
Для чего нужен record linkage
Жизнь человека не ограничена одной-единственной ролью. Он может быть, например, одновременно налогоплательщиком и ветераном войны, блокадником и избирателем (или любителем мемов с котами и автором статей в Системном блоке, но эти роли не так видны для просопографических исследований — то есть изучения коллективных биографий разных групп людей). Тем не менее, крупные биографические базы, как правило, объединены какой-то одной темой и не дают представление о полной биографии каждого из людей. Например, портал «Память народа» собирает данные об участниках войны, и все упоминаемые там люди выступают только в этой роли: в базе портала будут храниться основные данные (ФИО, год и место рождения) и, например, дата призыва и воинское звание.
Для того чтобы объединять данные из разных источников, используется record linkage, или сопоставление данных. Сопоставление данных отвечает на вопросы, которые касаются объединения баз, приведения их записей к единому формату и поиску пересечений внутри их.
Например, среди этих вопросов могут быть следующие:
— «Дж. Смит из Хартфорда» и «Джозеф Смит, шт. Коннектикут» — это один и тот же человек?
— Считаем ли мы «Роберта» и «Боба» одной и той же сущностью?
— Как можно отлавливать многочисленные опечатки в несовершенных базах данных?
Не на все вопросы, связанные с сопоставлением данных, можно найти единственный верный ответ, но сама постановка их помогает работать с базами, в которых могут находиться тысячи и миллионы людей.
От старых переписей к машинному обучению
Ещё в первой половине XX века учёных заинтересовали переписи населения: они содержали большое количество записей, и, что немаловажно, многие из этих записей повторялись и относились к одним и тем же людям. Это позволяло изучать историю повседневности и отслеживать события из жизни обычных людей. Ещё в 1935 году Джеймс Малин сравнил результаты 13 переписей населения Канзаса (с 1860 по 1935 годы), анализируя миграцию внутри Соединенных Штатов.
В 1946 году в статье врача и статистика Хальберта Данна появляется термин «record linkage». Уже в 1969 выходит одна из ключевых статей по этой задаче, «Теория сопоставления данных» Ивана Феллеги и Алана Сантера. В этой работе представляется уже «компьютерно-ориентированный подход»: учёные предлагают математическую модель для того, чтобы связывать сущности из разных датасетов. Предполагается, что в каждом датасете у сущности есть несколько характеристик (имя, адрес, год рождения и т.п.). Методы, предлагаемые в статье, актуальны даже в век машинного обучения: например, экономящие вычислительные затраты «блокеры» (когда совпадения ищутся только внутри определенной группы, например, среди людей из одного штата) или пороговые значения, отделяющие более вероятные кандидатуры на совпадение от менее вероятных.
Сейчас методы сопоставления данных по-прежнему чаще всего используются в задачах, исследующих большие группы людей: например, участников выборов.
Методы сопоставления данных
Вкратце опишем самые распространенные методы сопоставления данных. Если вы захотите ознакомиться с ними подробнее, можно прочесть, например, статью об истории record linkage за последние 80 лет. Здесь — лишь краткий обзор.
Детерминистический
Этот метод — самый простой и понятный интуитивно. Он хорошо подходит для проверки начальных теорий.
Допустим, у вас есть два датасета A и B, они достаточно похожи друг на друга (например, относительно близкие по времени переписи) и содержат качественные данные. Тогда можно просто выбрать несколько ключевых атрибутов и считать совпадениями все случаи, когда эти атрибуты совпадают.
Проще всего, когда один из этих атрибутов заведомо уникален — например, номер социального страхования, но и комбинация «ФИО + дата рождения + город рождения» может на чистых данных сработать весьма неплохо.
Вероятностный
Допустим, у нас все еще есть датасеты A и B, но данные в них не настолько чистые или же они представлены в разных форматах. Тогда могут понадобиться более сложные способы сопоставления данных (например, нечёткое сравнение, когда мы можем закрывать глаза на опечатки). Совпадением в этом случае считается, когда количество пересечений по разным атрибутам превысит определенное исследователем пороговое значение.
При этом, когда мы будем рассчитывать вероятность совпадения, мы используем разные веса для разных атрибутов — например, совпадение месяца рождения не так важно, как совпадение фамилии (атрибута с большим количеством уникальных значений). Здесь же могут пригодиться и блокеры, о которых мы говорили ранее. Классическим алгоритмом всё ещё считается предложенный Феллеги и Сантером алгоритм Феллеги-Сантера.
Машинное обучение goes brrrr
Если у нас есть возможность предварительно разметить достаточно большое количество совпадений на верные и неверные, можно будет использовать и методы машинного обучения. Работа с классификацией данных для задачи Record Linkage не отличается принципиально от любых других задач классификации в машинном обучении: на вход поступает пара записей (из первой базы и из второй) и модель предсказывает, является ли это совпадение истинным или ложным.
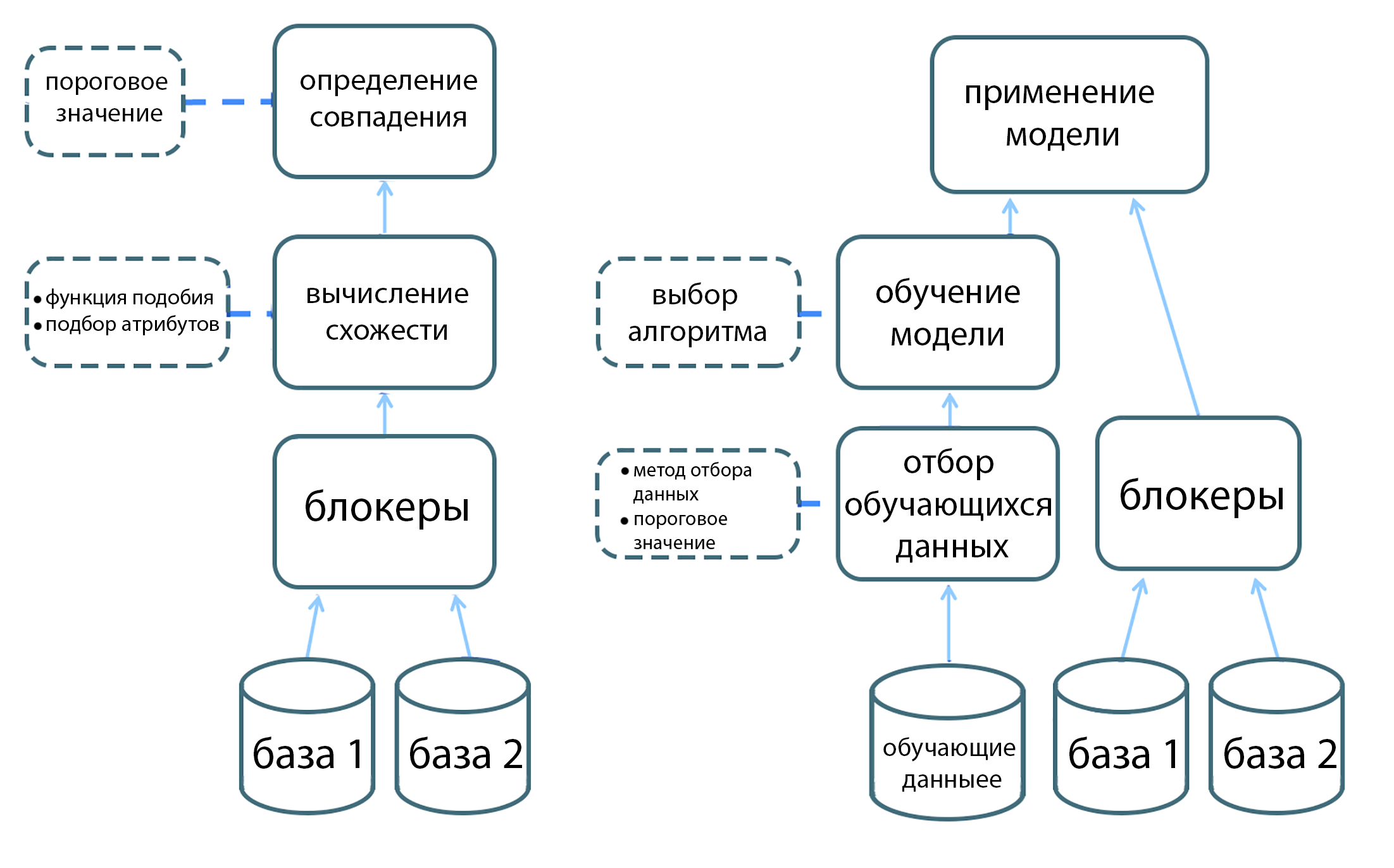
Поскольку подготовка датасета для такой задачи — достаточно трудоёмкое дело, возможно сочетать статистические методы, не требующие размеченных данных, с машинным обучением. Например, первоначальный датасет готовится на основе статистического инструмента и только затем проверяется вручную человеком, что может ускорить процесс работы.
Кроме того, высокие результаты показывает комбинированный подход: сочетание автоматических методов и последующая проверка данных с помощью разметчиков-людей.
Как можно применять сопоставление данных?
Анализ внутренней миграции в США
В США есть большие базы данных, хранящие информацию об избирателях. Если сопоставить данные за разные годы, можно проанализировать распространенные маршруты миграции граждан страны из одного штата в другой.
В статье Using a Probabilistic Model to Assist Merging of Large-Scale Administrative Records исследователи из Принстона и Гарварда сравнили данные избирателей за 2014 и 2015 год и оценили, какие штаты наиболее привлекательны для переезда, а из каких люди, наоборот, уезжают.
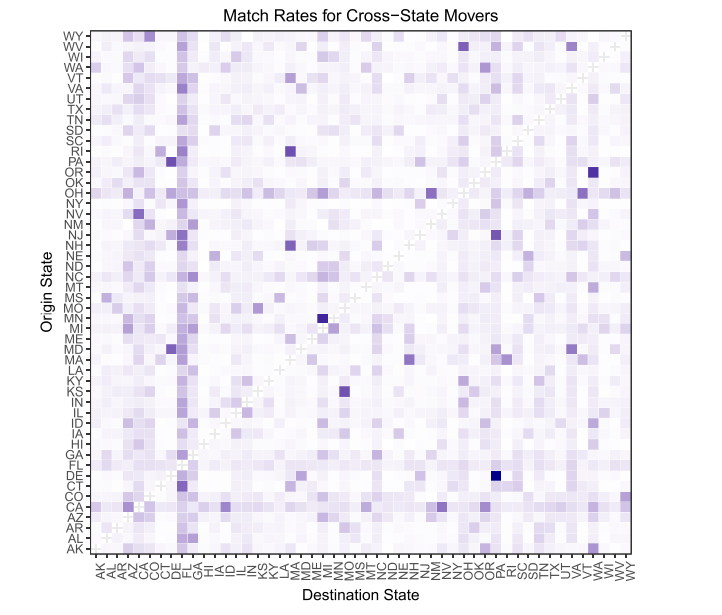
Например, выделяющаяся горизонтальная черта в верхней половине диаграммы показывает большое число жителей, уезжающих из штата Огайо.


Среди штатов, наиболее популярных для переезда, есть, например, Флорида — по предположению авторов статьи, это может быть связано с тёплым климатом, привлекательным для пожилых граждан.
Обогащение отдельных биографий в исторических исследованиях
Кроме обобщенной статистики, сопоставление результатов из разных баз может расширить наши знания на микроуровне отдельных биографий. Архивные данные из различных источников позволяют более подробно реконструировать биографии отдельных участников исторических событий. В данном случае сопоставление данных выступает скорее вспомогательным инструментом, позволяющим сузить поле поиска потенциально интересных кейсов.
Один из таких примеров — исследование командой ВШЭ связей между базой участников войны ОБД «Мемориал» и базой материалов советских судебных процессов против коллаборационистов из архива Мемориального музея Холокоста.
Автоматически было найдено 63 пересечения между базами. После проверки вручную из них 40 оказалось подлинными. Большинство из найденных человек выбыло из РККА по причине осуждения, также встречаются такие причины выбытия, как дезертирство и попадание в плен. Тем не менее, есть и более интересные случаи: например, человек числится погибшим в одной базе, но данные из другой позволяют утверждать, что уже после войны он был осужден за сотрудничество с врагом.
Так, Иосиф Алиевич Лебедь (род. 1895) проходил по делу против полицейских Острожского района Ровенской области. Иосиф Лебедь поступил в организованную немцами полицию в июле 1941. В феврале 1944 он был призван в РККА. В ОБД «Мемориал» указано, что Лебедь погиб 7 октября 1944 и похоронен в Чехословакии, с. Канора, в могиле №5 возле церкви. Согласно показаниям Лебедя из материалов дела, в марте 1945 он попал в плен у озера Балатон и оказался в австрийском лагере для военнопленных. 11 мая 1945 Лебедь был освобожден РККА. В августе 1945 он вернулся домой, пройдя через фильтрационный лагерь, а в 1949-1950 допрашивался по делу о коллаборационизме. В базе «Память народа» одновременно указаны «гибель» Лебедя в 1944-м и юбилейное награждение орденом Отечественной войны II степени в 1985-м.
Таким образом, исследование пересечений из разных баз расширяет возможности учёных как на уровне больших данных и анализа общих тенденций, так и в случае с отдельными историями конкретных людей.
Сопоставление данных позволяет нам видеть картину мира более полно, а в некоторых случаях даже находить ошибки, которые мы не смогли бы обнаружить, опираясь только на один источник.
Источники
1. Статья про Record Linkage в Википедии
2. A Theory for Record Linkage
3. Historical Census Record Linkage
4. Using a Probabilistic Model to Assist Merging of Large-Scale Administrative Records
5. На пути к интеграции биографических данных из электронных баз по истории России XX века
6. Big Data and Social Science: Machine Learning Approaches to Record Linkage



