
Мы продолжаем серию постов об устройстве нейронных сетей. В прошлом материале «Системный Блокъ» рассказывал о том, зачем нужны рекуррентные нейросети, что такое рекуррентность и как добавить нейросети долгосрочной памяти. Сегодня мы пойдем дальше: разберем, что такое механизм внимания, для чего он нужен и как работает.
Что мы рассказывали в прошлый раз
Рекуррентный — значит возвращающийся. RNN угадывает следующие слова в тексте или ноты в мелодии, возвращаясь к своим прошлым догадкам. Прошлые догадки нейросеть хранит как вектор активации нейронов и передает с шага на шаг. Так кодируется прошлый контекст в тексте, музыке, речи.
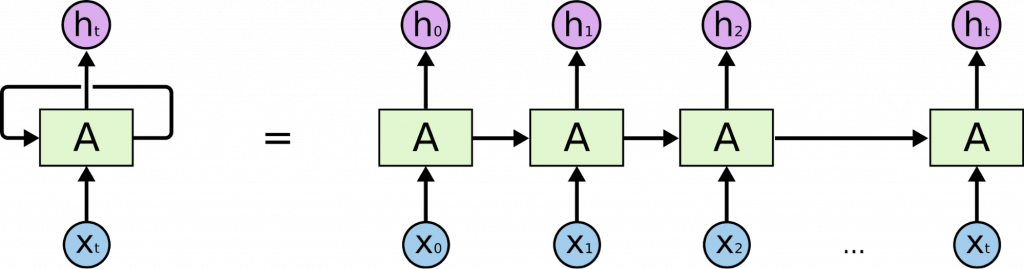
Развитие идеи RNN — нейросеть LSTM: она не передает контекст целиком, а решает, какую часть использовать, а какую — забыть. LSTM по-разному модифицировали, чтобы лучше отличать важный контекст от неважного. Даже придумали новую архитектуру GRU (Gated Recurrent Unit). В GRU тоже есть функции, определяющие, какую часть кодированного контекста передавать по цепочке дальше.
Проблема 1: RNN работает недостаточно эффективно
У всех нейросетей, что передают данные с шага на шаг, есть фундаментальные проблемы. Первая — если данные передаются по цепочке, значит, следующие вычисления не начнутся, пока не закончатся прошлые. Причина — следующий шаг принимает результат предыдущего как переменную.
Ждать, пока закончится старая операция, чтобы начать новую — долго. Компьютерное «железо», особенно графические процессоры, хорошо разбивает крупные счетные задачи на мелкие параллельные, и выполняет их вместе быстрее, чем по очереди. Иными словами, рекуррентность не дает загрузить компьютер на полную мощность.
В 2017 проблему решили исследователи из Google Brain и Google Research. В статье «Attention is all you need» («Внимание — все, что вам нужно»), они описали новый тип нейросетей — «трансформер».Трансформер — не рекуррентная нейросеть. Он не передает весь контекст по цепочке и не выбирает из него нужные части. Зато при каждом новом предсказании трансформер фокусирует внимание только на тех на словах, которые считает важными.
Спойлер: внимание вкратце — это умножение вектора слова на числа. Если слово важное — множители будут большими и вектор слова «выделится» среди соседей.
Трансформер — сложная архитектура. Лучше начать с механизма внимания рекуррентных нейросетей, которые все-таки передают информацию с шага на шаг. Так можно сделать, поскольку «внимание» нейросетей изобрели не авторы трансформеров: механизм использовался и раньше, но не был основным.
Итак, основная тема поста — механизм внимания.
Проблема 2: RNN учитывает только прошлый контекст
RNN работает медленно, но есть и вторая проблема — модели, которые мы описали, умеют смотреть только на прошлый контекст. Этого иногда мало. Вот два предложения: «He said Teddy Roosevelt was a great president» (он сказал, что Тед Рузвельт — отличный президент) и «He said Teddy bear is expensive» (он сказал, что плюшевый мишка — дорогой). Нейросеть угадывает, где в предложении стоят имена собственные и присваивает словам значения: 1 каждому имени собственному, 0 каждому другому слову.
Нейросеть дошла до слова Teddy. Ей нужно решить, означает ли Teddy имя Рузвельта или слово «плюшевый». У RNN есть только вектор Teddy и «след» прошлых слов (вектор контекста): в нем закодировано, что раньше было написано «He said», «он сказал». Надо заглянуть вперед, за нынешнее слово: тогда станет ясно, что в одном случае Teddy — Roosevelt, а в другом — мишка.
Чтобы смотреть на все предложение, а не только на прошлую часть, программисты придумали Bidirectional RNN (двунаправленную RNN или BRNN). Она обрабатывает предложение один раз слева направо, другой раз — справа налево, и только потом начинает предсказывать. В этом посте мы сначала по шагам разберем работу BRNN, потом на ее примере расскажем про механизм внимания.
Двунаправленная RNN считает контекстом все предложение целиком (или N слов слева и справа). Когда контекст — все предложение, яснее видно, что на каких-то словах нужно фокусироваться сильнее, чем на других. BRNN поможет проиллюстрировать, почему механизм внимания нужен и полезен.
Проблема 3: в RNN контекст размывается со временем
Посмотрите, сколько шагов нужно пройти вектору слова X0, чтобы попасть в предсказание слова h3. Путь получается таким длинным из-за того, что слова предсказываются последовательно.
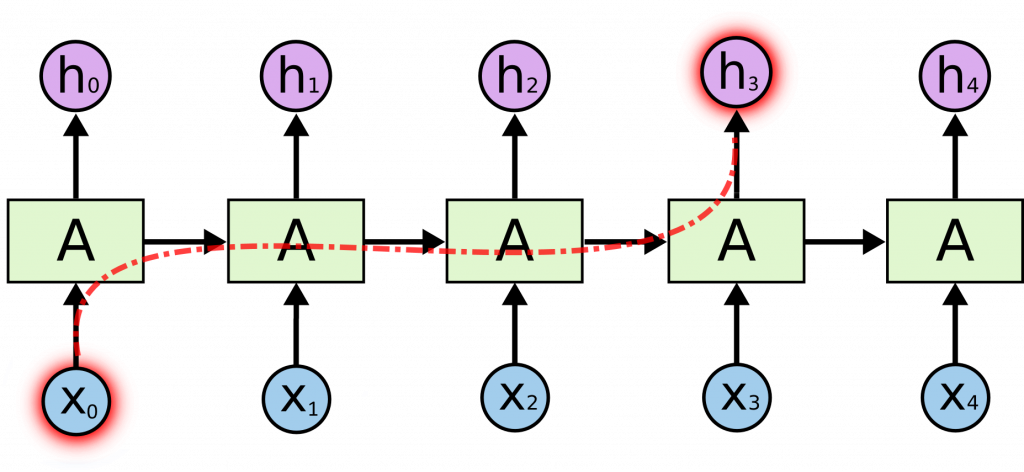
Чем длиннее путь слова, тем сильнее оно «размывается» в рекуррентной сети, даже если передавать по цепочке не весь контекст, а только важные части (как в LSTM). А отдаленные слова бывают важны. Вот предложение: «Кошка съела рыбу, котлету, сосиску и два блинчика, но все еще была голодна». Чтобы правильно угадать слово «была» (а не «был»), нужно помнить, что в контексте стоит вектор слова «кошка», а не «кот». В нейросети без внимания к вектору «кошки» примешивается вектор «котлеты», «сосиски» и «блинчиков», и к концу предложения уже трудно разобрать, что там стояло в начале.
Технические детали: на каждом шаге элементы вектора контекста возводятся в степень или умножаются, и через несколько шагов их производные либо «взрываются» (стремятся к бесконечности) либо «стираются» (стремятся к нулю). Это называется проблемой затухающих и взрывных градиентов. «Сотрутся» они или «взорвутся», отчасти зависит от того, было ли изначальное значение элемента больше или меньше единицы (если возвести 0,9 в квадрат, получится число меньше изначального, а если 1,1 — больше). Поэтому к концу преобразований всё сильно запутано.

Когда слово долго хранится в контексте, оно «портится» и слабее влияет на следующие предсказания. Это значит, что на догадку нейросети о новом слове больше всего влияют прошлое слово (и следующее, если RNN — двунаправленная). Даже в случае с умной LSTM.
Механизм внимания решает проблему. Его цель — заставить нейросеть сильнее сосредоточиться на важном слове в дальнем конце предложения. Контекст — это сумма векторов всех слов в предложении. «Подсветить» важное слово в контексте — значит умножить его вектор на большое число («вес внимания»). Чтобы понять, какое слово сейчас важно, потребуется еще одна нейросеть (внутри нейросети).

Типы рекуррентных архитектур
Что такое энкодер-декодер и зачем он нужен
Чтобы объяснить нейросетевое внимание на примере, мы выбрали известную научную статью 2014 года про применение нейросетей в машинном переводе (у статьи сейчас почти 13 тыс цитирований на Google Scholar). Статья — о том, как перевести текст, если у вас есть двунаправленная RNN с механизмом внимания. Нейросеть из примера состоит из двух частей: энкодера и декодера. В этом разделе объясняем, что это за части и зачем они нужны.
Вкратце: энокдер зашифрует последовательность в виде вектора (превратит входной текст в набор абстрактных чисел, которые условно кодируют смысл), а потом декодер расшифрует этот вектор в другую последовательность (например, на другом языке).
Архитектура «вектор → вектор»
В примерах раньше на входе и на выходе нейросети были последовательности. Их длины были равны.
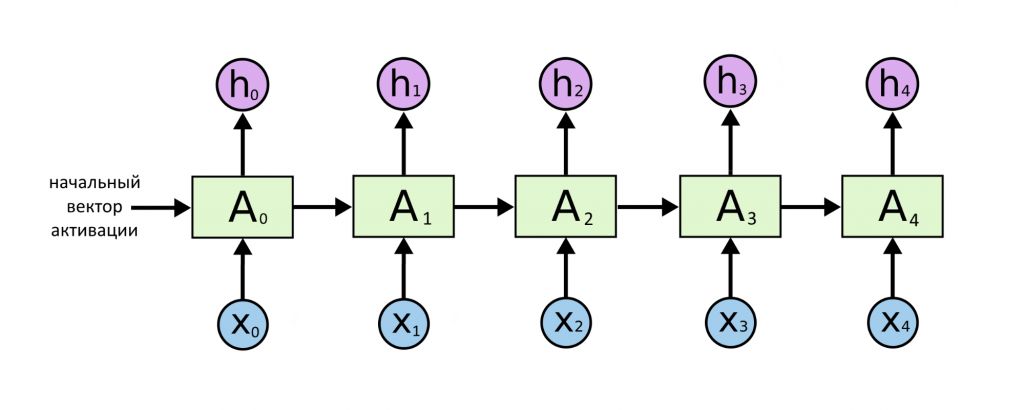
Количество входных слов совпадает с количеством выходных. Так бывает, если пословно дополнять текст. Тогда старые предсказания h становятся новыми входными словами X. Еще так бывает, когда каждому входному слову нужно присвоить какую-то метку, например, 1 — если слово — имя собственное, 0 — если нет. Не всегда длина входной и выходной последовательности совпадают. Вот разные случаи.
Самая простая архитектура превращает один вектор в другой вектор, пользуясь начальной активацией нейронов a(0). Здесь вообще нет последовательности генерируемых векторов. По сути, это даже не рекуррентная нейросеть, ведь она не передает свое значение никуда дальше. Но ее можно представить как частный случай рекуррентности: пример показывает, что как на входе, так и на выходе нейросети может быть не последовательность, а единственный вектор.
Это была модель «вектор → вектор».
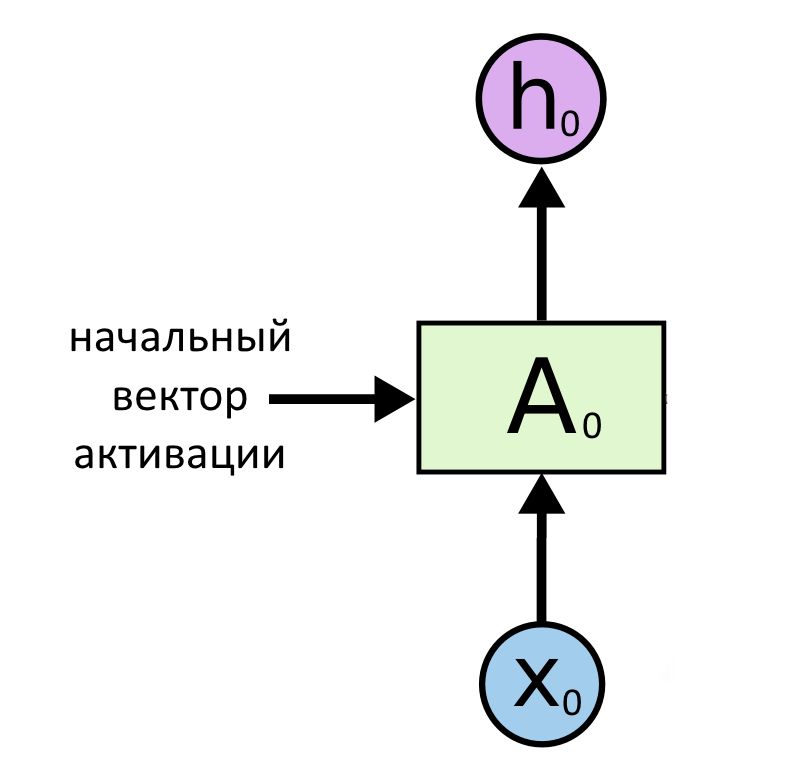
Архитектура «вектор → последовательность»
Дополним прошлый пример, получится следующая архитектура.
Бывает, что нужно из одного вектора сделать несколько. Пример — генерация музыки: на входе нейросети может быть только число, означающее жанр, или какое-то случайное «зерно» X. «Зерно» закодируется в вектор и превратится в ряд векторов, каждый из которых станет одной нотой. Такая модель на каждом шаге, кроме первого, принимает на вход только результат своей предыдущей работы.
Это была модель «вектор → последовательность». Иногда ее называют «генератор».
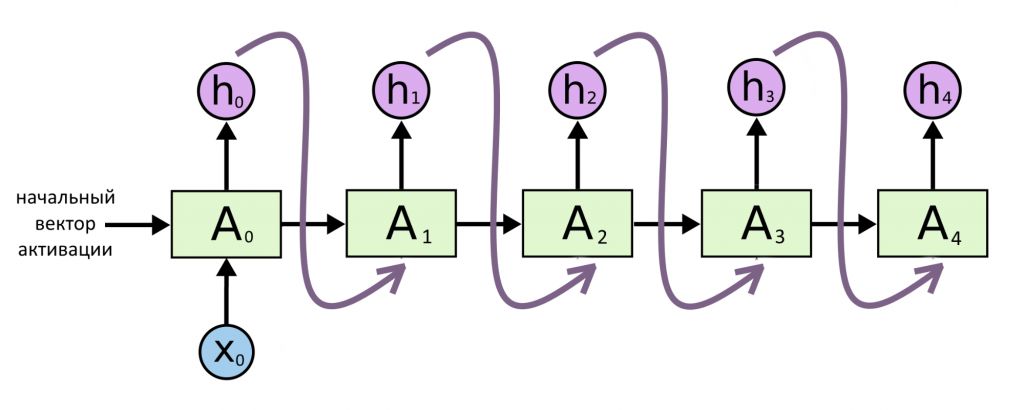
Архитектура «последовательность → вектор»
Иногда нужно череду значений переписать в виде одного значения. Например, чтобы понять тональность текста: на входе — последовательность векторов слов X, а на выходе — единый вектор Y. Его элементы показывают вероятности, что тональность текста — радость, печаль, агрессия, скука. В такой архитектуре из всех предсказанных значений сохраняется только самое последнее.
Это была модель «последовательность → вектор»
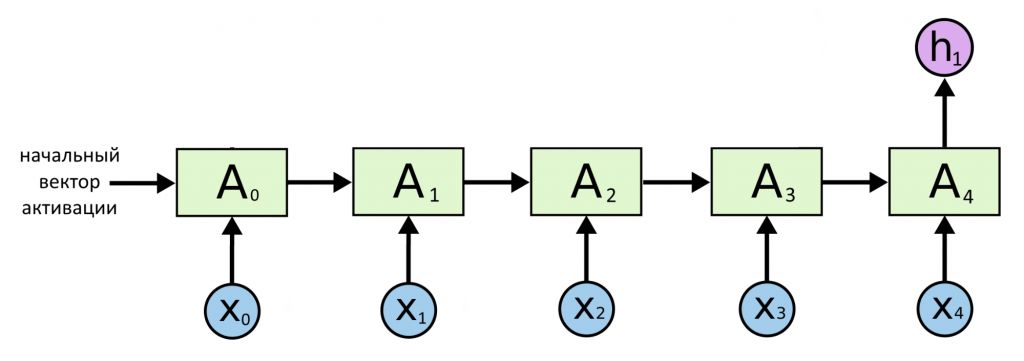
Архитектура «последовательность → последовательность» (энкодер — декодер)
А вот случай, про который уже писали раньше. Ряд векторов — на входе и на выходе, и длины рядов равны. Одинаковость входов и выходов прочно «вшита» в архитектуру: один выходной вектор получается, если нейросеть видит на входе один входной. Все примеры из прошлой статьи — про эту архитектуру.
Это была модель «последовательность → последовательность»
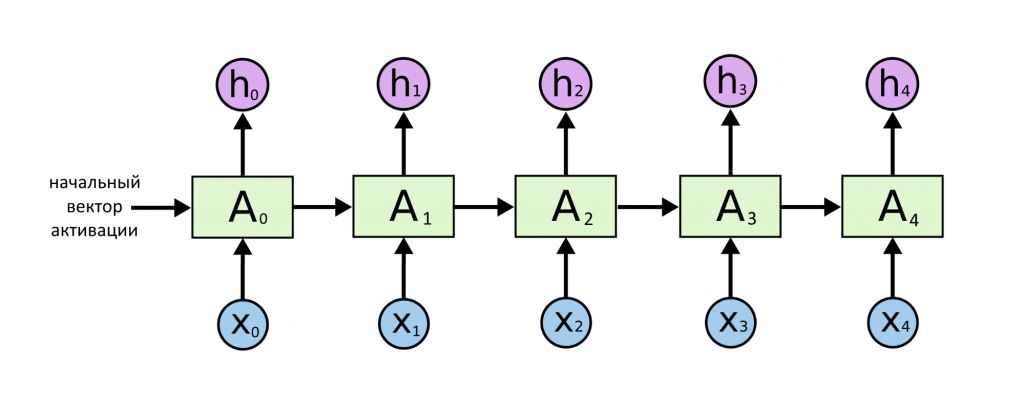
Последняя модель называется «энкодер-декодер». Ей пользуются, если нужно работать по типу «последовательность → последовательность», но непонятно, как связаны длины входа и выхода (т.е. на входе 5 слов, то на выходе может быть 2, а может быть 10, и мы не можем это заранее угадать).
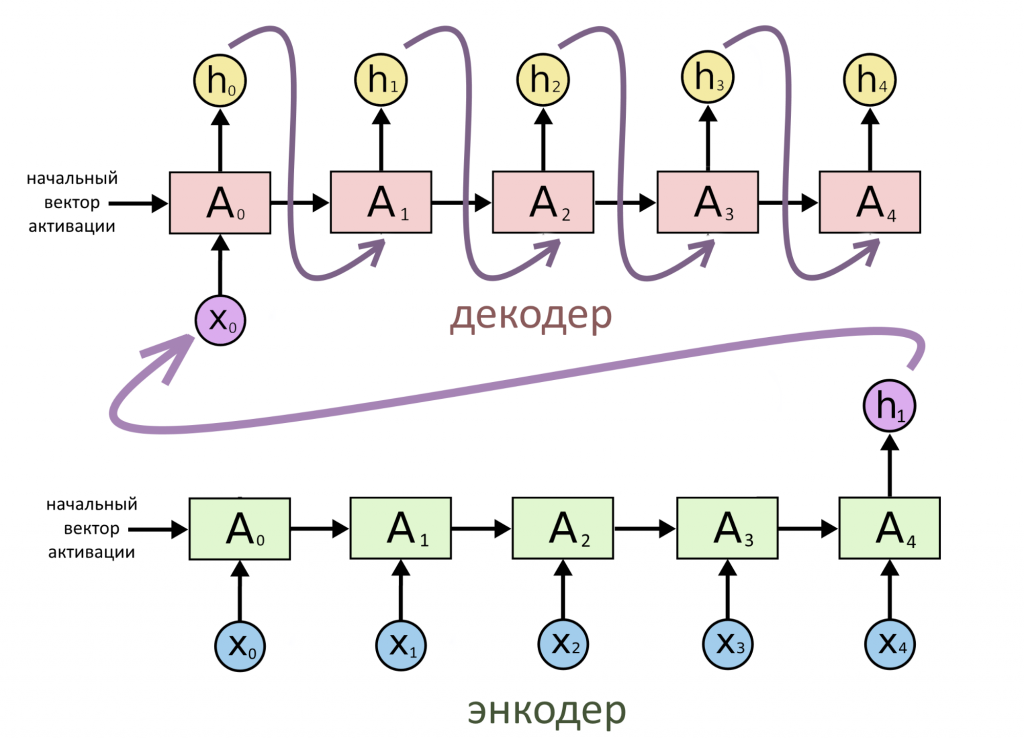
Что это значит на практике?
Чем хороша архитектура «энкодер — декодер» для машинного перевода
При переводе на иностранный язык число слов в оригинале и в переводе почти никогда не совпадает. Одно слово может переводиться двумя-тремя, а может вообще каким-нибудь устойчивым выражением.
Ага, думает разработчик, на входе — предложение, это последовательность слов. Если взять архитектуру «последовательность → вектор», то можно закодировать (encode) предложение единым вектором.
А раз получился единый вектор, который нужно превратить в перевод, значит, можно взять архитектуру «вектор → последовательность». Эта часть декодирует (decode) исходное предложение.
«Даже великий и ужасный трансформер состоит из кодирующей части и декодирующей»
Две части нейросети, «слепленные» таким образом вместе, образуют мощную архитектуру «энкодер-декодер». Именно она обычно используется в задачах машинного перевода. Позже мы покажем, что даже великий и ужасный трансформер состоит из кодирующей части и декодирующей.
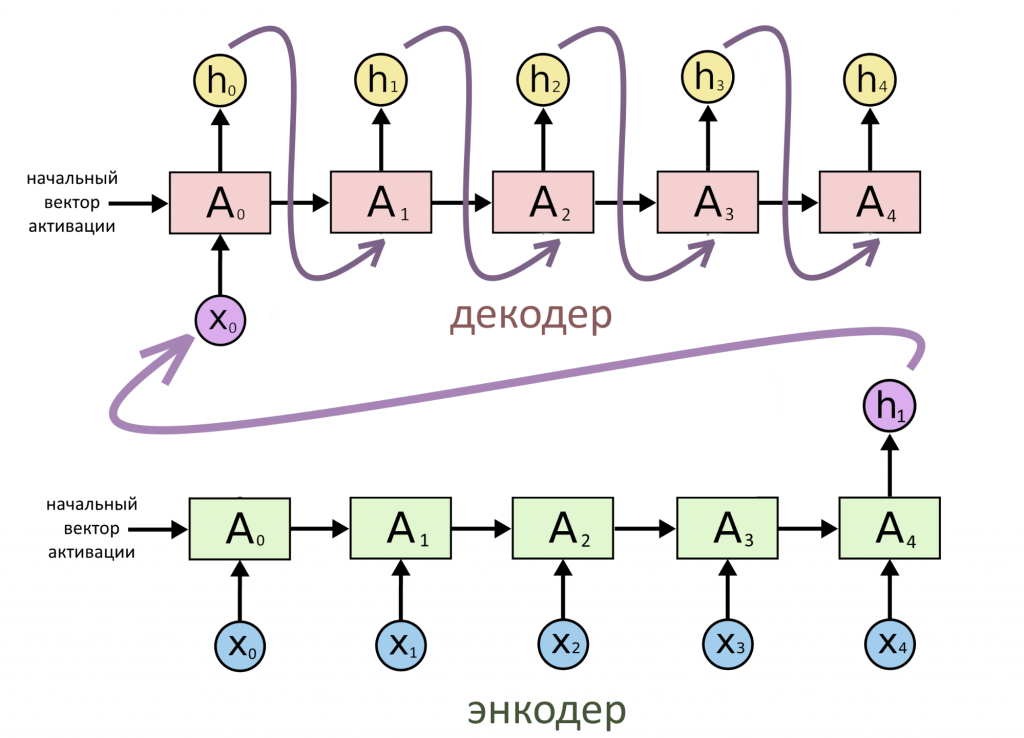
«Энкодер-декодер» универсален. Внутри на рекуррентных слоях могут «лежать» любые архитектуры, GRU, LSTM или другие, если речь идет об обработке текста. Но самое крутое, что не обязательно сводить все именно к тексту!
Если кодирующую часть составить из сверточных слоев, представляющих картинку в виде вектора, а декодирующую — в виде рекуррентного «генератора», можно сделать автоматическую подпись субтитров к изображениям или видео — были бы только данные для обучения. А можно — распознавать пешеходов на улице, если вы — инженер Tesla.
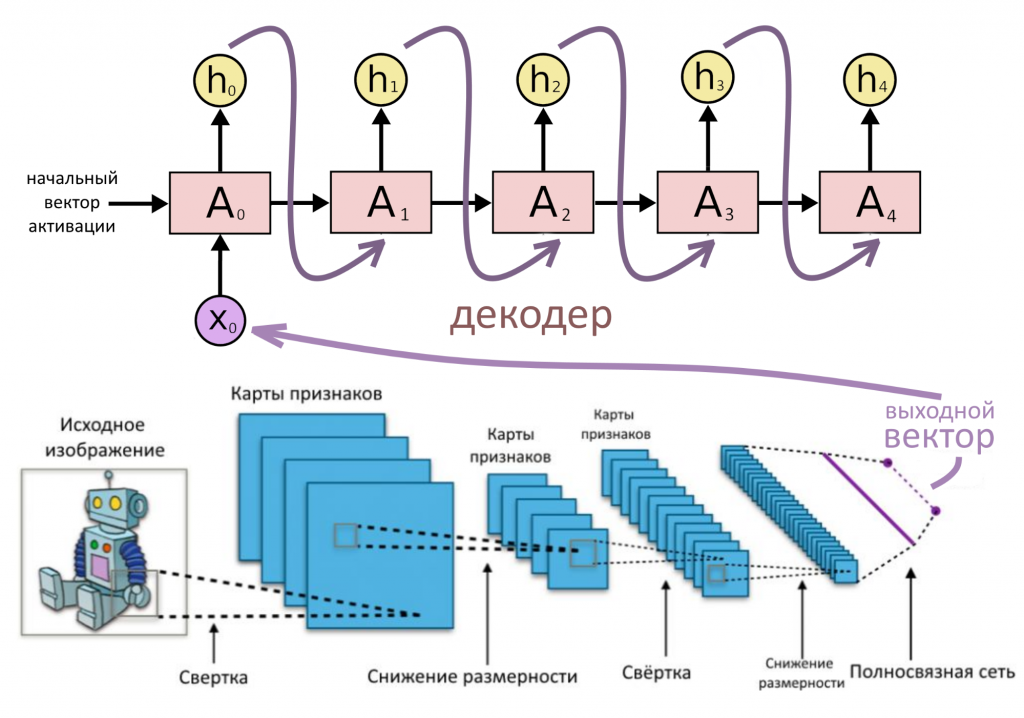
Ну а тот самый механизм внимания — отличный метод взаимодействия между кодирующей и декодирующей частями нейросети. Иногда его называют «интерфейсом» между двумя этими частями. Мы почти готовы разбираться с вниманием, только для этого надо еще раз вспомнить о двунаправленных RNN.
Как работает двунаправленная RNN
BRNN нужны, чтобы смотреть не только на прошлые слова, а на всю фразу
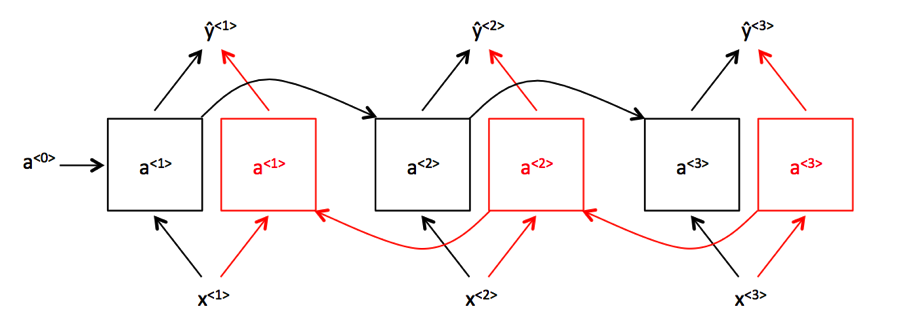
Работа начинается так: нейросети подают на вход несколько векторов слов: X1, X2, X3, X4.
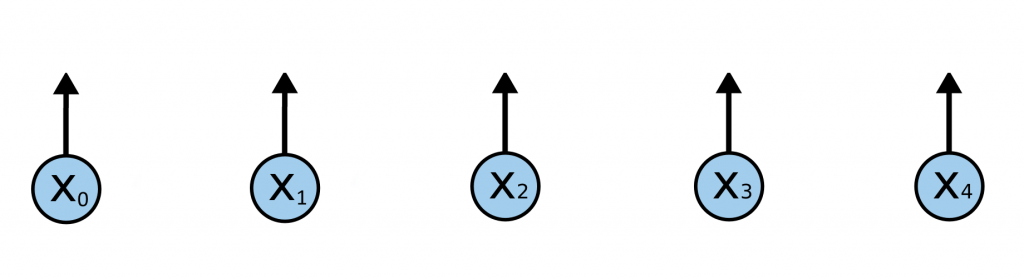
Нейросеть подает первое слово на слой A1, оттуда картину активации нейронов — на A2, и так далее слева направо. Каждый слой выдает предсказание h, это «зашифрованное» входное слово. Пока модель ведет себя как обычная RNN архитектуры «последовательность → последовательность». Только стрелки немного сместились.
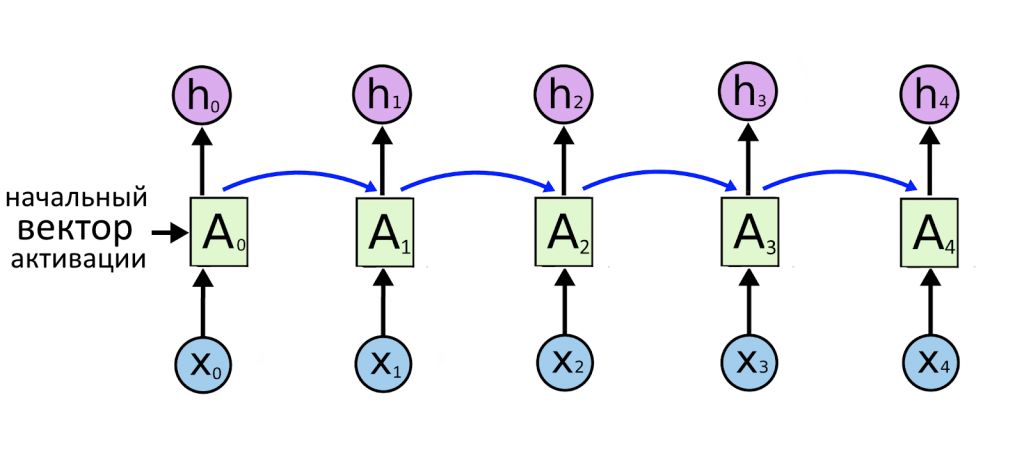
Теперь добавляем еще один слой нейронов для каждого входного слова, эти слои назовем B.
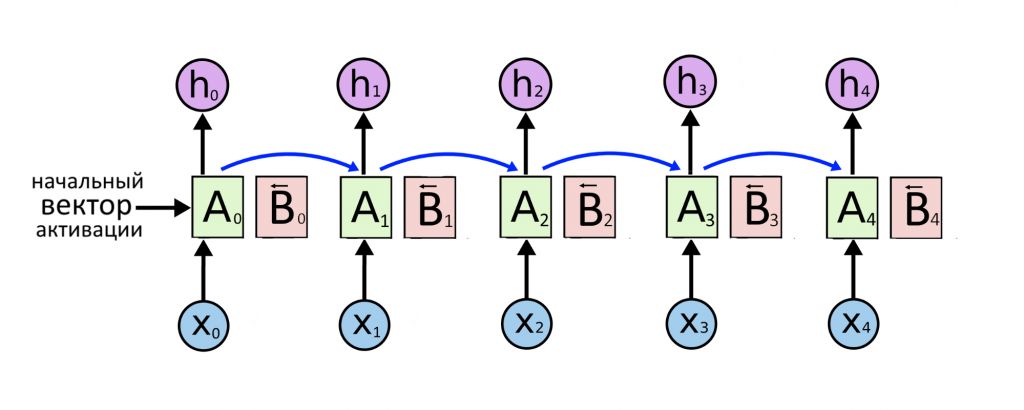
Слои B тоже выдают предсказания, но передают контекст справа налево: B4 → B3 → B2 → B1. Каждый слой B работает со своим словом: B2 получает X2, B3 получает X3. В целом — та же самая RNN, но справа налево. Ее слои начинают работу сразу, как закончит считать последний салатовый слой A (слева направо).
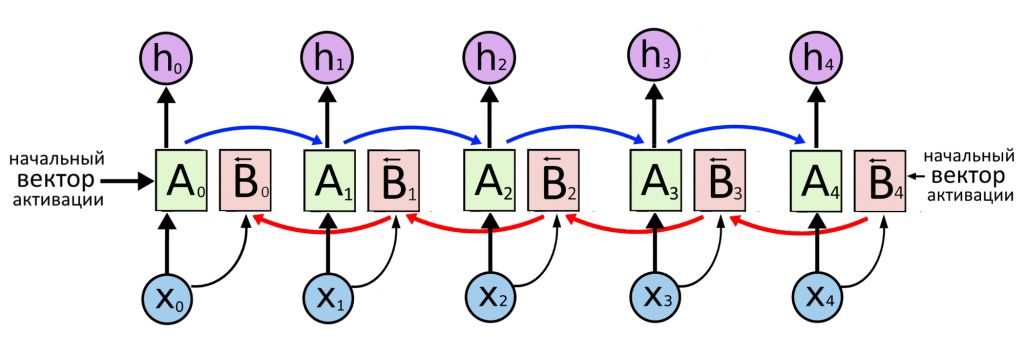
Предсказания слоев B обозначим как h(B). Выпишем каждое предсказание h и h(B) подряд и «склеим» их (конкатенируем). Результат назовем Y с нужным индексом. Вектор Y станет нейросетевой «идеей» о слове X, причем в учет этой идеи берется не только контекст до слова, но и контекст после него.
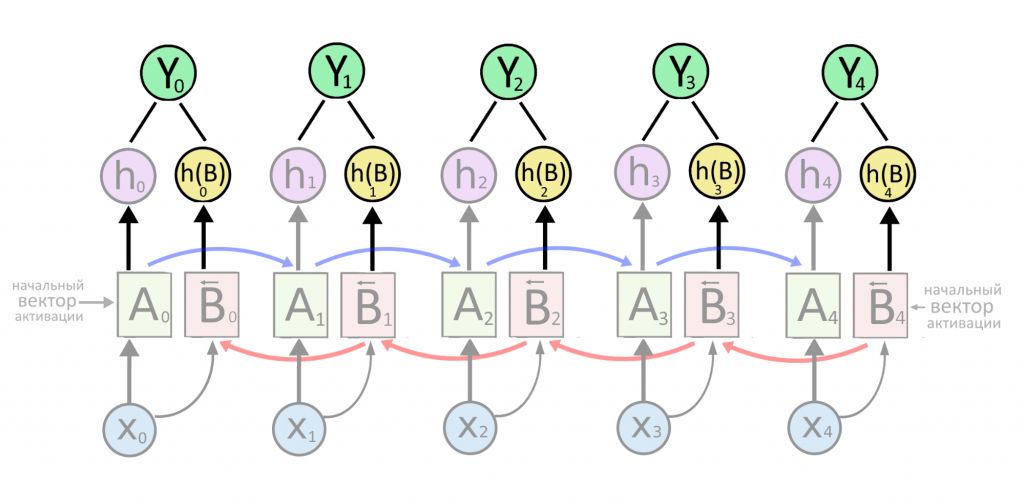
Проблем у BRNN две. Первая — на слово сильнее всего влияют ближайшие соседи (но это проблема всех рекуррентных нейросетей). Вторая — не всегда можно получить последовательность целиком. С текстом это не сложно, но если вы распознаете речь в реальном времени, придется дождаться, пока человек договорит.
И тут на сцену наконец выходит внимание.
Идея механизма внимания
Стоит задача — перевести предложение с французского на русский при помощи модных нейросетей. Предложение — это цепочка слов, и длины цепочек в оригинале и в переводе не связаны. Значит, нужна RNN типа «энкодер-декодер». Энкодер будет двунаправленной RNN, чтобы учитывать слова не только слева, но и справа.
Энкодер зашифрует все предложение в единый вектор-контекст. Вектор-контекст — сумма векторов отдельных слов. Перед тем, как складывать слова, вектора важных слов умножим на большие числа. Таким образом мы искусственно повысим значимость важных слов на последующих шагах работы алгоритма. Это умножение — и есть механизм внимания. После кодирования декодер-RNN расшифрует вектор-контекст и сделает из него перевод. И этот перевод будет лучше, чем если бы внимания не было.
Само слово «внимание» — метафора: алгоритм заставляет нейросеть «сконцентрироваться» на отдельных элементах рабочего предложения. Так же поступает и человек: когда переводчик работает с текстом, он больше всего сосредоточен на переводе текущего слова, учитывает ближайший контекст до и после него, а если нужно, посматривает на дальние слова, сильно меняющие смысл. Всю последовательность переводчику запоминать не обязательно.
Как сделан механизм внимания в энкодере
Начнем с двунаправленной RNN. Она уже вычислила векторные представления Y для каждого слова X. Можно говорить «выучила признаки» слова. Y — это склеенные вектора активаций слоев A и B (передают контекст слева направо и справа налево).
Если убрать с картинки лишние детали, получится так
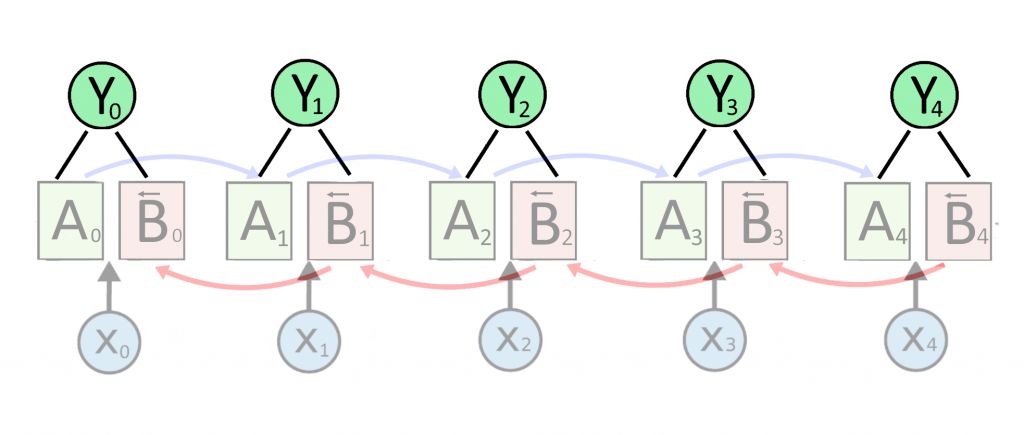
Теперь сверху появляется первый слой рекуррентного декодера D, который будет принимать на вход что-то и выдавать перевод первого слова. Перевод выдается в виде вектора O, сокращенно от output — результат. Что подавать на вход декодеру?
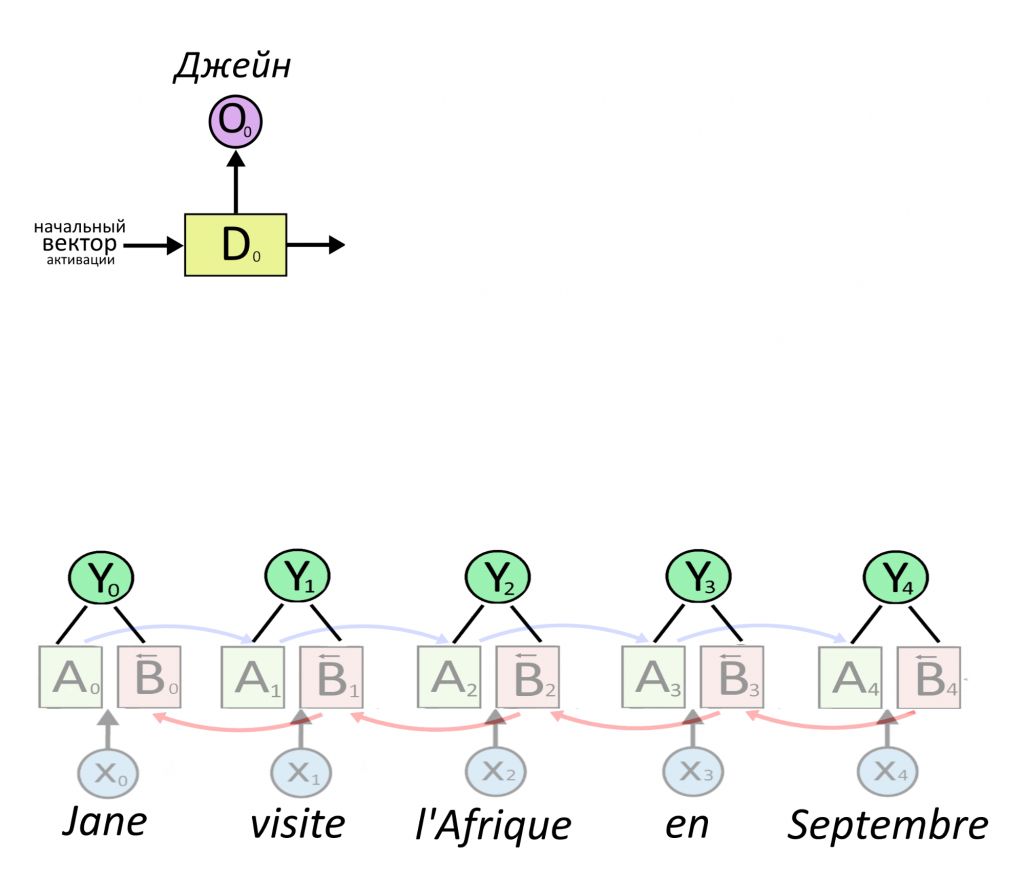
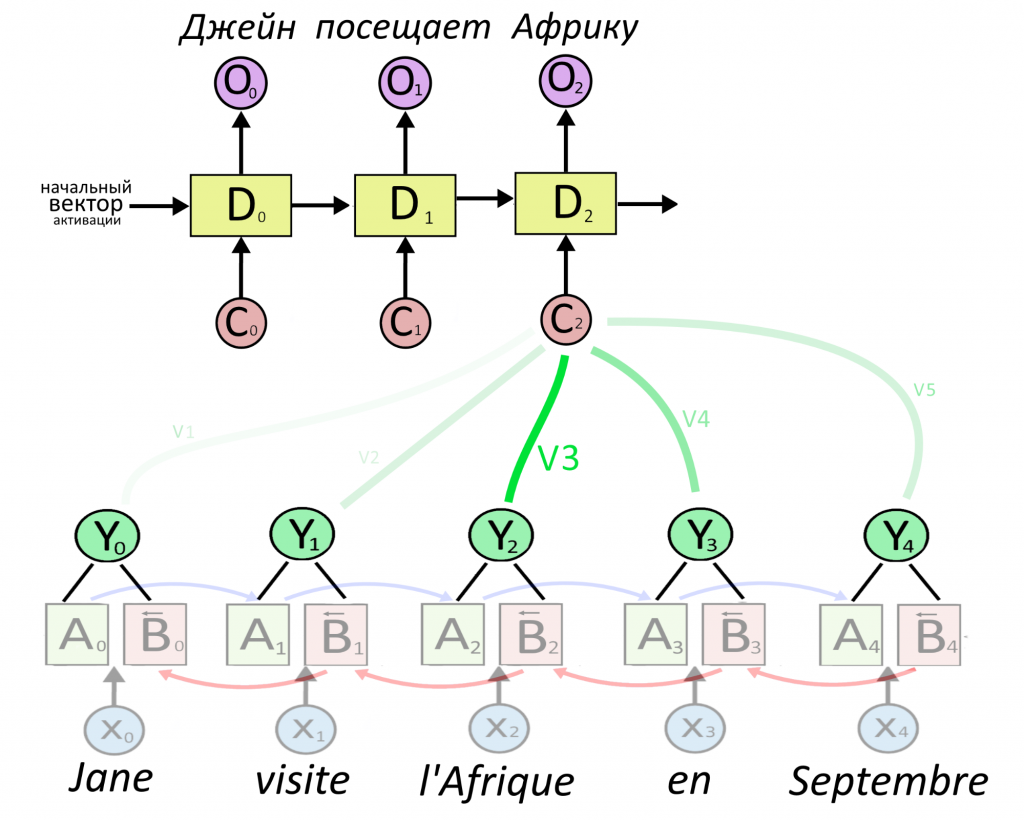
Декодеру можно подать представление какого-то одного слова — обычно последнего в предложении, ведь в нем собрался весь прошлый контекст. Но есть вариант круче: подадим декодеру сумму сразу всех представлений, но перед этим умножим каждое из них на свой «вес». Вес — это тоже вектор, назовем его V. Чем больше вес, тем сильнее нейросеть обращает внимание на слово.
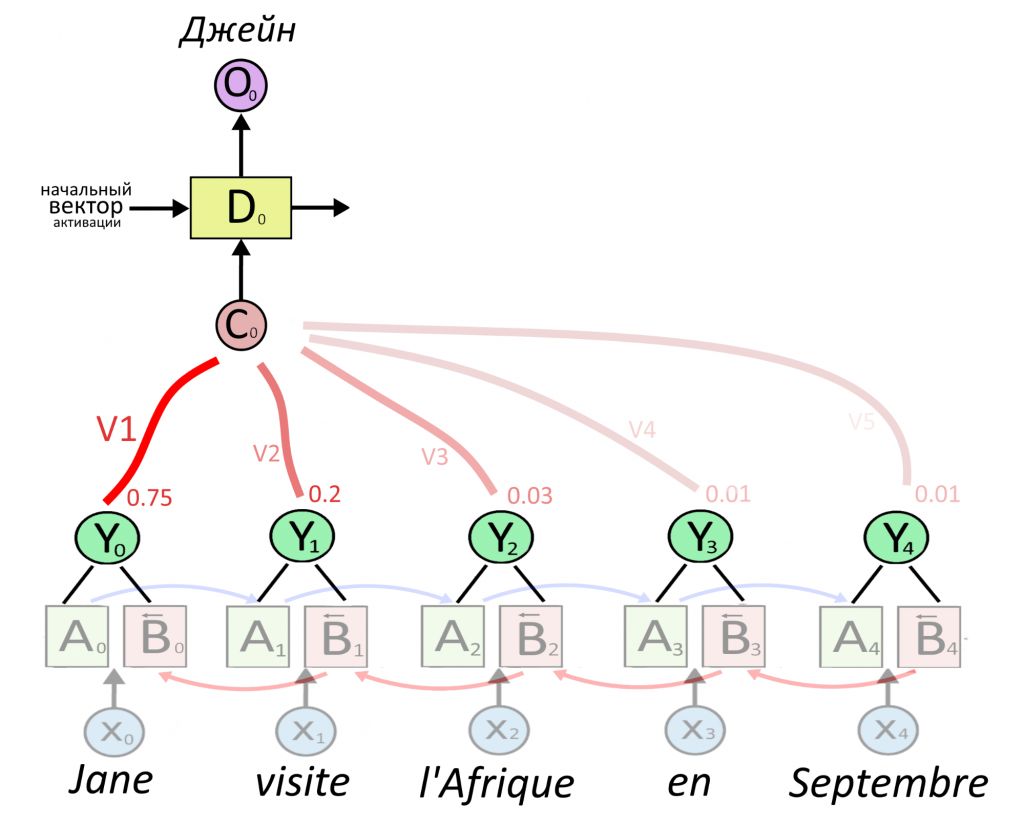
Как определить вес внимания и важность слова — ниже. Сейчас важно, что из суммы «взвешенных» (умноженных на вес) векторных представлений Y получается вектор-контекст C (от английского context). Именно вектор C, где «зашиты» не только представления каждого слова, но и степень их важности, послужит «топливом» для декодера.
Еще раз: C = V1Y1 + V2Y2 + V3Y3 + …. + VnYn.
Как сделан механизм внимания в декодере
Декодер здесь — однонаправленная RNN. Это значит, что на каждом шаге он смотрит на свою прошлую работу и на текущий вектор-контекст C, который пришел от энкодера. На первом слое декодера вектор C0 активирует какие-то нейроны, и картина их активации идет на следующий слой декодера.
На втором шаге декодирования все повторяется. Как-то (как, пока не знаем) рассчитываются новые веса внимания V для каждого слова. Взвешенная сумма векторов слов становится вектором-контекстом С1. На вход декодеру приходит его прошлая работа D0 и новый контекст C1.
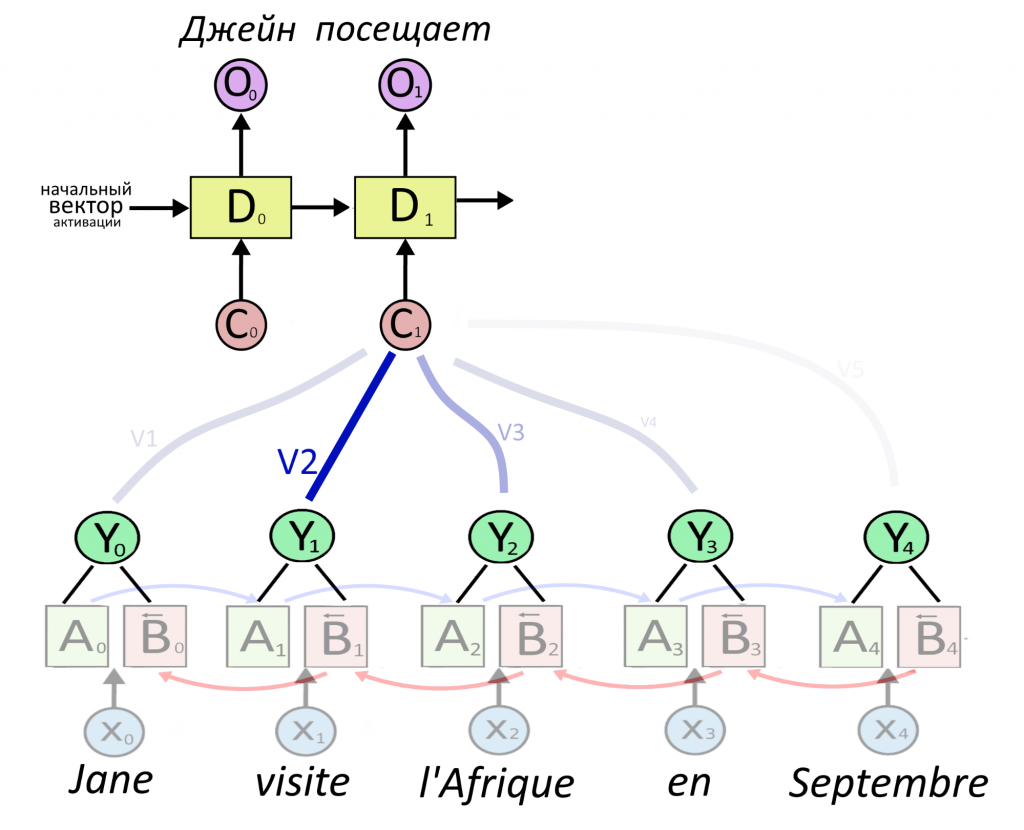
Дальше — все то же самое. Новое слово перевода получится из нового вектора-контекста и прошлой работы декодера. Так декодер будет генерировать слова одно за другим, пока не сгенерирует метку конца предложения.
Как получить вес внимания и понять, что на самом деле важно «запомнить»?
Пускай вес предсказывает однослойная нейросеть
Важность конкретного слова зависит от реакции на него энкодера и последней активации декодера (так решили разработчики). Последняя активация декодера называется D(t-1). Нынешней активации D(t) пока нет, ее надо вычислить.
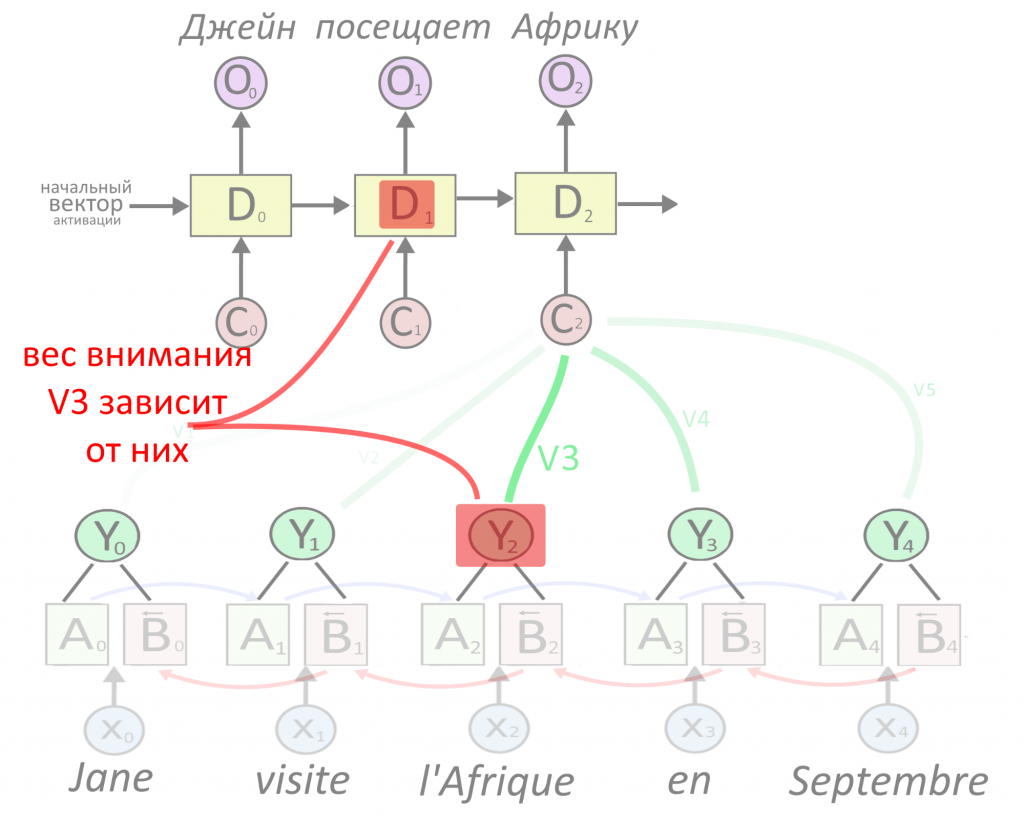
Вес внимания как-то зависит от двух переменных, но как — непонятно. Если есть зависимость — есть функция. Она принимает переменные и выдает вес внимания, и эту функцию никто точно не знает. Нейросети как раз нужны для того, чтобы моделировать неизвестные функции.
Пусть нейросеть угадывает, как из активации энкодера и декодер получить вес внимания! Но только очень маленькая, однослойная нейросеть, потому что угадывать придется много и часто.
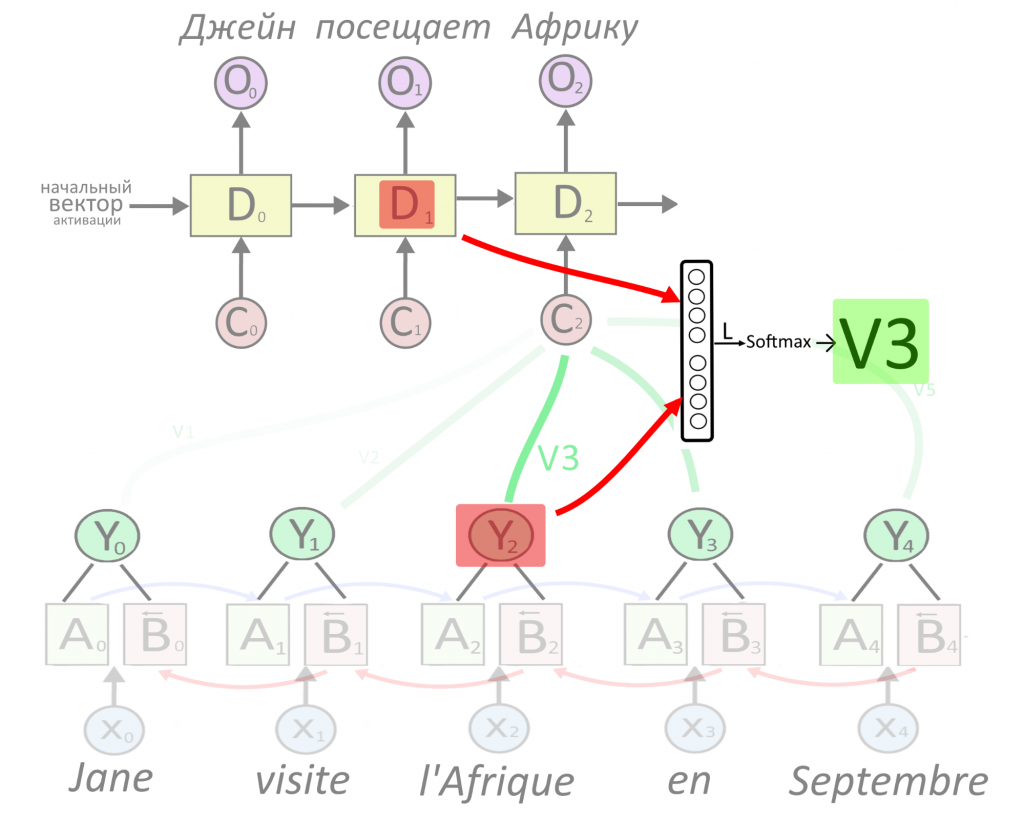
Когда декодируется «Африка», веса внимания зависят от D1 и всех Y по очереди
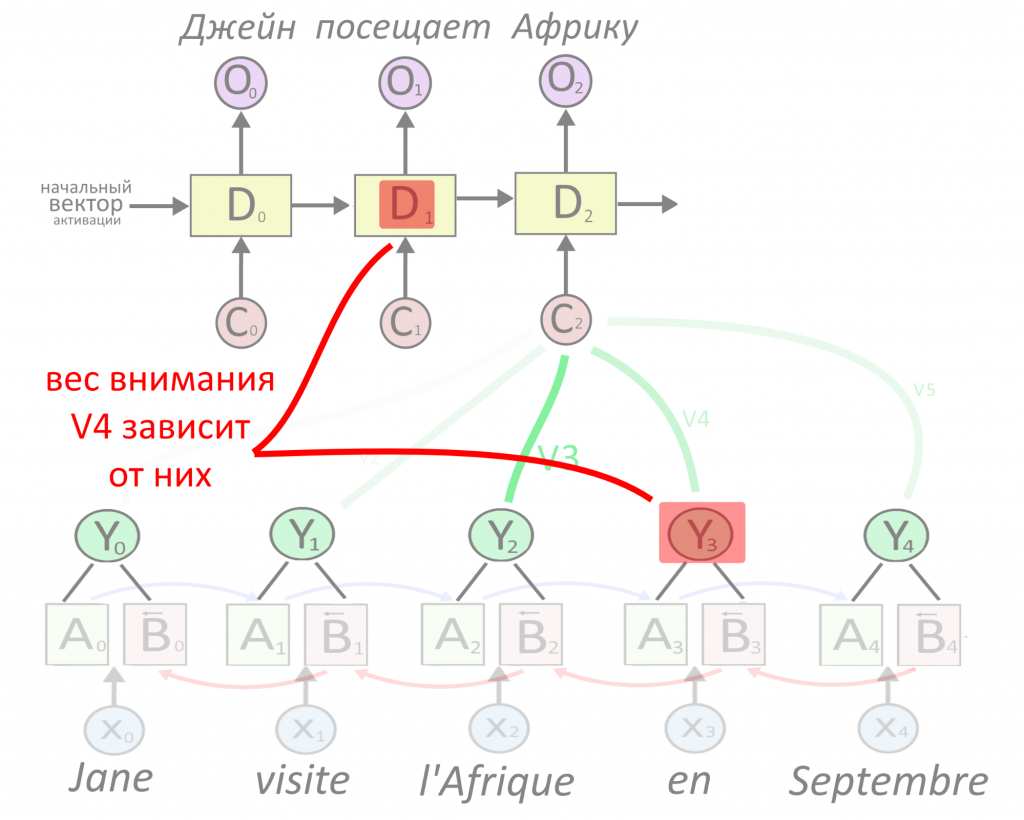
Маленькая нейросеть, о которой идет речь, — это матрица весов внимания, которая «выучивается» при обучении, плюс функция активации. То, что нейросеть «однослойная», значит, что такая матрица только одна, а то, что маленькая — значит, у матрицы буквально малая размерность.
Чтобы получить вес внимания, берем работу энкодера Y, свежую активацию декодера D(t-1), склеиваем, умножаем на матрицу. Получается вектор L. Пропускаем L через активационную функцию Softmax, получаем V, вес внимания. Сейчас расшифруем!
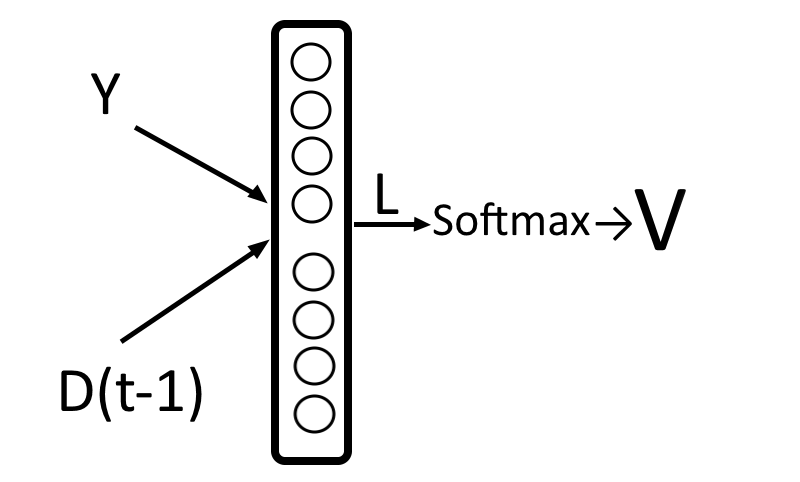
Сперва «склеиваем» вектора Y и D(t-1), эта операция называется конкатенацией. Просто записываем два вектора подряд и получаем один: [1, 2] + [3, 4] = [1, 2, 3, 4]. Теперь предсказываем L.
«Предсказать вектор L» — значит умножить входной «склеенный» вектор на матрицу весов внимания.
Предсказание пропускают через Softmax, функцию, которая превратит «сырой» вектор L, где может быть что попало, в распределение неотрицательных весов, которые в сумме дают 1.
У каждого входного слова несколько матриц внимания: по одной на каждый слой декодера. Каждую матрицу нужно выучить и где-то хранить. Поэтому авторы отмечают, что «окно внимания» их нейросети — примерно от 15 до 40 слов. Дальше становится трудно запоминать контекст. Когда нужно перевести большой текст, «окно внимания» передвигают по нему «внахлест»: так, чтобы в новое окно поместилось немного из старого. То есть в окно попадают сначала первые 40 слов, потом слова с 20 по 60-е, потом с 40 по 80, потом с 60 по 100 и т.д.
Как работает функция активации Softmax
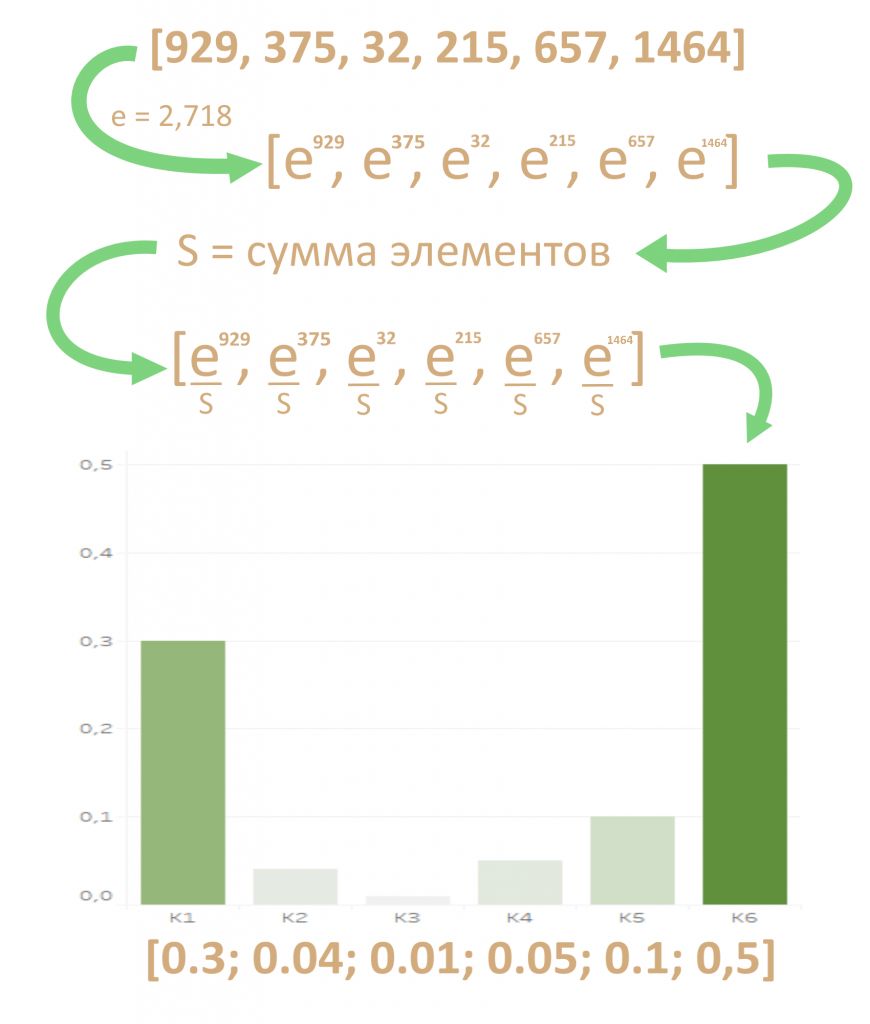
Возводит в степень группу чисел, и каждую степень делит на сумму всех степеней
Softmax возводит натуральный логарифм e (число Эйлера) в степени всех элементов вектора. Например, дан вектор L = [929, 375, 32, 215, 657, 1464]. e^L (е в степени L) будет вектором [e^929, e^375, e^32, e^215, e^657, e^1464]. Это сделает большие числа гораздо больше и усилит разницу между ними. Все элементы вектора e^L точно положительны, так как e — положительное число, около 2,718.
Итак, первый шаг Softmax — вычислить e^L для всех элементов вектора L.
Второй шаг — поделить каждый отдельный элемент e^L на сумму всех элементов e^L. Это даст «нормализованное», то есть относительное представление каждого элемента с учетом всех остальных элементов вектора. Такое представление мы и назовем вектором V, весом внимания.
Резюме: что в сухом остатке
Выпишем самое важное, что есть в нейросети:
- вектора Y — слова, закодированные с учетом контекста слева и справа от них
- вектор D — прошлое состояние декодера
- вектор V — вес внимания, предсказан с учетом Y и D
- вектор-контекст C — сумма всех слов Y, умноженных каждое на свой вес внимания V
- вектор O — перевод следующего слова, предсказан с учетом прошлого состояния декодера D и вектора-контекста C
В общем, если пересказывать в двух словах, внимание нейросети — это всего лишь умножение векторов. Зато теперь вы знаете, каких именно.
Зачем это нужно
Внимание в нейросетях — очень влиятельная идея. Сейчас все самые крутые архитектуры в обработке языка, начиная с GPT-2 от OpenAI и BERT до самых современных, полагаются на механизм внимания. Внимание можно применять не только в обработке текста: если «прикрутить» механизм к сверточным нейросетям, можно визуализировать, на какие части картинки смотрела нейросеть, когда решила, что на ней изобразили собаку.
В следующих текстах «Системный Блокъ» расскажет о трансформерах — нейросетевых архитектурах, которые не передают информацию с шага на шаг, как это делают RNN, но справляются с задачами обработки последовательностей (типа машинного перевода) не хуже. Основа их работы — именно механизм внимания. Только там внимание устроено еще хитрее, чем описано выше.
Многие базовые концепции из этого текста (архитектура «энкодер-декодер», двунаправленная RNN) встретятся вам еще не раз, если вы захотите узнать больше о современных технологиях обработки языка. Например, о нейросетевых архитектурах ELMo и BERT, которые просто доминируют на современном компьютерно-лингвистическом «танцполе» 🙂
Оставайтесь с нами и не пропустите самое интересное из мира автоматической обработки естественного языка!
Источники
- Курс Sequence Models на Coursera от deeplearning.ai — основа данного текста
- [1409.0473] Neural Machine Translation by Jointly Learning to Align and Translate — академическая статья, где описана архитектура, использованная в качестве примера
- Пример применения CNN-энкодера с механизмом внимания (Computerphile)
- Механизм внимания в картинках