
Невыученный урок
Ричард Саттон, признанный учёный в области искусственного интеллекта (ИИ), в 2019 г. опубликовал статью под названием Bitter lesson («Горький урок»). В ней он проанализировал историю развития интеллектуальных систем и назвал главную ошибку, которую из раза в раз совершают ИИ-разработчики. Он подчеркнул, что долгосрочный прогресс в сфере ИИ обычно достигался не теми методами, которые были основаны на попытках смоделировать в компьютере человеческие представления о мире, а теми методами, которые опирались на рост вычислительных мощностей и увеличение доступных вычислительных ресурсов (ярким примером таких методов являются нейросети, которые требуют огромного объёма компьютерных ресурсов).

Как думает человек? Понимание механизмов человеческого мышления и восприятия, в частности, понимание того, как люди решают сложные задачи — различают лица, играют в шахматы или переводят с одного языка на другой — несовершенно. Поэтому и методы, основанные на этих неполных знаниях, так же или даже более несовершенны. Они приводят к быстрым результатам, поэтому их часто применяют. Однако долгосрочная цель — разработка таких методов, при помощи которых ИИ совершит прорыв, а не будет использовать уже существующие знания.
Для подтверждения своего тезиса автор приводит ряд примеров из прошлого.
Поиск перебором и обучение
Первый пример: в 1997 году компьютер Deep Blue победил в шахматах гроссмейстера. Deep Blue играл с помощью brute force поиска — поиска оптимального шага путём перебора большого количества вариантов. Компьютер оценивал 200 миллионов ходов в секунду, что требовало огромного количества вычислений. Тогда такой подход вызвал большое недовольство: исследователи стремились разработать методы, основанные на человеческом понимании игры. А когда более простой метод доказал свою эффективность, сторонники внедрения человеческих знаний в компьютер заявили, что, несмотря на победу, такой подход не является общей стратегией, так как не похож на то, как люди играют в шахматы.
Подобная история повторилась в 2016 году с го — игрой, более сложной с точки зрения количества комбинаций. Однако в этот раз для победы компьютера помимо перебора комбинаций был также использован механизм обучения (имеется в виду машинного обучения). Первая версия программы, играющей в го, была обучена на партиях лучших игроков, однако вторая версия обучалась посредством игры с самой собой, выучивая функцию ценности. Функция ценности — это математическая функция, которая принимает на вход текущее состояния игры и ход, а на выходе возвращает ценность данного хода при данном состоянии игры.

Ещё один пример, подкрепляющий тезис Саттона, — использование статистических методов. В 1970-х годах в области распознавания речи был проведён конкурс, спонсируемый DARPA (Управление перспективных исследовательских проектов Министерства обороны США, которое внесло большой вклад в изобретение интернета). В конкурсе участвовало множество методов, использующих человеческие знания — знания о словах, фонемах, голосовом тракте и т. д. Также присутствовали и новые методы, опирающиеся на статистический подход и требующие гораздо больше вычислений. Эти новые методы снова одержали верх над методами, основанными на человеческих представлениях о задаче. Статистический подход также начал распространяться и в других сферах: в NLP (Word2Vec, рекуррентные нейросети и трансформеры) и в компьютерном зрении (появление свёрточных нейронных сетей, которое произвело революцию в области).
Из всех этих примеров Саттон выделяет два класса методов, которые позволяют использовать постоянно растущие вычислительные возможности: массивный перебор и обучение. Появление более мощных и эффективных вычислителей позволяет производить перебор большего количества вариантов за меньшее время и обучать бо́льшие модели на более объёмных выборках данных (то есть использовать статистический подход).
Взгляд из настоящего
В конце мая 2023 года капитализация (рыночная стоимость) компании Nvidia достигла отметки в 1 триллион долларов. Подорожание акций компании произошло на фоне роста популярности больших языковых моделей (в частности нашумевшего ChatGPT), для обучения и работы которых необходимы видеокарты, производимые Nvidia.
Видеокарты Nvidia ещё в начале 2000-x гг. сыграли одну из ключевых ролей в развитии машинного обучения, позволив в разы ускорить обучение нейросетей. Стремительный рост вычислительных мощностей и их доступности позволяет обучать всё более и более большие модели на более и более больших выборках, что положительно влияет на качество моделей. Для наглядности: за последние три года количество параметров языковой модели GPT выросло с 120 миллионов до почти 2 триллионов, за счёт чего GPT научилась решать широкий спектр самых разных задач без какого-либо дообучения.
Утверждения Саттона подтвердились и в области компьютерного зрения. С 2020 года свёрточные сети уступают первенство модели Vision Transformer (ViT), которая является адаптацией архитектуры трансформера для работы с изображениями и использует меньше человеческих знаний об устройстве зрения. Однако для обучения ViT требуется больше вычислений и больше данных.
Хватит ли данных?
Итак, для повышения качества моделей важны не только вычисления, но и данные, на которых обучают модель. В случае вычислений существует закон Мура, который описывает, с какой скоростью растёт количество транзисторов, а вот для данных нет общепринятых законов, которые описывали бы динамику роста их объёма.
В 2022 году вышла статья, в которой авторы попытались смоделировать то, как будет расти общее количество данных (текстов и изображений), доступных в интернете, и объёмы данных, которые будут использованы для обучения.
Для текстовых данных авторы построили отдельные модели для данных низкого качества (данные с форумов, блогов и т. д.) и высокого качества (статьи Википедии, новостные материалы, github, книги и научные публикации). В обучении больших языковых моделей более важны данные высокого качества.
На объёмы генерируемых людьми данных низкого качества, согласно статье, влияют следующие факторы:
- размер популяции;
- доля людей, у которых есть доступ к интернету;
- среднее количество контента (измеряемое в словах/изображениях), которое производит пользователь.
Для моделирования количества данных высокого качества в случае сильно модерируемых ресурсов вроде Википедии и новостных сайтов использовалась та же модель, что и для данных низкого качества, однако для моделирования количества книг и научных статей использовались экономические показатели, например, доля ВВП, которая выделяется на исследования.
Определить качество визуальных данных сложно, поэтому для изображений была использована модель, похожая на модель для текстовых данных низкого качества.
В итоге авторы пришли к следующим выводам:
- общее количество текстовых данных низкого качества (на 2022 г.) лежит в диапазоне от 6.9e13 до 7.1e16 слов. Темп ежегодного роста этого типа данных составляет от 6.41% до 17.49%. 1e14 слов могут быть доступны одному крупному актору вроде Google; 1e15 слов суммарно доступны всем крупных технокомпаниям; 1e16 слов могут быть коллективно собраны всем человечеством, если записывать все сообщения, звонки, видеовстречи;
- общее количество текстовых данных высокого качества лежит в диапазоне от 4.6e12 до 1.7e13 слов. Ежегодно количество этих данных растёт на 4–5%;
- общее количество изображений — от 8.11e12 до 2.13e13. Число изображений растёт примерно на 8% каждый год.
Прогнозы: что ждёт ИИ в будущем?
Растут не только объёмы данных, но и размеры обучающих выборок.
В статье были представлены два вида прогнозов размеров обучающих выборок: прогноз на основе исторических данных и прогноз на основе количества доступных вычислительных ресурсов. Второй тип необходим, поскольку увеличение объёма обучающих данных для той или иной модели требует дополнительных вычислений, а объём вычислений, который может быть использован, ограничен. Так, например, в какой-то момент будут доступны выборки определённого объёма, однако не будет достаточно вычислительных ресурсов для их использования. Или наоборот — вычислительных ресурсов будет достаточно, а данных нет.
И для текстовых, и для визуальных данных тенденции роста обучающих выборок похожи: размеры выборок будут стремительно расти вплоть до момента исчерпания общего запаса данных. После этого темп роста стремительно уменьшается. Также важно отметить, что количество использованных данных для обучения растёт куда быстрее, чем общее количество данных.
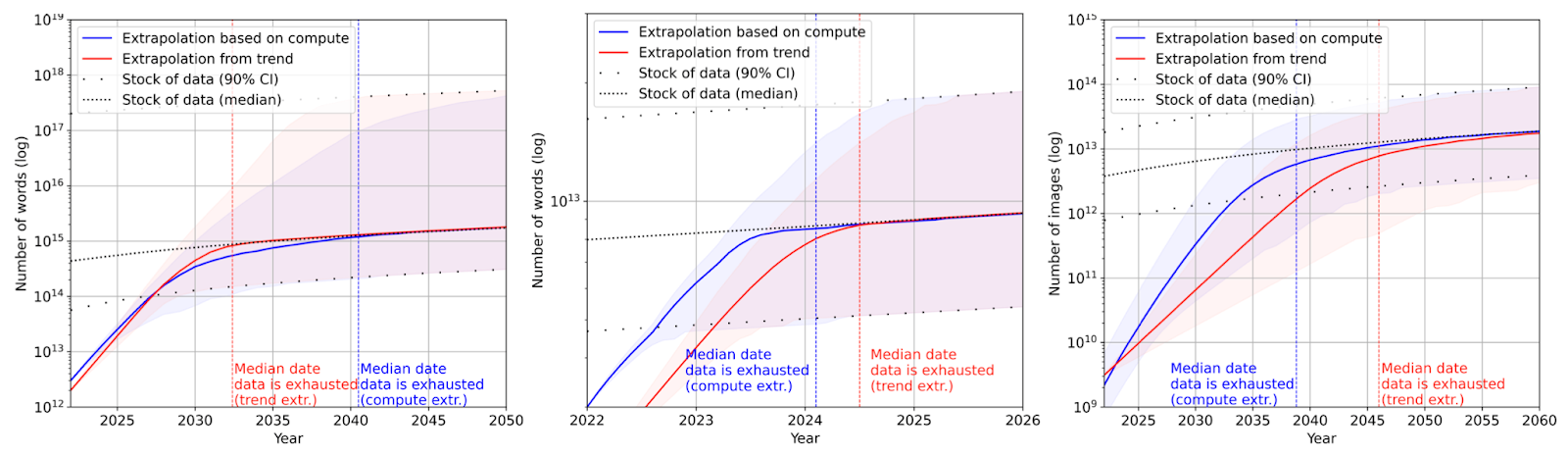
Пунктирная кривая — прогноз на общее количество доступных данных. Красная кривая — прогноз на основе исторических данных. Синяя линия — прогноз с учётом количества доступных вычислительных ресурсов
В случае текстовых данных высокого качества авторы прогнозируют, что при сохранении текущих трендов общий запас этих данных исчерпается до 2027 года. Для текстовых данных низкого качества и визуальных данных прогнозы менее точные: исчерпание общих запасов произойдёт до 2030, либо после 2060 года.
Значит ли этого, что нехватка данных в скором будущем помешает развитию ИИ? Скорее всего нет, так как прогнозы, представленные в статье, основаны на множестве показателей и трендов, динамика которых может поменяться. Возможно также появление принципиально нового источника данных — например, VR и AR устройств. Также не стоит исключать, что в будущем в сфере машинного обучения появятся более эффективные с точки зрения обучающих данных методы и модели.
Источники
- Sutton R. The Bitter Lesson
- Villalobos P., et al. Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning, 2022. https://doi.org/10.48550/arXiv.2211.04325

