
За последние 30 лет системы машинного перевода прошли несколько этапов развития, причем с каждым новым этапом качество перевода становилось заметно лучше. До начала 90-х годов прошлого века почти все системы опирались на наборы правил. Естественно, эти правила, сколько их ни пиши и ни уточняй, не могли учесть все возможные значения слов и все контексты, в которых они появляются.
Когда ученые из компании IBM предложили статистический метод, который опирался на примеры уже переведенных людьми предложений, многие увидели в таком подходе будущее. Теперь только нужно было найти достаточное количество (лучше миллионы) пар предложений на исходном и желаемом языке и с помощью алгоритмов, предложенных ай-би-эмовцами, автоматически натренировать модель перевода отдельных слов. Эти алгоритмы позволяли сказать для каждой пары предложений, какие именно исходные слова связаны с какими словами в переводе, то есть получить так называемое соответствие слов (word alignment). Вместе с моделью целевого языка, также основанной на существующих текстах, это позволяло переводить слова в контексте, строить перевод, «прыгая» с одного слова в исходном предложении на другое, тем самым пытаясь поставить слова в синтаксически правильном порядке.
В начале двухтысячных эти системы были кардинально улучшены за счет перевода фраз. Фразы для адептов статистического машинного перевода — это просто группы последовательных слов, от одного до (обычно) семи. Фразы позволяли системе запомнить устоявшиеся, часто встречающиеся обороты, то есть, по сути, запомнить контекст. Такие системы довольно сносно переводили предложения, состоявшие из фраз, которые система уже «видела» в данных, использованных для ее обучения. А вот если нужно было перевести что-то малознакомое, то качество перевода сильно падало. Такие системы использовались в онлайн-переводчиках, в первую очередь Google, с момента их появления.
Наконец, в 2014–2016 годах в машинном переводе произошла, можно сказать, революция. Системы, основанные на нейросетях, очень быстро захватили не только умы ученых, но и стали применяться в коммерческих приложениях. Произошло это потому, что качество перевода с помощью нейронных сетей улучшилось настолько, что в некоторых случаях стало трудно отличить перевод, сделанный человеком, от перевода, сделанного компьютером, особенно если смотреть на перевод отдельных предложений.
В чем же суть нейронного машинного перевода? Такие системы тоже тренируются на больших количествах пар предложений, но вот соответствие слов и разбивка на фразы уже не нужны. Система просто пытается сначала закодировать исходное предложение в абстрактный набор чисел — а потом декодировать из чисел слова, но уже на другом языке. «Дочитав» предложение до конца, причем одновременно и слева направо, и справа налево, нейросеть начинает декодировать — и предсказывать слова перевода, причем каждое предсказанное слово используется для предсказания следующего слова. Тем самым для более точного выбора слов для перевода используется контекст всего исходного предложения, а также контекст всех предыдущих предсказанных слов. Именно в этом основное отличие нейронных систем от систем, основанных на отдельных фразах, в которых контекст ограничен предыдущими 4-7 словами. И это более похоже на то, как переводит человек.
В процессе тренировки нейронных систем идет постоянное сравнение каждого предсказанного слова (а значит, наиболее вероятного согласно состоянию модели на данный момент) с «правильным» словом, то есть со словом, которое стоит в этом месте целевого тренировочного предложения. Если предсказанное слово с ним не совпало, то происходит так называемый «апдейт» параметров модели (перераспределение весов в нейросети), который повышает вероятность правильного слова и снижает вероятность слов, которые были определены как наиболее вероятные на этом шаге тренировки. Так повторяется очень-очень много раз. В итоге нейронная система проходит через все миллионы пар предложений, которые обязательно перемешиваются в случайном порядке, 3-4 раза. Алгоритм останавливается, когда дальнейшего улучшения предсказания слов уже не происходит.
Системы нейронного перевода отличаются в основном своими параметрами, а именно в какое количество чисел (говоря строже, в какие вектора и матрицы) кодируются слова на разных этапах, каковы размеры этих векторов и матриц, какими математическими операциями они связаны друг с другом («нейронные» связи, как в мозге человека, здесь в какой-то степени моделируются при помощи линейной алгебры, отсюда и название) и как обеспечивается запоминание важных слов и «забывание» менее важных.
Все современные системы оснащены так называемым «механизмом внимания» (attention mechanism), который при предсказании следующего слова как бы фокусируется на одном или нескольких словах исходного предложения, складывая эту информацию с закодированным полным контекстом. Здесь опять же есть схожесть с поведением человека-переводчика, который тоже обычно сначала читает все предложение, а потом в процессе перевода смотрит на отдельные исходные слова и фразы, либо уже переведенные, либо те, которые еще предстоит перевести.
Механизм внимания в чем-то схож с word alignment (т.е. поиском пословных соответствий в текстах на разных языках), но это внимание «мягкое» — не всегда можно сказать точно, какое именно слово было переведено системой в определенный момент времени, можно только увидеть, какие слова больше других повлияли на предсказание именно этого слова в переводе. Системы с архитектурой последнего поколения, называемой Transformer, имеют несколько уровней такого «внимания», причем не только внимания к исходному предложению, но и к уже частично предсказанному переводу, т.н. self-attention.
Для того чтобы создать с нуля систему нейронного машинного перевода (впрочем, как и для систем статистического перевода), нужно прежде всего несколько миллионов пар предложений, где перевод исходного предложения сделан человеком. Для языков с большим количеством носителей такие данные легко найти даже в свободном доступе. Это, например, переводы дебатов в европейском парламенте на все языки Европейского Союза или перевод всех документов и дебатов в парламенте Канады (именно на этом английско-французском корпусе и добилась первых успехов группа ученых из IBM). В последнее время появились также коллекции предложений и их переводов, подобранных автоматически в интернете с помощью специальных алгоритмов (см. сайт ParaCrawl, например).
Во-вторых, нужна программа для тренировки нейронной сети. Таких программ со свободным кодом также есть немало, но большинство из них основаны на типах данных и нейронных алгоритмах от TensorFlow или PyTorch. Почти все программы написаны на языке Python. Они позволяют задать параметры нейронной сети, параметры обучения, и т.д. Определение подходящих параметров требует хороших знаний в области машинного обучения, теории вероятности и статистики, а также линейной алгебры и математики в целом.
Знания компьютерной лингвистики нужны для того, чтобы хорошо выбрать форму представления слов и предложений в нейронной сети. Каждое слово кодируется в вектор из действительных чисел измерением 600-1000. В процессе тренировки система сама обучается тому, что определенные измерения имеют свою внутреннюю семантику. Например, векторы для слов «король» и «короли» могут быть похожи, то есть расстояние между ними в многомерном пространстве таких векторов будет не очень большое («Системный Блокъ» рассказывал об этом здесь и здесь). В некоторых других измерениях, скорее всего, близки окажутся слова «король» и «царь». В научной литературе можно также найти примеры, в которых из вектора для слова «королева» вычитается вектор слова «король», результат прибавляется к вектору слова «царь», а в итоге получается вектор, расположенный очень недалеко от вектора для слова «царица».
Все эти семантические связи и позволяют нейронным системам эффективно запоминать и производить переводы, используя синонимы и вообще слова, которые они нигде не видели во время обучения в «человеческом» переводе слов из данного предложения. Это еще одно их существенное отличие от систем статистического перевода, основанного только на «заученных» словах и фразах. Однако хорошо научиться этим семантическим связям система может только тогда, когда она достаточно часто видела эти слова во время обучения. Поэтому нейронные системы часто ошибаются в переводе редких слов — рассчитанные для них векторы просто недостаточно надежны.
Чтобы уменьшить количество редких слов, а также чтобы уметь (или пытаться) переводить совершенно незнакомые слова, используются алгоритмы разделения слов на части, так, чтобы каждая часть достаточно часто встречалась в корпусе. Таким образом, система учится переводить целые частые слова (например, 10 тысяч самых частых слов языка) и фрагменты менее частых слов. Это также помогает сделать систему более быстрой. При предсказании каждого следующего слова перевода система всегда должна просто рассчитать вероятность для каждого слова целевого языка из ее словарного запаса, чтобы выбрать самое вероятное слово. При использовании фрагментов слов эта вероятность рассчитывается 20 или 50 тысяч раз, а не 200 или 300 тысяч, если речь идет обо всех словах языка.
Для тренировки системы нейронного перевода нужен мощный компьютер с одной или несколькими графическими картами последнего поколения, специально предназначенными для быстрых операций с векторами и матрицами. Обучение системы длится от одного дня до недели и более, в зависимости от количества тренировочных пар предложений и параметров сети. Для использования уже обученной нейронной системы перевода также рекомендуется графическая карта, так как тогда скорость перевода возрастет с 10-30 слов в секунду до 300 и более слов в секунду.
Хотя перевод нейронных систем может быть достаточно хорошего качества, есть еще немало проблем, которые предстоит решить ученым и разработчикам.
Во-первых, как уже было сказано, проблема перевода редких слов остается даже при переводе слова по частям. Более того, такой перевод иногда приводит к тому, что система начинает выдумывать новые слова, а еще часто коверкает имена людей и названия, с которыми не сталкивалась в процессе обучения.
Во-вторых, иногда хорошая структура перевода, плавность языка может так «усыпить» читателя или редактора перевода, что серьезная ошибка в переводе останется незамеченной. В итоге даже очень важные слова, могут остаться непереведенными из-за несовершенства механизма внимания, или быть переведенными неправильно только потому, что такой перевод в сочетании с другим словом образует часто встречающуюся фразу в целевом языке.
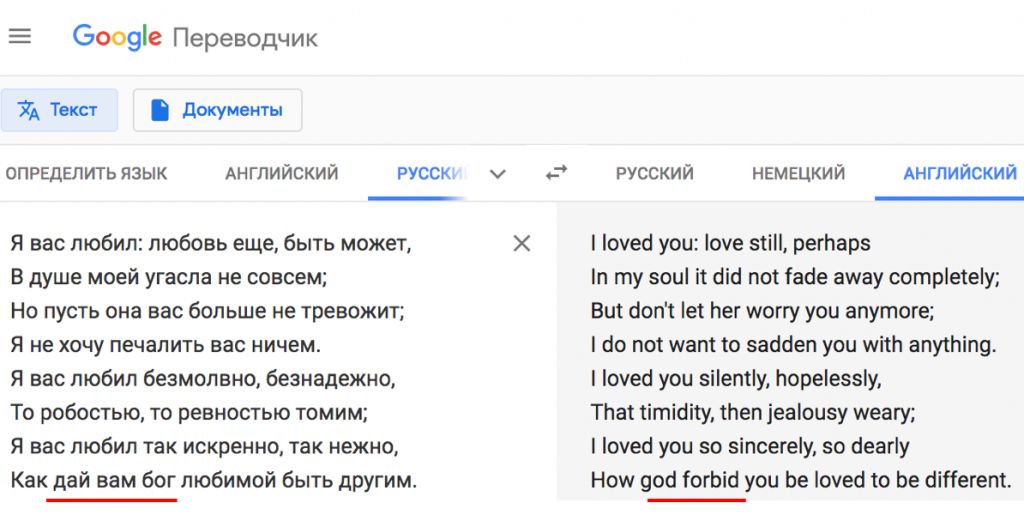
Кроме того, на очень «тяжелых», необычных текстах система может вообще «растеряться», пытаясь произвести что-то, что хорошо звучит в целевом языке, но имеет мало отношения к тому, что было в исходном предложении (что-то вроде «the decision of the decision», с повторами слов.)
Наконец, почти все современные системы переводят предложения в отрыве друг от друга, не используя контекст всего документа. В некоторых случаях это приводит к ошибкам в переводе глагольных форм («я сказал» или «я сказала», например) или местоимений (особенно при переводе с романских языков на английский). Появляется много исследований на эту тему, но пока я не видел особенно успешных систем, которые бы хорошо использовали контекст из других предложений. При этом все системы с попыткой учета контекста работают намного медленнее, и это является барьером для их коммерческого внедрения. Но сам факт, что хорошего перевода отдельных предложений пользователям уже часто недостаточно, говорит о том, что машинный перевод нуждается в выходе на новый уровень качества.
По состоянию на начало 2019 года системы нейронного машинного перевода используются основными онлайн-переводчиками (Google Translate, Bing от Microsoft, DeepL, Amazon Translate, Yandex Translate). Однако основные клиенты компаний, разрабатывающих такие системы — это другие компании и государственные организации, а не отдельные пользователи. Государствам чаще всего нужен перевод сносного качества, который они используют без редактирования для поиска в нем нужной информации (например, для борьбы с терроризмом). Крупные компании, предоставляющие услуги переводчиков, в том числе фрилансеров, используют нейронный машинный перевод с последующим редактированием, что после некоторой фазы адаптации переводчика к системе приводит к увеличению производительности труда примерно на 20-30%, а то и более.
Системы нейронного перевода легко можно адаптировать к определенной тематике: достаточно продолжить обучение уже натренированной системы в течение нескольких итераций на парах предложений, связанных с этой тематикой, например, на содержимом памяти переводов (Translation Memory). Это позволяет быстро создавать кастомизированные системы не только для отдельной тематики, но и для конкретных переводчиков. Системы нейронного перевода также востребованы в медиаиндустрии, где они могут быть использованы для создания субтитров, в том числе в тандеме с автоматическими системами распознавания речи.
Основная проблема распространения систем нейронного перевода на большее количество языковых пар — недостаток параллельных корпусов для обучения редким языковым парам. Причем редкие они не всегда из-за количества носителей (их могут быть десятки и сотни миллионов), а из-за того, что в письменном и особенно оцифрованном виде существует очень мало документов на этих языках и их переводов. Примеры таких языков: пушту, урду, другие индо-пакистанские языки в сочетании с английским. На таких редких языковых парах статистические системы, использующие фразы все еще опережают нейронные системы по качеству (в целом довольно низкому).
Чтобы исправить ситуацию, используются так называемые мультилингвальные нейронные системы, которые обучаются на смешанных корпусах сразу на нескольких исходных или даже целевых языках. Тем самым редким языкам с малым количеством данных для обучения помогает их частичное сходство с более употребительными языками, в одной системе с которыми происходит обучение. В случае нескольких целевых языков часто достаточно псевдослова, которое указывает, на какой язык система должна перевести данное предложение. Это слово вставляется автоматически как первое слово в исходном предложении и не видно пользователю, но именно оно и настраивает систему на перевод на нужный язык. Мультилингвальные системы могут без проблем перевести и предложения на смеси языков, например, русского и белорусского.
Наконец, еще одна проблема, которая, однако, может быть решена — это зависимость нейронных сетей от типа данных, на которых они тренируются. Так, если тренировать нейронный перевод только на длинных парах предложений (от 20 слов каждое), то система будет неспособна перевести короткое предложение или даже отдельное слово. У меня в практике был случай, например, что междометие «eh» система перевела как «не знаю что сказать». Поэтому нужно обязательно в случайном порядке «подсовывать» системе и слова из словаря с переводом, и отдельные фразы; и цифры (номера телефонов, например), и имена, и смайлы из скобок, чтобы она научилась их копировать без потерь. Короткие и длинные предложения, с точкой в конце и без нее. Попробуйте сейчас поставить или не поставить точку в конце предложения в Google Translate и, как говорится, почувствуйте разницу. Как показывает практика, всё это мало влияет на общее качество перевода (часто определяемого автоматически с помощью таких метрик как BLEU, которые сравнивают перевод системы с профессиональным переводом), но зато для конечных пользователей все эти знаки препинания в нужном месте и в нужном виде, правильные переводы имен, и т.д. имеют очень большое значение. И задача коммерческих разработчиков систем нейронного перевода, таких как компания, в которой я работаю, — не только разрабатывать и внедрять нейронные технологии, а и искать прагматические решения для таких вот проблем «маленького человека».
Евгений Матусов, ведущий разработчик систем машинного перевода компании AppTek



