
Будьте добры, помедленнее, я записываю — именно такими словами могла бы обратиться к пользователю «начинающая» система распознавания речи. Успешность распознавания напрямую связана со скоростью речи, количеством и длительностью наблюдаемых в ней пауз. Чем четче и медленнее человек диктует запрос, тем выше вероятность получения желаемого результата. Но если нужно сохранить конфиденциальность запрашиваемых данных или что-то выяснить, пока едешь в метро, придется воспользоваться клавиатурой или ручным поиском.
Как это работает?
Научить машину распознаванию можно либо с помощью сравнения с эталоном, либо методом контекстно-зависимой классификации («узнавания» отдельных мелких элементов, которые складываются в полноценные слова).
В первом случае в память устройства закладывается некоторый объем исходных примеров. Во втором на помощь приходят методы дискриминантного анализа и марковские модели (оба метода основаны на статистике), а также нейронные сети.
Вариант 1: действуем по шаблону
Для того чтобы понять, как работает метод сравнения с эталоном, надо понимать, как работает анализ закрытых грамматик и встроенных грамматик.
Распознавание закрытых грамматик
Вопрос системы: «На какой месяц вы планируете поездку?»
Ответ человека: «Август».
В этом случае анализируется ответ, соотносящийся с ключевым словом («месяц»). База соответствий этому слову включает двенадцать наименований; система ожидает, что человек выберет нужное и произнесет его в именительном падеже. Если вместо «Август» пользователь ответит «В августе», могут возникнуть затруднения.
Распознавание встроенных грамматик
Вопрос системы: «В какое время вы хотите записаться к терапевту?»
Ответ человека: «14:25».
В систему, работающую со встроенными грамматиками, уже заложено большинство необходимых значений, поэтому она работает с семантикой и темой ответа. Обратите внимание, что в этом примере пользователь не называет «ровное» время — и, следовательно, ожидает, что устройство не запишет его на два или половину третьего.
Вариант 2: ищем ключевые слова и взаимосвязи
Контекстно-зависимая классификация связана с открытыми грамматиками. Посмотрим на пример диалога:
Вопрос системы: «Что вас интересует?»
Ответ человека: «Как подать документы на химический факультет МГУ?»
В подобном запросе будут важны «как» (а не «когда»), «подать» (а не «забрать»), «химический» (а не «физический») и «МГУ» (а не «МГИМО»). Система должна будет оценить все слова запроса или команды и учесть их взаимосвязь.


Распознавание производится в несколько этапов. Одна и та же фраза, произнесенная разными людьми в разной обстановке, может быть воспринята системой по-разному.
На первом этапе оценивается зашумленность сигнала и происходит его очистка от нежелательных частот. Если модуль шумоочистки не срабатывает (например, в метро), остальные шаги оказываются бессмысленны — как бы естественно ни общалась с вами та же Сири, вслушаться в гул метро у нее просто не получится.
Следующей вступает в игру акустическая модель — она оценивает, насколько произнесенное человеком слово совпадает с существующим в памяти устройства. Эта модель основана на статистике звукоупотреблений. В «алфавит» звукоупотреблений входят ограниченное количество звуков конкретного языка и их сочетания: «с» в словах «Саша» и «сделать» будет звучать по-разному.
На более сложном уровне речи — уровне фраз и предложений — работает языковая модель, отвечающая за оценку встречаемости тех или иных конструкций. Эти модели различаются в зависимости от особенностей языка, на материале которого они используются.
Для агглюнативных языков, в которых слова образуются в результате «склеивания» множества морфем, имеющих свое собственное строго зафиксированное значение, лучше сработает чистая статистика. К агглютинативным языкам относятся, например, татарский, казахский языки.
Для флективных языков, в которых развито словоизменение с помощью окончаний (флексий) и в которых встречается много форм одного и того же слова, придется учитывать встречаемость, данные о частеречной принадлежности, а также общие грамматические правила (см. пример про химфак МГУ). Русский язык относится к флективным языкам.
Акустические и языковые модели выделяют и вычисляют признаки, характеризующие речь говорящего. Финальный этап распознавания — декодирование.
На основе сделанных вычислений декодеры выносят окончательное решение, какая последовательность слов с наибольшей вероятностью была произнесена говорящим — она-то и будет обработана как запрос или команда, поступившие через голосовой ввод.
Находка для шпиона
Для распознавания устной речи необязательно говорить что-то вслух: одна из новых разработок — интерфейсы безмолвного доступа (SSI, silent speech interfaces), системы, распознающие речевые сигналы на самой ранней стадии артикулирования.
Движения лицевых мышц несут информацию о том, что именно мы произносим. Стоящий около вас на концерте скорее будет полагаться на движения ваших губ, чем попытается расслышать ваши слова. Регистрация мышечных электрических импульсов позволяет с достаточно точно распознавать сразу несколько десятков слов. Этого хватит, например, чтобы подавать команды в сильно зашумленном помещении заводского цеха — или обмениваться секретной информацией так, чтобы никто из окружающих этого не узнал!
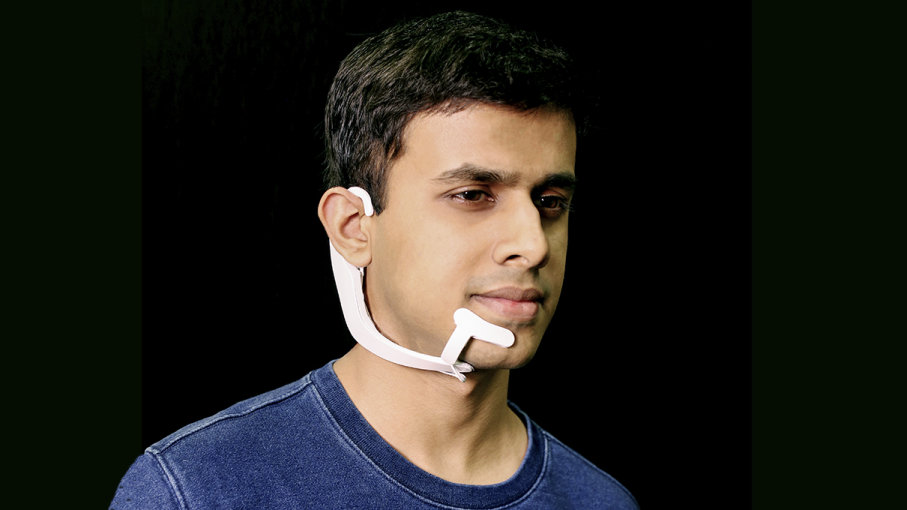
Весной 2018 года модель под названием AlterEgo представили в Массачусетском технологическом институте (MIT). В серии экспериментов с десятью добровольцами удалось добиться 92% распознаваемости. Ученые обещают, что скоро этот показатель вырастет еще на несколько пунктов. Устройства типа SSI должны сильно облегчить жизнь не только тем, кто хотел бы повысить эффективность взаимодействия с техникой, но и пожилым людям, людям с пониженным слухом и тем, кто перенес операции на связках.
Говорить о том, что машина сможет заменить человека в создании и понимании действительно сложных текстов, еще очень рано — но она уже совершенно точно готова выслушать тех, кто в этом нуждается.
Источники
- Узнать о разработках MIT можно здесь: New MIT Headset Can ’Hear’ Your Thoughts and Respond.
- Вот тут подробное объяснение работы Марковских моделей от специалистов из Кембриджа.
- В статье на Гитхабе описаны разнообразные типы дифонных, трифонных и других сочетаний, входящих в «алфавит» системы распознавания речи.
- Читать по теме: Кто это сказал? Разбирается Google AI, Рождение говорящих машин



