
Завершаем наш цикл о нейросетевых языковых моделях рассказом о GPT-3 — самой продвинутой на сегодняшний день нейросети. Она умеет сочинять стихи и прозу, разгадывать анаграммы, переводить, отвечать на вопросы по прочитанному тексту. Для лучшего понимания статьи рекомендуем прочитать наши материалы об устройстве нейросетей-трансформеров:
Как обучали GPT-3
Людям обычно не требуется обучение на большом наборе данных с разными параметрами для ответа на вопросы типа: «пожалуйста, скажите мне, описывает ли это предложение что-то счастливое или что-то грустное» или «здесь два примера того, как люди ведут себя смело; приведите третий пример смелого поступка». Человеку достаточного краткого указания, о чем речь.
Так происходит потому, что мозг обучался много лет до того и обладает большим набором универсальных коммуникационных и логических навыков. Сотрудники лаборатории Open AI предложили применять схожий метод для адаптации предобученной языковой модели к конкретной задаче: на вход модели подается краткое описание задачи, определяется условие на естественном языке и приводится несколько примеров. Модель, ранее уже предобученная на огромном корпусе текстов, должна выполнить следующие задачи, предсказав, что будет дальше.
Такой способ обучения позволяет обойти ограничения, связанные с необходимостью собирать большие наборы данных, чтобы донастроить предобученную модель для выполнения конкретной задачи.
Предполагая, что «контекстное обучение» с увеличением масштабов языковой модели может привести к значительным результатам в решении языковых задач, Open AI обучили модель авторегрессии с 175 миллиардами параметров, назвав ее GPT-3 [2], и оценили ее возможности при использовании «контекстного обучения». Качество модели GPT-3 оценивали на двух десятках наборов данных NLP, а также на нескольких новых задачах, отличающихся от задач из обучающего набора, чтобы понять, насколько модель адаптировалась к новым заданиям. В рамках «контекстного обучения» GPT-3 для каждой задачи применялось три вида настроек: «обучение в несколько приемов» («Few-Shot learning»), «однократное обучение» («One-Shot learning») и «нулевое» («Zero-Shot»). Эти методы явились прорывом в языковом моделировании, т. к. это не обучение модели с нуля, а дообучение, которое требует значительно меньше времени и ресурсов.
Расскажем о каждом из них подробнее.
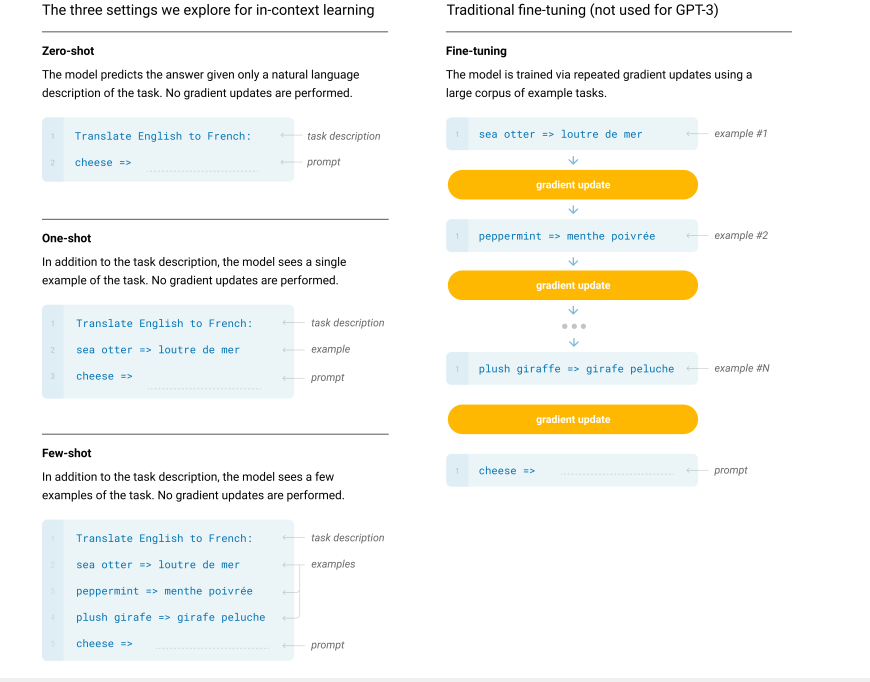
тонкой настройке
Few-Shot (FS): на вход предобученной модели подается описание задачи на естественном языке и несколько примеров ожидаемых результатов.
Примеры обычно представляют собой контекст и ожидаемое завершение контекста (решение поставленной задачи). К примеру, для перевода с английского на французский примером является предложение на английском и его перевод на французский. Модель принимает K примеров контекста и его завершения, а затем задается контекст, для которого модель должна выдать аналогичный результат.
Обычно K берется в диапазоне от 10 до 100, так как именно это количество примеров может поместиться в контекстном окне модели (это количество токенов, используемых в качестве контекста для текущего токена, nctx = 2048). Одно из главных достоинств метода FS — при его использовании уже не нужны большие наборы для обучения конкретной задаче и для тонкой настройки на большом узкоспециализированном наборе данных. Главный же недостаток — результаты этого метода намного хуже современных моделей с тонкой настройкой.
One-Shot (1S) очень похож на Few-Shot, но при использовании этого метода допускается лишь один пример в дополнение к описанию задачи на естественном языке.
Zero-Shot (0S) аналогичен (1S), за исключением того, что демонстрации не допускаются, а модель получает лишь инструкцию на естественном языке, без каких-либо примеров.
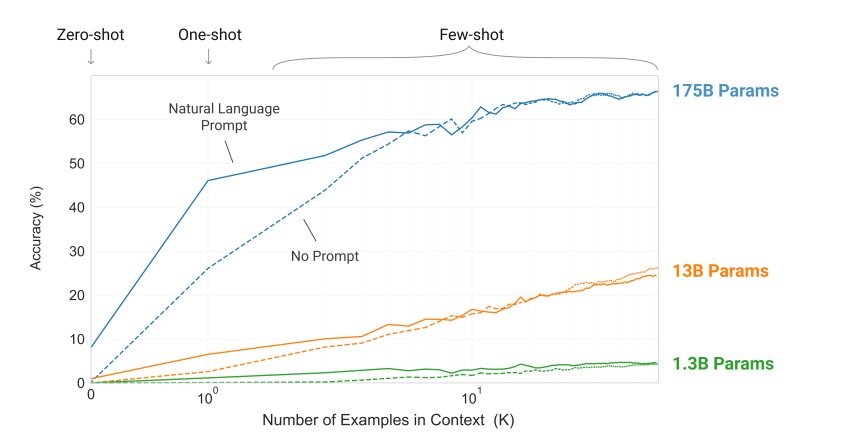
На рис. 2 показано сравнение применяемых методов для задачи удаления лишних символов из слова. Производительность модели улучшается с добавлением описания задачи на естественном языке, а также с увеличением количества примеров. Результаты обучения методом FS также значительно улучшаются с увеличением размера модели. Хотя результаты в этом случае особенно поразительны, общие тенденции, касающиеся как размера модели, так и количества примеров в контексте, справедливы для большинства изучаемых задач.
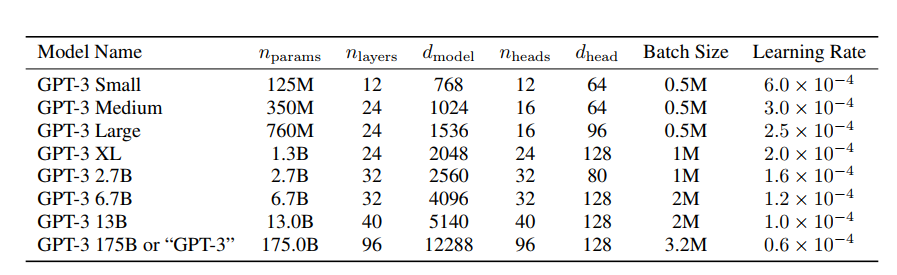
Архитектура модели GPT −3
GPT-3 имеет ту же архитектуру, что и GPT-2 (как устроена GPT-2, мы рассказывали в этой статье), за исключением того, что в GPT-3 в слоях трансформера чередуются блоки с разреженным и полным механизмами внимания. Чтобы оценить, насколько производительность модели зависит от ее размера, разработчики обучили 8 различных по размерам моделей: от 125 миллионов параметров до 175 миллиардов параметров (последняя из них и есть GPT-3). В таблице 1 приведены размеры и архитектура 8 моделей. nparams — это общее количество обучаемых параметров, nlayers — общее количество слоев, dmodel — количество единиц в bottleneck слое (это слой, в котором меньше нейронов, чем в предыдущем, что заставляет нейросеть понижать размерность и делать признаки более компактными. В каждой модели есть feedforward слой, в котором сигнал распространяется строго от входного слоя к выходному, он в четыре раза больше bottleneck слоя (dff = 4 ∗ dmodel), а dhead — это размер каждой головы внимания. Все модели используют контекстное окно, nctx = 2048 токенов.
Обучающие данные
Размеры модели значительно увеличились за счет набора данных Common Crawl — это веб-архив, собранный с 2011 года и состоящий из почти триллиона слов. Чтобы улучшить среднее качество наборов данных, разработчики сделали следующее:
- отфильтровали версию CommonCrawl на основе сходства с рядом высококачественных эталонных корпусов;
- выполнили нечеткую дедубликацию на уровне документа (внутри) и между наборами данных, чтобы предотвратить избыточность и сохранить целостность валидационного набора данных, применяемого для оценки переобучения;
- для разнообразия добавили известные высококачественные эталонные корпуса в набор тренировочных данных: WebText, содержащий тексты с сайтов, страницы которых были отмечены пользователями, как полезные по контенту; корпуса книг Books1 и Books2; англоязычную Википедию.
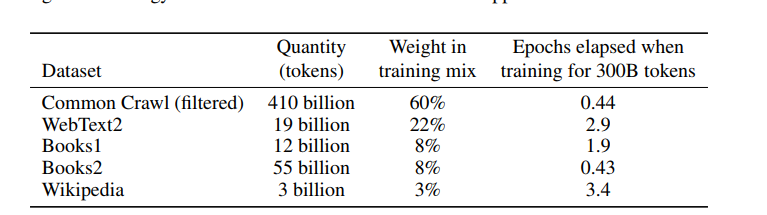
Во время обучения наборы данных отбирались не пропорционально их размеру. Более качественные наборы выбирались чаще, так что наборы данных Common Crawl и Books2 выбирались менее одного раза во время обучения, а другие наборы данных отбирались по 2–3 раза.
Результаты
1. LAMBADA
Набор данных LAMBADA применяется для тестирования того, как языковые модели способны улавливать смысловые цепочки в длинных текстах. Модель должна предсказать последнее слово в предложении на основе контекста параграфа. Zero-Shot подход для GPT-3 достигает точности в 76% на LAMBADA, это на 8% лучше в сравнении с предыдущим результатом state-of-the-art (SOTA результат, высшая точка развития технологии на данный момент).
Применение Few-Shot для набора LAMBADA позволяет решить классическую проблему, связанную с этим набором данных. Дополнением контекста в LAMBADA всегда является последнее слово в предложении, но стандартная языковая модель не может знать об этом. Few-Shot позволяет языковой модели сделать из примеров вывод о том, что желательно завершать предложение ровно одним словом. Open AI использовали следующий формат при определении задачи заполнения пропусков в предложениях:

GPT-3 совместно с заданными таким образом примерами достигает 86,4% точности, что на 18% больше предыдущего SOTA результата. Производительность GPT-3 с использованием Few-Shot настройки растет с увеличением масштаба модели. Заполнение пропусков не эффективно при настройках One-Shot, даже в сравнении с Zero-Shot. Возможно — из-за того, что модели все еще требуют нескольких примеров, чтобы распознать шаблон.
2. Машинный перевод
Несмотря на то, что GPT-3 в основном обучался на английских текстах (93% по количеству слов), он также включает 7% текста на других языках, в том числе на французском. Чтобы лучше понять возможности перевода, разработчики Open AI включили еще два дополнительных языка: немецкий и румынский. Существующие unsupervised подходы (обучение без учителя) машинного перевода часто представляют собой обучение на одноязычных наборах данных с применением обратного перевода (back-translation) для надлежащего связывания двух языков. GPT-3 же учится на наборе обучающих данных, которые естественным образом содержат в себе несколько языков, объединяя их на уровне слов, предложений и документов.
В таблице 3 приведено сравнение качества переводов различных моделей. GPT-3 с применением Zero-Shot (модель получала лишь описание задачи на естественном языке) уступает по качеству перевода предыдущим unsupervised Neural Machine Translation результатам. Но при добавлении одного или нескольких примеров (One-Shot или Few-Shot настройки) для каждой задачи качество перевода приближается к SOTA результатам.
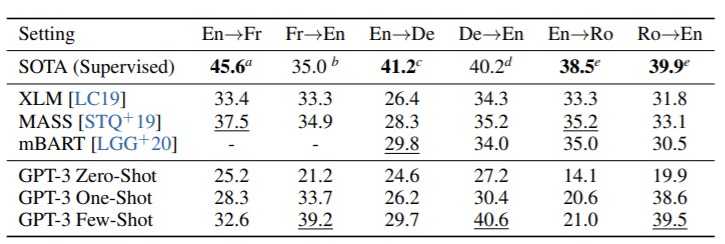
Для всех трех приведенных языков GPT-3 значительно превосходит предыдущие unsupervised модели (XLM, MASS, mBART) при переводе на английский. Однако при переводе в обратном направлении GPT-3 уступает предшественникам.
3. Winograd-Style Tasks
Задача Winograd Schemas Challenge — классическая задача в автоматической обработке языка, в ходе которой нужно определить, к какому из слов относится местоимение, когда местоимение неоднозначно грамматически, но семантически однозначно для человека. Например, во фразе «кошка не влезла в коробку, она слишком большая/маленькая» в зависимости от выбора прилагательного меняется антецедент местоимения «она»: если большая, то кошка, а если маленькая, то коробка. Чтобы сделать верный выбор, надо опираться на семантику фразы. Такие задачи придумал ученый Терри Виноград, в честь него и назвали Winograd Challenge.
Тонко настроенные языковые модели недавно достигли производительности, близкой к человеческой, на наборе данных Winograd. Но они по-прежнему значительно отстают на более сложном наборе данных Winogrande. При тестировании на наборе Winograd GPT-3 показал точность 88,3%, 89,7% и 88,6% с применением Zero-Shot, One-Shot и Few-Shot настроек соответственно. Применение «контекстного обучения» для этой задачи не дало ярких результатов, но тем не менее полученные значения всего на несколько пунктов ниже SOTA результатов (90,1%).
Целесообразность применения «контекстного обучения» была более заметна на наборе данных Winogrande: GPT-3 показал точность 70,2%, 73,2%, 77,7% при Zero-Shot, One-Shot и Few-Shot настройках соответственно. Для сравнения, тонко настроенная модель RoBERTA (улучшенная версия BERT) достигает точности 79%. SOTA результат равен 84,6%, и получен с помощью тонкой настройки модели большой емкости (T5). Точность человека при выполнении этой задачи составляет 94,0%.
4. Здравый смысл и знания о мире
Была протестирована возможность моделей улавливать физические или научные смыслы. Для этого рассматривались три набора данных. Первый набор, PhysicalQA (PIQA), задает вопросы об устройстве мира с точки зрения физики, и предназначен для проверки понимания доказанных фактов о мире. На данном наборе GPT-3 показал точность 81,0% 80,5% и 82,8% при Zero-Shot, One-Shot и Few-Shot настройках соответственно, что выгодно отличается от 79,4%, полученных с помощью тонкой настройки модели RoBERTa.
Второй набор данных, AI2 Reasoning Challenge Dataset [13], представляет собой набор вопросов с несколькими вариантами ответов, собранных на экзаменах по естественным наукам с 3 по 9 классы. На «Challenge» версии этого набора, состоящей из вопросов, на которые невозможно ответить с помощью простого информационного поиска, GPT-3 достиг точности 51,4%, 53,2% и 51,5% при Zero-Shot, One-Shot и Few-Shot настройках соответственно. Полученный результат близок к бейслайну (точке отсчета) тонко настроенной модели RoBERTa (55,9%) из UnifiedQA [14]. На «Easy» версии рассматриваемого набора данных GPT-3 показал точность 68,8%, 71,2% и 70,1%, что немного превышает бейслайн тонко настроенной модели RoBERTa. Однако все результаты по-прежнему хуже, чем SOTA.
На третьем множестве OpenBookQA GPT-3 также близок к базовым результатам, но 20 пунктов ниже SOTA результатов.
5. Понимание прочитанного
Также GPT-3 оценивали на понимание прочитанного. Для этого использовали 5 наборов данных с различными форматами заданий — в виде диалога или одного вопроса. GPT-3 показала широкий разброс в производительности на этих наборах данных, что указывает на разные возможности с разными форматами ответов. В основном GPT-3 находится на одном уровне с исходными бейслайнами.
GPT-3 работает лучше всего (в пределах 3 пунктов от исходного базового уровня для человека) на наборе CoQA, предполагающую свободную форму ответа.
Худшие результаты получены на наборе QuAC, значение F1 на 13 пунктов ниже бейслайна модели ELMo. Набор QuAC отличается тем, что требуется соблюдать некоторую структуру, отвечая на вопросы.
6. Арифметика
Чтобы протестировать способность GPT-3 выполнять простые арифметические операции без специальной подготовки, был разработан небольшой набор из 10 тестов, в каждом из которых модели GPT-3 ставится простая арифметическая задача на естественном языке.
Лучшие результаты GPT-3 показала с использованием Few-Shot настройки. GPT-3 достигла 100% точности при сложении двух цифр, 98,9% при двузначном вычитании, 80,2% при трехзначном сложении и 94,2% при трехзначном вычитании. Производительность снижается по мере того, как количество цифр увеличивается, на четырехзначных операциях точность равна 25–26% и 9–10% — на пятизначных операциях.
7. Генерация новостной статьи
В сравнении с GPT-2 модель GPT-3 менее эффективна при создании новостных статей. Причина в том, что при обучении GPT-3 использовалось пропорционально меньше текстов, связанных с новостными статьями. К примеру, GPT-3 часто интерпретирует предложенное первое предложение «новостной статьи» как твит, а затем генерирует либо ответы, либо последующие твиты. Чтобы решить эту проблему, использовалась настройка Few-Shot, в качестве примера модель получала три предыдущие новостные статьи. Выяснилось, что при задании заголовка статьи и нескольких примеров новостных материалов модель способна надежно генерировать короткие статьи в жанре «новости».
Чтобы увидеть, насколько текст, сгенерированный GPT-3 отличим от текста, написанного человеком, ученые выбрали 25 статей с сайта newser.com, их средняя длина составила 215 слов. На основе заголовков этих статей с помощью четырех языковых моделей размером от 125 миллионов до 175 миллиардов параметров были сгенерированы тексты длиной примерно 200 слов, из них некоторые были заведомо плохими. В эксперименте участвовало 80 человек, их попросили определить, была ли статья была написана человеком или машиной.
Средняя человеческая точность (отношение правильно выбранных к не нейтральным на участника) при обнаружении заведомо плохой статьи составила ~ 86%, где 50% — вероятность попадания плохой статьи в выборку. В то же время точность обнаружения статей, созданных с помощью модели с параметрами 175B, была едва выше вероятности попадания таких статей в выборку ~ 52%. Способность человека отличать текст, созданный моделью, от написанного человеком уменьшается по мере увеличения размера модели.
GPT-3, в отличие от GPT-2, не находится в открытом доступе. Разработчики заявляют, что боятся использования модели во вред обществу, например, для создания фальшивых новостей (fake news). Однако здесь могут быть и чисто коммерческие причины: вскоре после выхода модели OpenAI заключили с Microsoft контракт на эксклюзивный доступ к GPT-3.
Источники:
- Unified Language Model Pre-training for Natural Language Understanding and Generation.
- Language Models are Few-Shot Learners.
Дополнительные ссылки:
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
- Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation.
- Get To The Point: Summarization with Pointer-Generator Networks.
- A neural attention model for abstractive sentence summarization
- Language Models are Unsupervised Multitask Learners.
- Generating long sequences with sparse transformers.
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.
- Improving Neural Machine Translation Models with Monolingual Data.
- Hector Levesque, Ernest Davis, and Leora Morgenstern. The Winograd schema challenge. In Thirteenth International Conference on the Principles of Knowledge Representation and Reasoning, 2012.
- WinoGrande: An Adversarial Winograd Schema Challenge at Scale.
- Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge.
- UnifiedQA: Crossing Format Boundaries With a Single QA System.
