остается для наблюдателей в секрете. Авторы статьи подчеркивают, что она носит лишь иллюстративный характер, и их методики являются не больше чем малой частью возможностей современных спецслужб. Предсказательные техники наверняка ушли далеко вперёд, и теперь не составляет труда оценить степень угрозы от человека, зная, сколько раз и с кем он контактировал. Единственное, что остаётся неясным в таких вопросах — к кому в руки попадает эта информация и как она будет использована.
Источник: Metadata, Surveillance and the Tudor State


