
Мы уже рассказывали о языковых моделях BERT и GPT-2. Теперь разбираемся, как работает еще одна огромная нейросетевая языковая модель: UniLM от Microsoft. Чтобы лучше понять эту статью, мы рекомендуем сначала прочитать наши материалы об устройстве нейросетей-трансформеров: «Как работают трансформеры» и «Нейросети-трансформеры изнутри»
Как устроена UniLM
UniLM расшифровывается как Unified pre-training Language Model. По архитектуре это многослойный трансформер, предварительно обученный на больших объемах текста. Подобно BERT, предварительно обученный UniLM можно тонко настроить (с необходимыми дополнительными слоями для конкретных задач) для адаптации к различным задачам — по-английски это называется fine-tuning. Но в отличие от BERT, которая используется в основном для задач понимания естественного языка (NLU, Natural Language Understanding), UniILM может использоваться как для задач NLU, так и для задач генерации естественного языка (NLG, Natural Language Generation).
Для предобучения модели был разработан набор задач завершения или дополнения (т.н. «cloze task»), где слово прогнозируется на основе его контекста. Задачи дополнения отличаются способом задания контекста.
Обычно для обучения нейросетей используются три типа задач языкового моделирования (LM, Language Model): однонаправленная LM, двунаправленная LM, sequence-to-sequence LM.
UniLM отличается от других трансформеров тем, что здесь происходит единый процесс обучения и используется одна языковая модель Transformeк с общими параметрами и архитектурой для различных видов моделирования. Сеть не нужно отдельно обучать каждой задаче и отдельно хранить результаты ее обучения. Использование общих параметров для разных задач позволяют делать представления текстов более универсальными и совместно оптимизировать их для разных задач обработки естественного языка. Перенастройка с одной задачи на другую также происходит быстрее и легче.
Как обучается UniLM
Как обычно, на вход модели подаются последовательности слов. Для однонаправленной LM это один сегмент, для двунаправленной или модели sequence-to-sequence — пара сегментов. К сегментам всегда добавляются маркеры начала последовательности и конца последовательности ([SOS], start of the sentence) и ([EOS], end of the sentence). [EOS] не только помечает границу предложения в задачах NLU, но также используется, чтобы узнать, когда завершить процесс декодирования в задачах генерации естественного языка (NLG).
Представление текста в UniLM такое же, как в BERT: сначала текст токенизируется, для этого используется алгоритм WordPiece: текст делится на ограниченный набор «подслов», частей слов. Для каждого входного токена его векторное представление вычисляется путем суммирования эмбеддингов токена, позиции и сегмента (эмбеддинг — это числовое представление слова, слога или буквы, основанное на частотностях его контекстов, подробнее мы писали в статье про BERT).
Во время обучения из входной последовательности токенов случайным образом выбираются некоторые токены и заменяются на специальный токен [MASK]. Затем контекстное представление выбранных токенов, полученное посредством многослойного трансформера, передается в классификатор для восстановления замаскированного токена. В этом смысле UniLM снова повторяет BERT.
Каким образом вычисляется контекстное представление токенов? Входные векторы сначала собираются, а затем кодируются трансформером из L слоев. В каждом блоке трансформера используются несколько голов внутреннего внимания (self-attention, см. нашу статью о механизме внимания в нейросетях) для агрегации выходных векторов предыдущего слоя. Некоторые токены маскируются, то есть заменяются токеном [MASK], чтобы их не учитывали в вычислении представления текущего токена. Для маскировки применяется матрица масок. Для различных задач языкового моделирования используются различные матрицы масок.
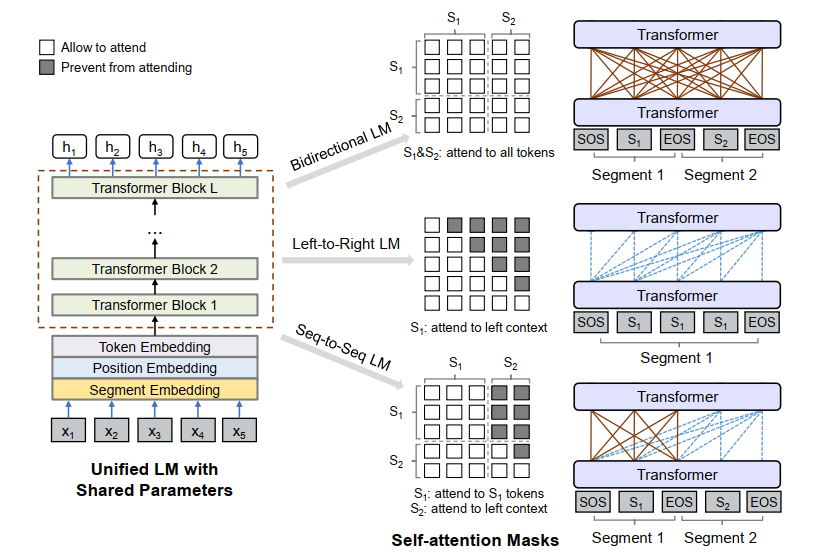
Однонаправленная LM. Используются как left-to-right так и right-to-left задачи языкового моделирования. К примеру, в left-to-right модели для каждого токена при вычислении контекстного представления используются только левые контекстные токены и сам токен. Например, чтобы предсказать замаскированный токен «x1×2 [MASK] x4», используются только токены x1 и х2 и замаскированный токен. Это делается с помощью треугольной матрицы масок в self-attention (где элементы в верхнем треугольнике матрицы self-attention равны ♾, а остальные 0, как показано на рисунке 1).
Двунаправленная LM. Контекстная информация кодируется в обоих направлениях и может генерировать лучшие контекстные представления текста, чем ее однонаправленный аналог. Матрица маски в self-attention M представляет собой нулевую матрицу.
Sequence-to-sequence LM. На рисунке 1 показано, что при генерации токена участвуют все токены из первой последовательности (источника), а из второй (целевой) последовательности берутся только токены слева от целевого токена и сам целевой токен. Например, пусть задана последовательность источник t1t2 и его целевая последовательность t3t4t5, то есть на вход подается «[SOS] t1 t2 [EOS] t3 t4 t5 [EOS]». Хотя оба t1 и t2 имеют доступ к первым четырем токенам, включая [SOS] и [EOS], t4 доступны только первые шесть токенов.
На рис. 1 показана маска M self-attention, используемая для Sequence-to-sequence LM. Элементы в левой части M равны 0, чтобы при вычислении учитывать все токены первого сегмента, элементы в верхней правой части же приравнены к для блокировки внимания от исходного сегмента к целевому сегменту. Кроме того, для нижней правой части, элементы верхней треугольной части приравнены к , а другие элементы — к 0, таким образом, для токенов в целевой последовательности блокируются токены, расположенные справа от них.
Целью обучения является объединение различных типов задач языкового моделирования, описанных выше. В частности, внутри одной обучаемой части 1/3 времени используется двунаправленная задача языкового моделирования, 1/3 времени используется sequence-to-sequence задача языкового моделирования, и на обе задачи left-to-right так и right-to-left приходится по 1/6 времени.
Архитектура UniLM соответствует архитектуре BERTLARGE. UniLM имеет 16 голов внимания и состоит из 340M параметров. UNILM инициализируется BERTLARGE, а затем обучается на английской Wikipedia и BookCorpus.
Размер словаря — 28 996 токенов, максимальная длина входной последовательности — 512. Вероятность маскирования токена составляет 15%. В процессе маскирования токенов, в 80% случаев токен заменяется на [MASK], в 10% случаев — на случайный токен, для остальных случаев сохраняется оригинальный токен. Кроме того, в 80% случаев маскируется один токен в 20% случаев маскируется биграмма или триграмма.
Процедура обучения состоит из 770 000 шагов, это примерно 77 часов с использованием 8 видеокарт Nvidia Telsa V100 32 ГБ GPU.
Результаты работы UniLM
1. UniLM для автоматического реферирования
Создатели UniLM оценивали, можно ли применить модель для задачи автоматического реферирования — генерации краткого резюме входного текста. В качестве входных данных использовался набор данных CNN / DailyMail и корпус Gigaword для тонкой настройки модели и оценки. Оба набора данных состоят из статей (к примеру, новостей) и кратких содержаний этих статей. В этой задаче применялась тонкая настройка UniLM как sequence-to-sequence модели.
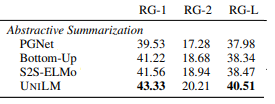
По итогам сравнения разработчики утвеждали, что UniLM превосходит все имеющиеся на тот момент системы автоматического реферирования. Ниже приведены результаты сравнения с помощью метрики ROUGE, которая оценивает адекватность сгенерированного текста подсчитыванием количества совпавших n-грамм в сгенерированном резюме и в резюме, которое подавалось на вход модели.
2. Ответы на вопросы (Question Answering)
Задача состоит в том, чтобы ответить на вопрос с учетом отрывка текста. Есть два варианта этой задачи. Первый называется извлекающим QA, где в качестве ответа надо найти текстовый интервал в заданном отрывке. Другой называется генеративным QA, где ответ должен быть сгенерирован.
Эксперименты проводились на двух наборах Stanford Question Answering Dataset (SQuAD) 2.0 и Conversational Question Answering (CoQA). Эксперименты показали, что при генерации ответов и генерации вопросов UniLM по качеству превосходит результаты наилучших на момент проведения экспериментов моделей: Seq2Seq и PGNet.
Для задач определения качества понимания обобщенного языка, GLUE, модель UNILM показывает результаты, сравнимые с BERT LARGE.
Несмотря на то, что архитектура UniLM подходит для решения различных задач языкового моделирования, для конкретной задачи по-прежнему требуется точная настройка согласно набору данных, характерных для этой задачи (перевод, ответы на вопросы, суммаризация текста, определение логического следования одного текста из другого и др.). В таком наборе для донастройки хорошо иметь сотни, а лучше тысячи примеров. Это ограничивает применимость языковой модели в практических целях: к примеру, для исправления грамматики или генерации рецензии к короткому рассказу трудно собрать набор дообучающих данных.
Нередко случается, что большие предобученные модели не могут быть обобщены для более узкоспециализированных задач. Поэтому появляются модели, для обучения которых используют метод контекстного обучения. На вход предварительно обученной языковой модели подается описание задачи: для модели определяется условие на естественном языке и / или приводится несколько примеров, и затем ожидается, что модель выполнит последующие задачи, просто предсказав, что будет дальше. Одна из таких моделей — GPT-3, и о ней мы расскажем в следующей статье.
Источники
- Unified Language Model Pre-training for Natural Language Understanding and Generation.
- Language Models are Few-Shot Learners.
Дополнительные ссылки:
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
- Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation.
- Get To The Point: Summarization with Pointer-Generator Networks.
- A neural attention model for abstractive sentence summarization.
- Generating long sequences with sparse transformers.
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.
- The LAMBADA dataset: Word prediction requiring a broad discourse context
- Improving Neural Machine Translation Models with Monolingual Data.
- Hector Levesque, Ernest Davis, and Leora Morgenstern. The Winograd schema challenge. In Thirteenth International Conference on the Principles of Knowledge Representation and Reasoning, 2012.
- WinoGrande: An Adversarial Winograd Schema Challenge at Scale.
- Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge.
- UnifiedQA: Crossing Format Boundaries With a Single QA System.
- QuAC : Question Answering in Context.

