Это продолжение текста про трансформер, в котором мы разбирались, как работает энкодер и механизм «многоголового» внимания. Вот краткий пересказ:
- Каждое входное слово кодируем вектором (поможет word2vec, FastText, ELMo)
- Несколько векторов слов склеиваем во входную матрицу (одна строка — одно слово)
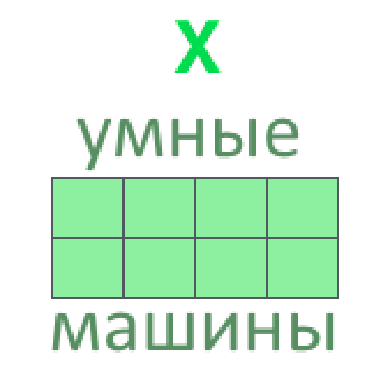
3. Из входной матрицы делаем три: Q, K, V (запрос, ключ, значение)
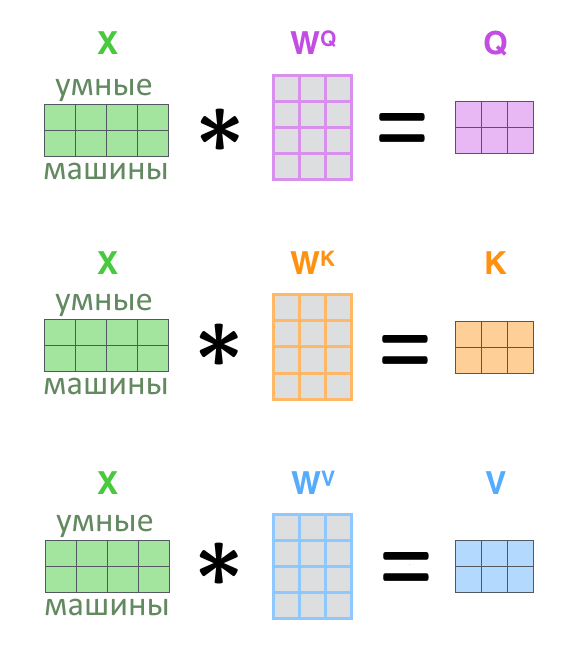
4. Задача внимания — найти, каким ключам K соответствует запрос Q и выдать соответствующие ключам значения V
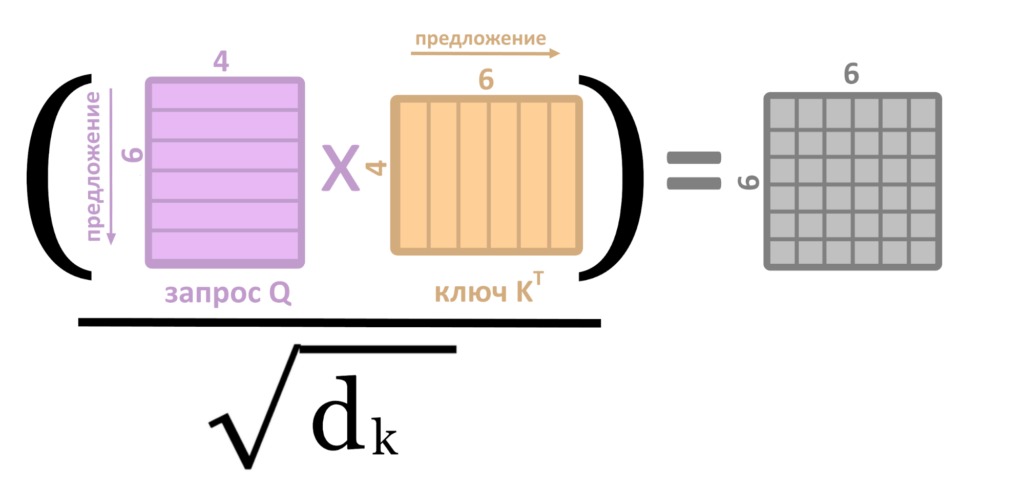
5. Для этого Q, K, V перемножаются по правилам из предыдущего текста, и выходит матрица Z, результат «головы внимания»
6. Для ускорения работы сети матрицы приходится сокращать (делить на квадратный корень длины ключа K)
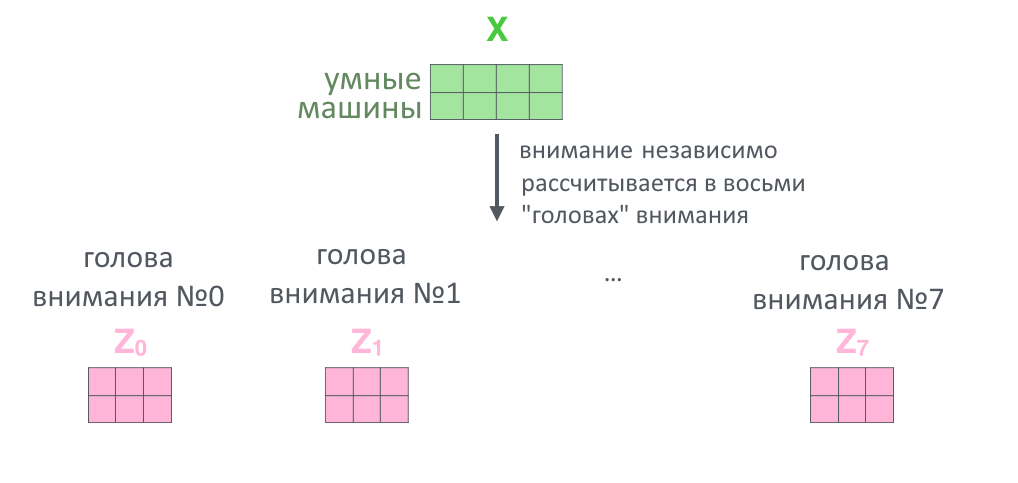
7. Вся история проделывается восемь раз параллельно с разными ключами, запросами и значениями (в начале работы их задают случайно): так внимание смотрит на разные смысловые «фишки» тех или иных слов
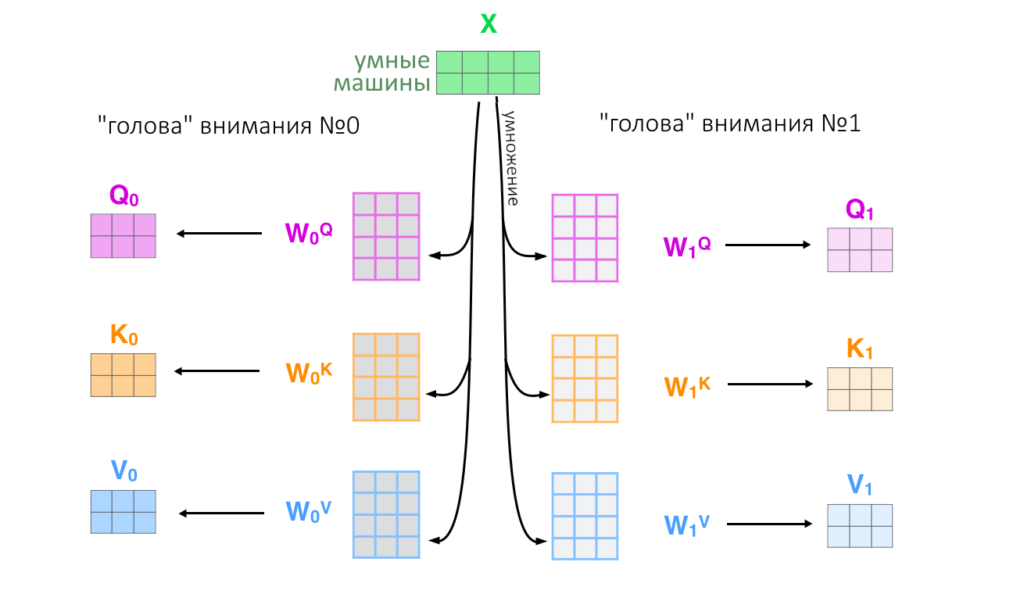
8. Восемь результатов Z(h), по одному от каждой «головы внимания h» склеиваются в большую матрицу, еще раз умножаются на матрицу весов
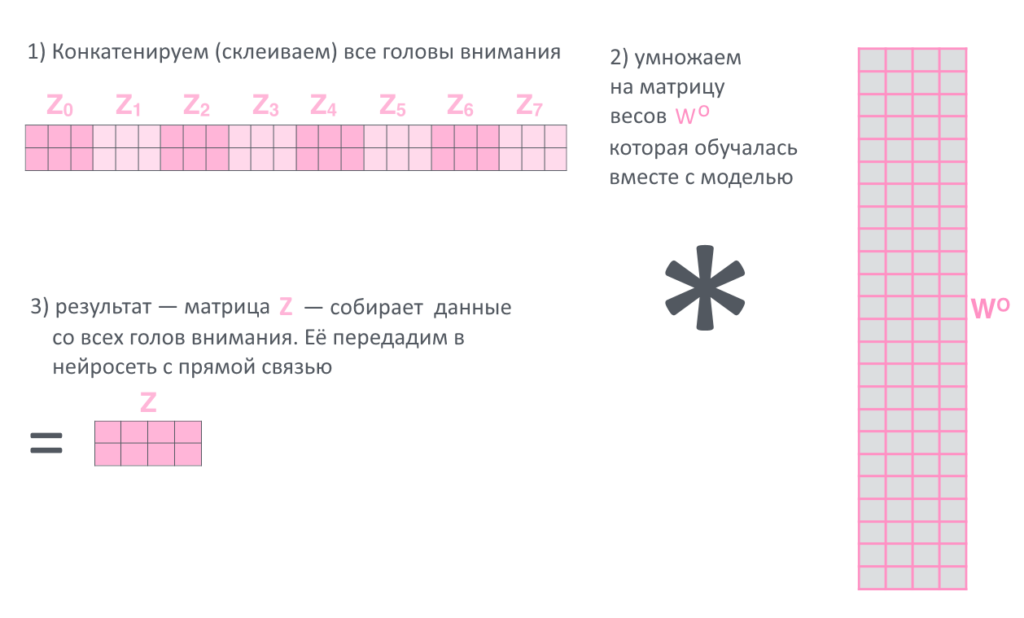
9. Всё. Финальное произведение назовём просто Z и посмотритм, что происходит с ним дальше.
Добавляем нормализацию
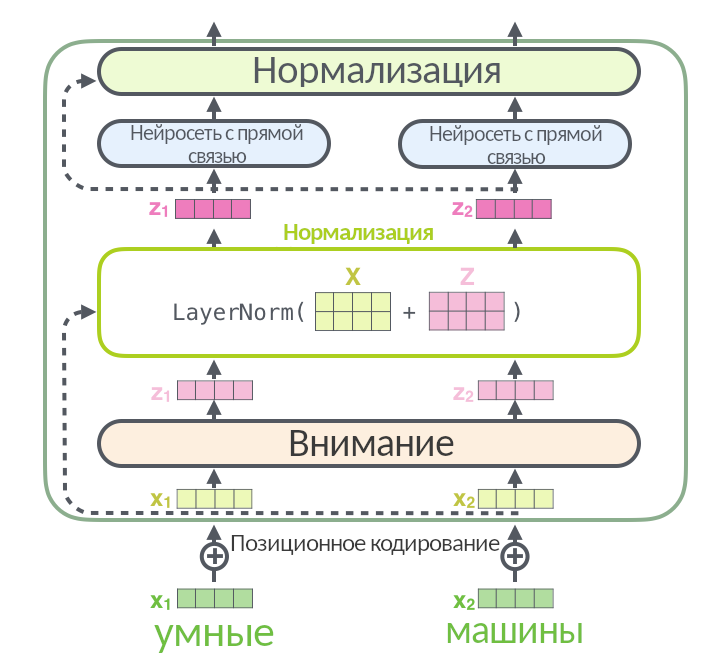
В прошлом тексте один слой энкодера выглядел так:
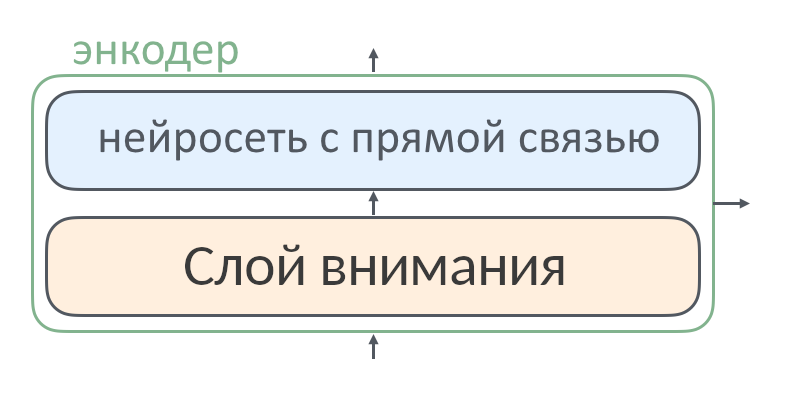
Это упрощенная схема, которую нужно дополнить, чтобы все было правильно:
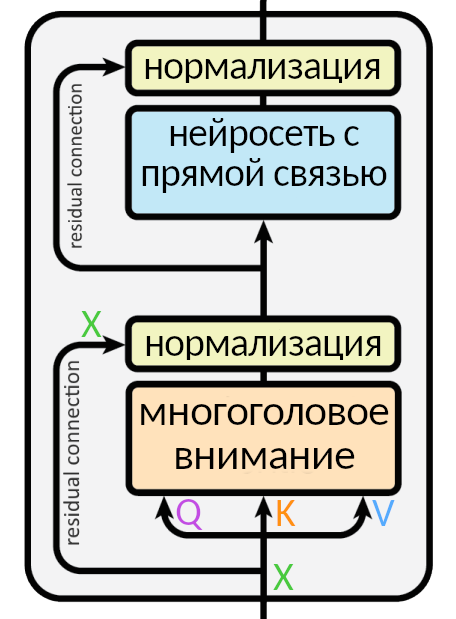
Так выглядит слой энкодера без упрощений. Входная матрица разбивается на три, (Q, K, V), проходит через внимание, а результат (мы называли его Z) складывается со входной матрицей X и нормализуется через функцию LayerNorm: эта операция помогает быстрее тренировать нейросеть.
Стрелка вокруг слоя внимания, ведущая к нормализации, называется residual connection, она есть в каждом слое энкодера и декодера. Она означает, что нормализуется не просто Z, а (Z + X). Нормализация появляется после каждого «внимания» и каждой нейросети с прямой связью и в энкодере, и в декодере.
Вот иллюстрация, заглядывающая в нормализацию поглубже:
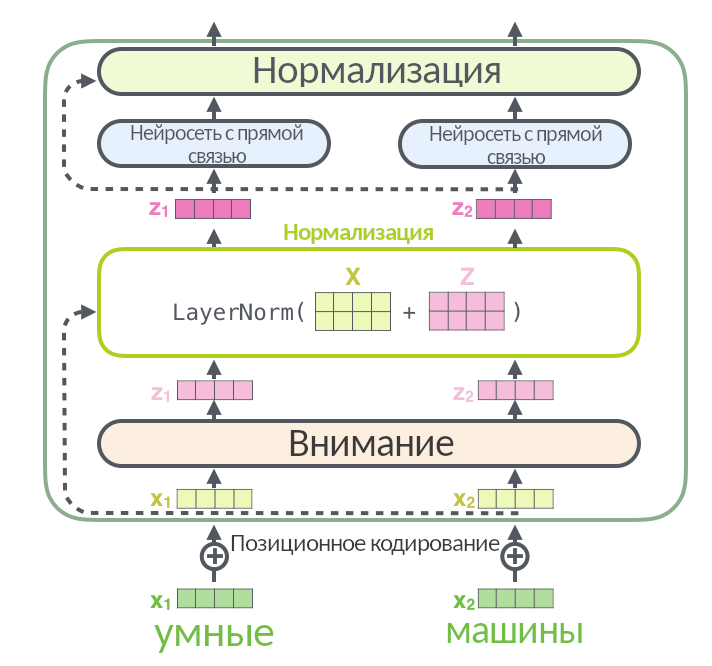
На картинке выше перед слоем энкодера добавился новый элемент — позиционное кодирование. Оно не входит в энкодер, а производится до него. Посмотрим, что это такое.
Позиционное кодирование
Если нейросеть принимает на вход слова целыми пачками (как трансформер и делает, склеивая отдельные слова в матрицы), теряется информация о том, что за чем идёт в предложении, какие слова друг от друга близко, а какие — далеко. Эта проблема решается позиционным кодированием.
В рекуррентной нейросети не надо никак отдельно кодировать позицию слова — они подаются друг за другом и обрабатываются по очереди. В трансформере нет рекуррентности, то есть нейросеть одновременно смотрит только на ту «стопку» слов, которую ей выдали, и не смотрит на свою предыдущую работу из прошлой «стопки».
Чтобы закодировать позицию слова, программисты взяли функции синуса и косинуса: они изменяются циклично и через конкретные промежутки. Можно выбрать несколько синусоид с разными периодами:
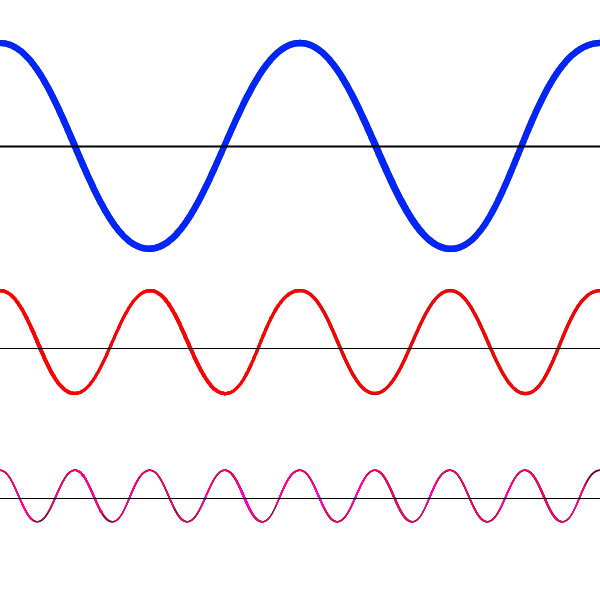
Поделим графики на вертикальные кусочки и закодируем положение каждого графика числом от −1 до 1. Каждому слову — свой столбик.
Соседние столбики будут иметь разные значения «быстрых» синусов или косинусов, но близкие значения «медленных». Если два слова стоят далеко друг от друга, их «медленные» графики будут в разных позициях.
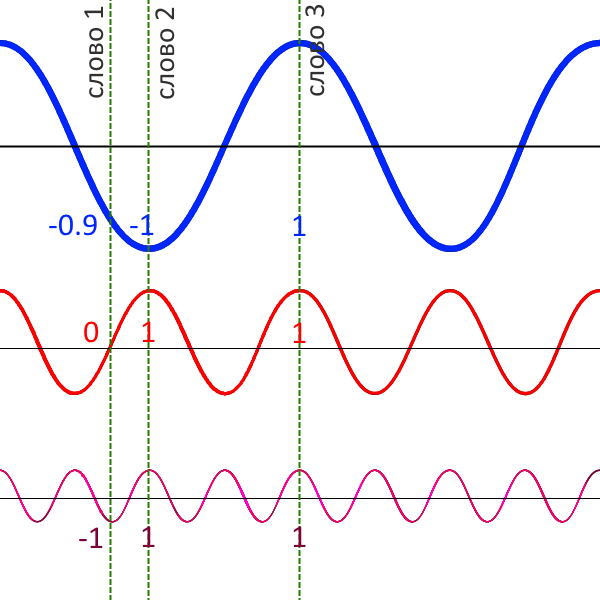
В столбце получился набор чисел, позиционный вектор. Позиционный вектор складывается с начальным вектором слова, в этом состоит суть позиционного кодирования.
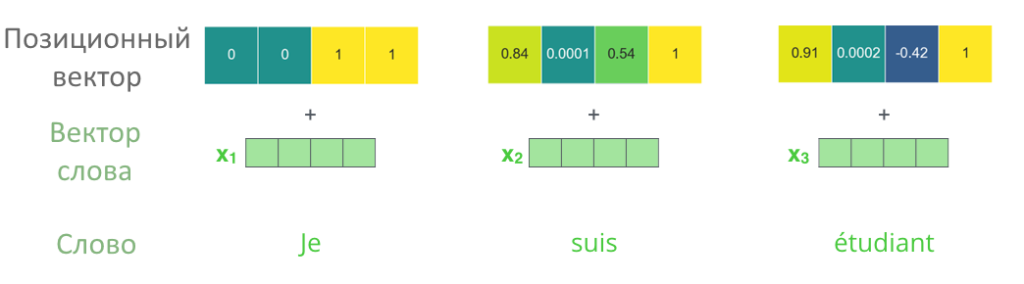
Позиционное кодирование выполняется только перед первым кодирующим слоем, когда вектора слов еще совсем «сырые». Когда энкодер передает вектора с первого на второй слой или со второго на третий, с ними ничего дополнительно не происходит.
Итого в одном слое энкодера «спрятаны» четыре отдельных части вот в таком порядке:
- Позиционное кодирование (перед самым первым слоем, поэтому нулевой номер)
- Многоголовое внимание на себя
- Нормализация
- Нейросеть с прямой связью
- Опять нормализация
Кодирующих слоёв — шесть. Они передают друг другу свой результат (матрицу) по цепочке. Только с результатом последнего, шестого слоя энкодера работает декодер.
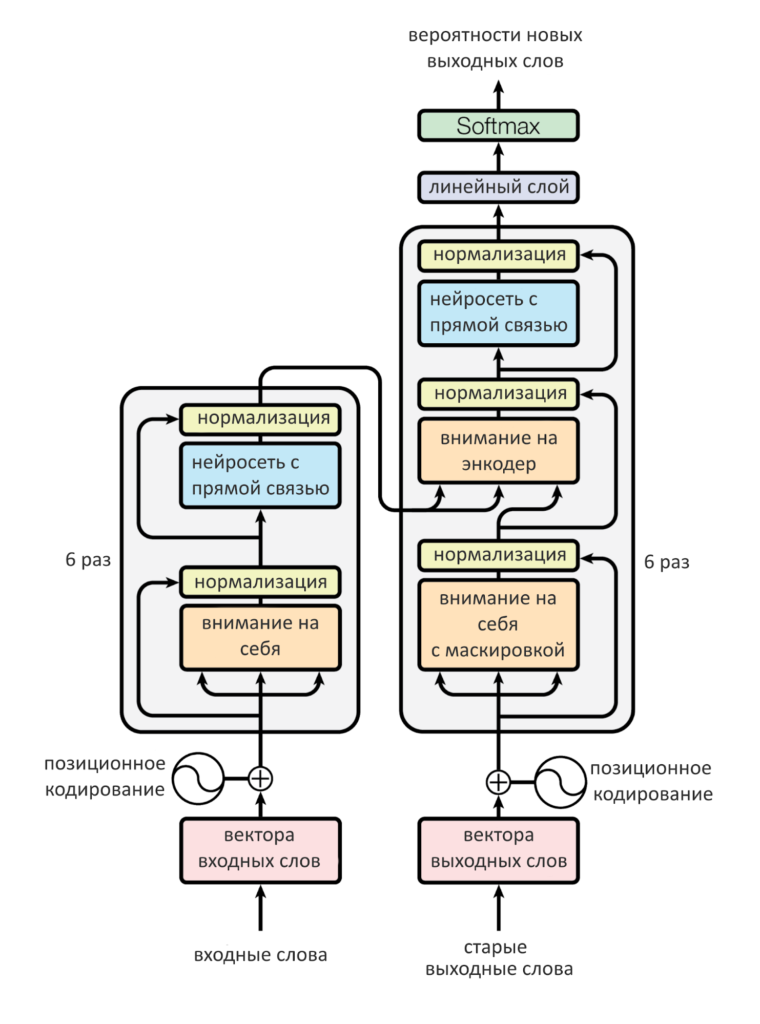
Декодирующая часть трансформера
Декодер в целом работает точно так же, как энкодер, но с небольшими различиями. Вот они:
- В слое декодера два слоя внимания: одно — на свою прошлую работу, («на себя»), другое — на энкодер
- Внимание декодера «на себя» смотрит на предыдущие слова в выходном предложении, маскируя все остальные (ведь они подаются одновременно, всей матрицей)
- Внимание «на энкодер» формирует свой запрос Q, а ключи K и значения V берет у энкодера
- Перед первым слоем декодера слова выходного предложения тоже позиционно кодируются
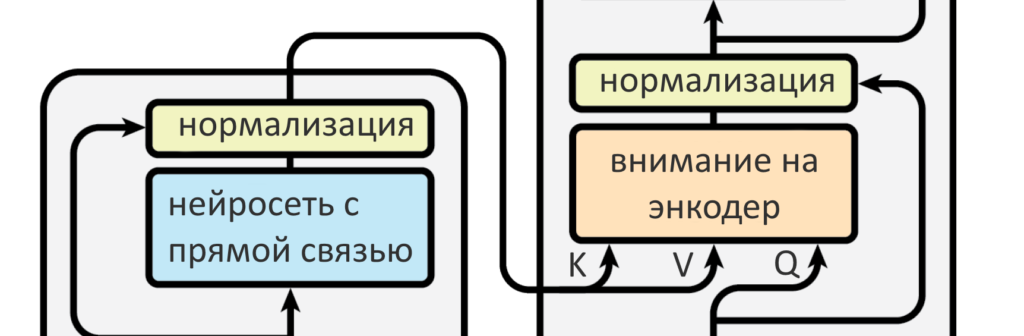
Чем отличается внимание «на себя» от внимания не на себя?
Напомним метафору с поиском видео на Ютубе. Запрос Q — это то, что интересует пользователя, то, что он написал в поисковой строке и что хочет найти. Ключи K — теги к каждому видео, они хранятся в базе данных Ютуба и по ним ведется поиск. Задача поиска — найти подходящие к запросу теги и выдать видео (значения V) с этими тегами.
Слои внимания энкодера были вниманием «на себя»: и запрос, и ключи, и значения они брали у самих себя из прошлого, то есть с прошлых слоев. Если слой первый — то прямо с входных слов (с позиционным кодированием).
В декодере два слоя внимания: один «на себя», другой — на энкодер. Тот, что «на себя» берет Q, K и V с уже сгенерированных декодером до него слов. Если это самый первый шаг и пока ничего не сгенерировано, он пропускается.
Внимание на энкодер генерирует собственный запрос Q, а вот ключ K и значения V берет у энкодера. В этом есть смысл: декодер ведет себя как пользователь, для которого матрицы энкодера — как база данных Ютуба или Гугла, где надо найти то, что его интересует. Стрелки от энкодера к декодеру показывают как раз передачу ключей и значений.
Что является результатом работы нейросети?
Если нейросеть работает с текстовой информацией, обычно она генерирует «наиболее вероятные» слова. Сгенерированные выходные слова могут быть переводом, продолжением истории или кратким пересказом, в зависимости от задачи, под которую тренируется нейросеть. Если хотите научить ее переводить — придется дать многоязычный корпус текста, где есть целая книжка и ее перевод. Нужно научить нейросеть краткому пересказу — придется найти корпус, в котором есть длинные истории, а следом их изложение. Нейросети без разницы, для чего генерируются вектора новых слов: они просто генерируются такими, какими наверное могли бы быть в обучающем корпусе.
Если обучающий корпус очень большой и разнообразный, нейросеть получится универсальной, но может давать не такие точные результаты, как «заточенная» на конкретную задачу модель. О том, как «заточить» нейросеть под нужную задачу и как измерить, хорошо ли она справляется, можно будет прочитать в тексте Системного Блока про предобучение и трансферное обучение.
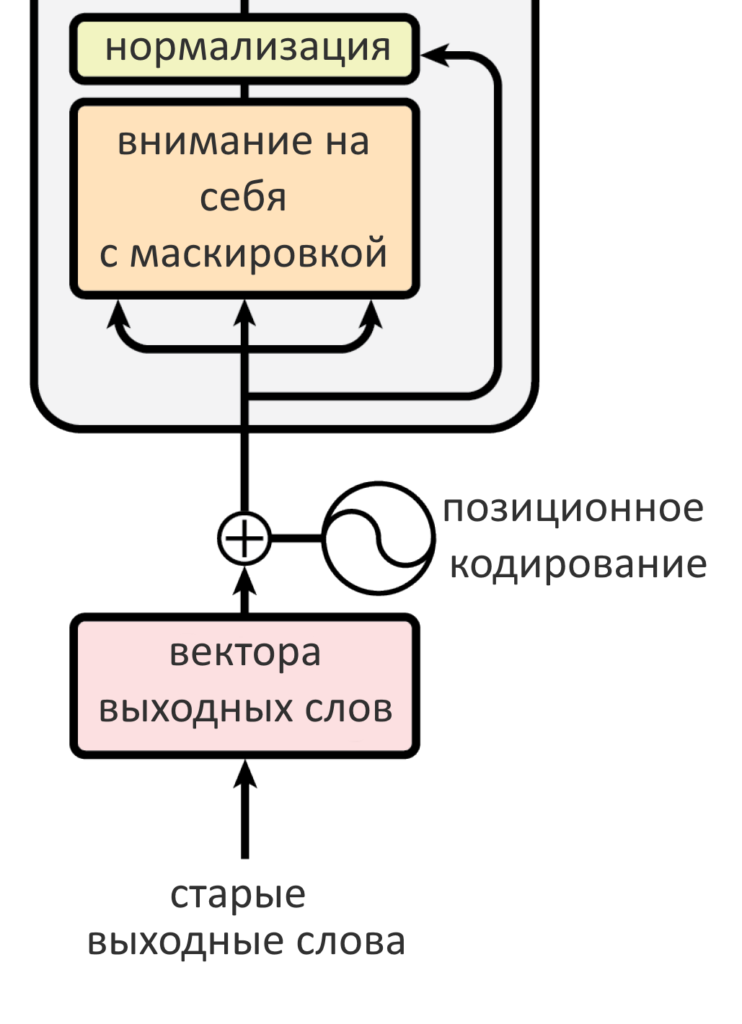
Что такое маскировка значений и зачем она нужна?
Если декодер уже успел что-нибудь сгенерировать, включается слой внимания декодера «на себя». Декодер генерирует по слову за раз, но мы знаем, что на входе трансформер не работает с одним словом и его вектором — вместо этого на вход энкодеру и декодеру подается по матрице, где спрятаны все слова входного предложения и все уже известные — выходного. Проблема в том, что эти матрицы — фиксированных размеров, а матрица декодера все время заполняется новыми значениями, ранее неизвестными. Если ее нельзя «растягивать» по мере необходимости (к сожалению, нельзя), приходится писать значения «-inf» на месте тех слов, которые еще не успели сгенерироваться. Это обеспечивает отсутствие у них веса внимания, а значит, модель «смотрит» только на работу энкодера и на предыдущий результат декодера. Запись «значений-болванок» на месте будущих слов и называется маскировкой.
Кстати, правильнее было бы говорить не «матрица», а «тензор»: нейросети работают именно с ними. Разница в том, что матрицу можно понять как двухмерную таблицу, а тензор уже как минимум трехмерен. Трехмерность тензора достигается из-за того, что одно слово кодируется последовательностью чисел, как бы строкой из них, одномерной бумажной ленточкой. Предложение кодируется уже перечнем таких строк, можно представить его как двухмерный лист книги, одна строка — одно слово. Если же нужно закодировать несколько предложений, и при этом не переносить предложения с листа на лист, придется выбрать длину листа (длину самого большого предложения) и записать каждое предложение на отдельном «листе» — в двухмерной матрице. Сложим их в стопочку — получится трехмерный тензор.
Причем здесь маскировка значений и тензоры? Маскировка нужна, чтобы заполнить чем-то пустое пространство в двумерных массивах, «листах», и обозначить, на какую часть листа обращать внимание, а на какую — нет. Так что она применяется не только в декодере, но и при подготовке порций входных данных (т.н. «батчей»).
После декодера
Мы знаем, что внутри декодера — два разных слоя внимания, а следом — нейросеть с прямой связью, она выдает набор чисел. Как превратить этот набор обратно в слово?
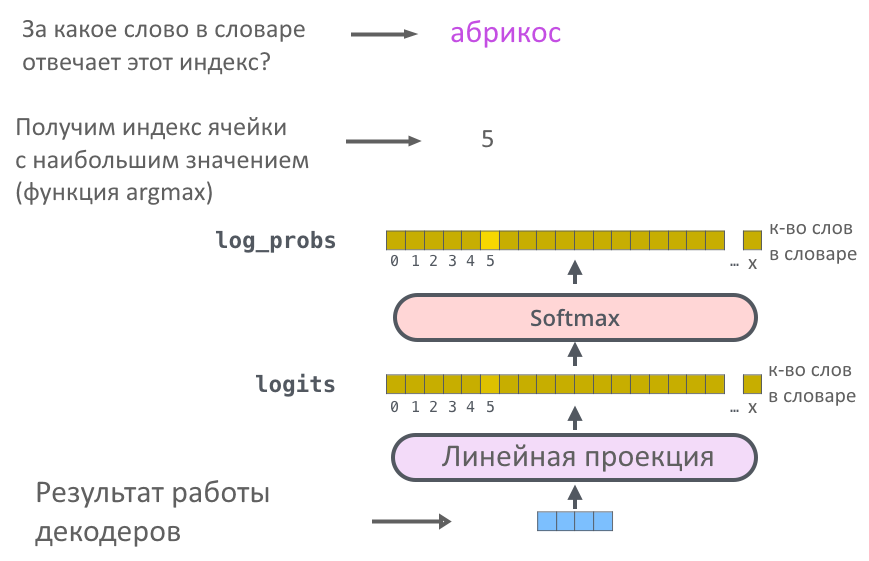
Для этого т.н. «Финальный слой» умножает выдачу декодера на очень широкую матрицу: ширина матрицы — количество слов в словаре модели (допустим, сто тысяч). После умножения получается вектор из ста тысяч чисел (его называют logits): первое число показывает вероятность, что следующее слово — абакан (или другое первое слово по алфавиту), второе число — вероятность «абажура» (или какого-то другого второго слова) и так далее до конца словаря.
Чтобы большие значения вероятности стали еще больше, а маленькие — еще меньше, применяют Softmax: он как бы добавляет «резкости» предсказанию, чтобы из всех слов можно было выбрать одно самое вероятное. Подробнее о работе Softmax мы писали в первой части текста про трансформер.
Заключение
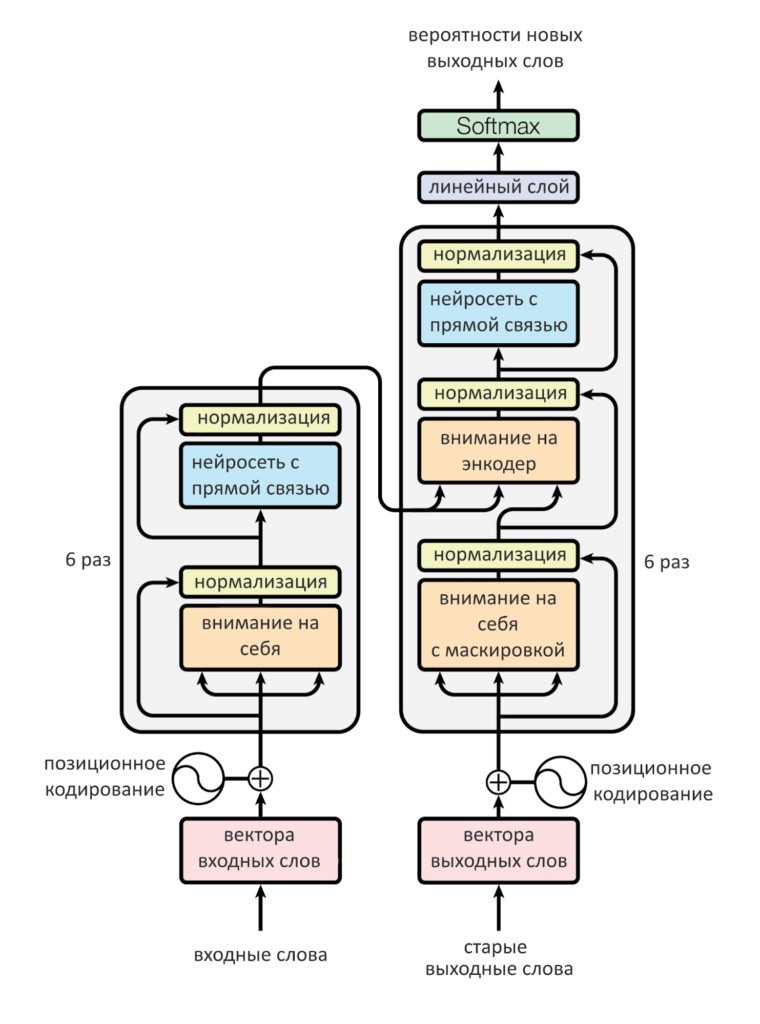
Теперь, когда известны последние детали, подытожим, как работает архитектура трансформера в целом:
- Энкодер кодирует стопку (батч) предложений за раз, пропуская эту стопку через шесть своих слоёв. Внутри одного слоя энкодера — «внимание на себя» и нейросеть с прямой связью. Всё сопровождаются нормализацией, она обязательна и в декодере. Кодирование завершено.
- После работы энкодера первый слой декодера начинает работу с матрицей уже сгенерированных слов: первым включается «внимание на себя». Но пока ничего не сгенерировано, все значения входной матрицы декодера «замаскированы». Ничего не получает веса внимания, декодер включает «внимание на энкодер»
- Внимание на энкодер формирует запрос Q из данных «внимания на себя» и ищет его среди ключей К и значений V энкодера.
- «Внимания на энкодер» передает работу в нейросеть с прямой связью, а оттуда — на остальные шесть слоев декодера. С последнего слоя декодера результат попадает на «Финальный Слой», где вектор превращается в слово. Первый временной шаг декодирования закончен.
- На втором временном шаге первым опять включается «внимание на себя». Теперь оно смотрит на обновленную входную матрицу для декодера, где естьпервое выданное нейросетью слово. Внимание на себя отрабатывает, за ним — внимание на энкодер (в энкодере ничего не поменялось), потом — нейросеть с прямой связью, слой за слоем, и декодер выдает второе слово.
- На третьем шаге во входной матрице декодера уже два прошлых слова. Теперь можно декодировать слова до тех пор, пока входная матрица декодера не заполнится до конца и не сгенерируется сигнал остановки.
На этом кончается рассказ про стандартный трансформер, описанный в 2017 году в работе «Attention is all you need». С тех пор, как вышла эта работа, исследовательские группы IT-гигантов придумали немало трюков по улучшению стандартного трансформера. Наверное, главная проблема трансформера — в том, что вычислительная сложность механизма внимания — в квадратичной зависимости от ширины «окна» внимания, обычно в 512 токенов. Поэтому окна не получается делать очень уж широкими, компьютер не успевает считать. Чтобы обработать большой текст, приходится внахлест делить его на окна фиксированного размера и обрабатывать по очереди.
Решение — упростить механизм внимания или добавить постоянной памяти трансформеру. С этими идеями появились Longformer, Reformer, Transformer-XL, Sparse Transformer и другие архитектуры. Мы постараемся описать их в последующих постах.
Источники
- The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time. — обязательно загляните
- Статья Attention Is All You Need
- Attention Is All You Need — видеолекция на Ютубе
- Glossary — transformers 2.11.0 documentation — объяснения и документация на английском



