
«Что такое корпус — это тексты
Тексты и немножечко разметки…»
ДДТ
Лингвистический корпус — это внушительная коллекция специальным образом размеченных текстов, собранная для исследования языка. Если раньше для поиска эмпирического материала лингвисты самостоятельно обрабатывали огромное число текстов и порой все равно не могли собрать репрезентативное количество данных, то с появлением корпусов эта задача упростилась, а работа ускорилась на порядки.
Чтобы поиск текстовых данных в корпусе происходил максимально быстро и удобно, для каждого корпуса создается специализированная система поиска и определенная разметка. Разметка может быть грамматической, семантической и метатекстовой и представляет собой набор различных тегов, приписываемых каждому слову или предложению в целом. Система поиска в свою очередь позволяет искать размеченное слово.
Параллельные корпуса
Сейчас существует множество видов лингвистический корпусов, один из которых — параллельный. Параллельный корпус — это корпус, состоящий из оригинального текста и его переводов на другие языки. Такой корпус может состоять из одной или нескольких языковых пар.
Параллельные корпуса в первую очередь нужны переводчикам в качестве справочного материала, лингвистам для исследований в области типологии, лингвокультурологии и прикладной лингвистики, преподавателям для поиска аутентичных примеров и, конечно, людям, изучающим иностранные языки.
Корпуса в паре с русским языком представлены в том числе в НКРЯ (Национальном корпусе русского языка). Сейчас там находятся 15 корпусов, причем четыре с восточными языками: хинди, бурятским, корейским и китайским. В этой статье мы расскажем про Русско-китайский параллельный корпус — масштабный проект, созданный учеными и студентами из российских и китайских университетов.
История русско-китайского корпуса
Русско-китайский параллельный корпус появился в 2016 году в составе подкорпуса НКРЯ как проект Института русского языка им. Виноградова, РГГУ, ВШЭ и Хэйлунцзянского университета. Позже над корпусом стали работать студенты-китаисты, лингвисты и программисты из ВШЭ, в 2019 у корпуса появился второй сайт, а в 2020 году проект получил студенческий грант.
Помимо указанных выше участников нынешний коллектив состоит из студентов, преподавателей и научных сотрудников из Института проблем передачи информации им. А.А. Харкевича (ИППИ РАН), МГУ, МФТИ, СПбГУ, Института лексикографии Хэйлунцзянского университета и Института иностранных языков Чжэцзянского университета. Российская команда работает над улучшением интерфейса корпуса, выравниванием файлов и разработкой автоматических алгоритмов обработки текста. Китайская команда занимается выравниванием, а также поиском текстов и проверкой алгоритмов. Главный координатор проекта — Кирилл Семенов. Полный список участников опубликован на сайте корпуса.
Русско-китайски корпус сейчас
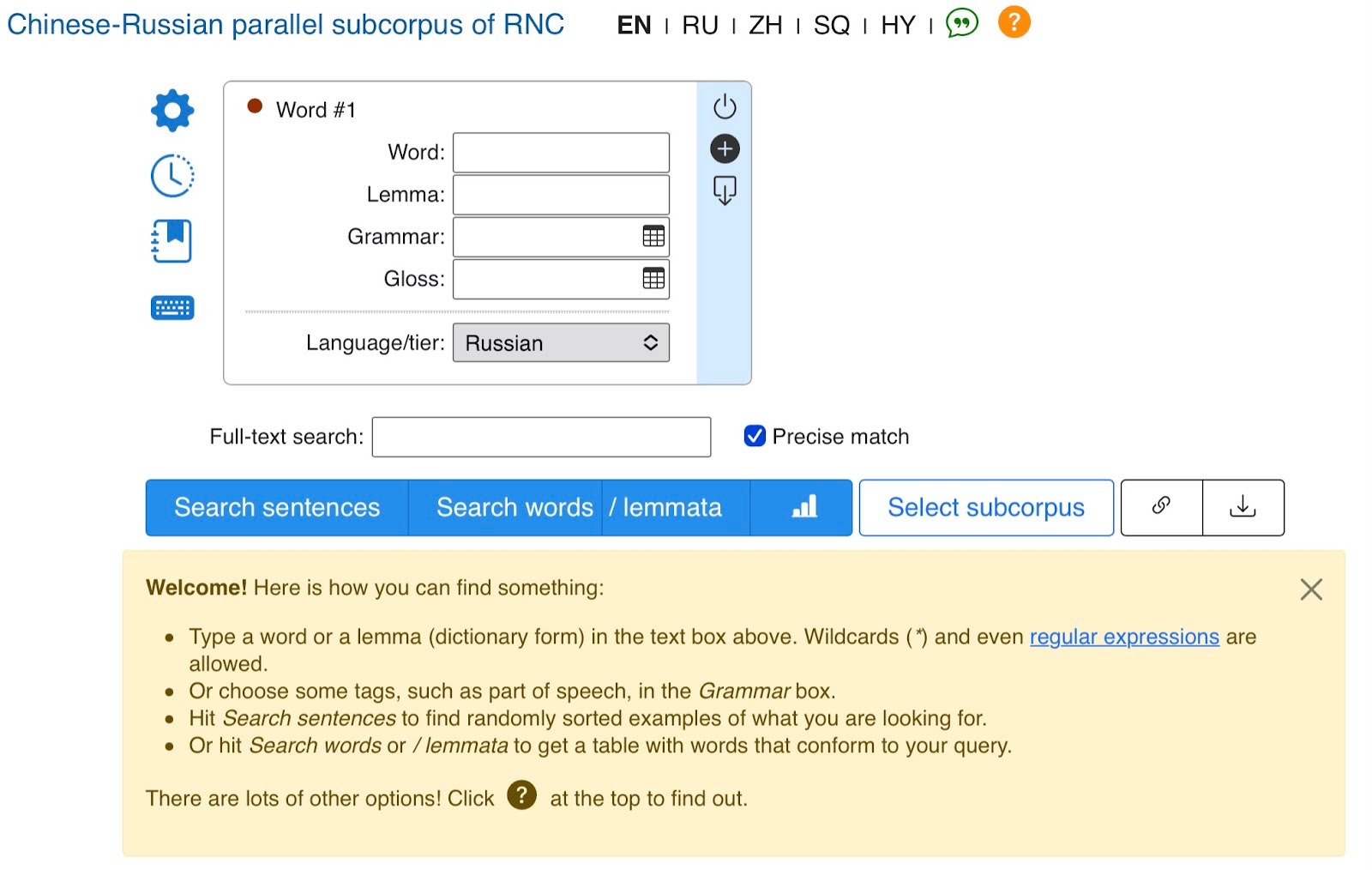
На данный момент корпус состоит из чуть менее 4,5 миллионов слов и более тысячи документов, большая часть которых — художественные тексты русских и китайских авторов XIX-XXI вв., публицистические и новостные статьи из российских и китайских газет, деловые переписки и официальные документы. Все тексты распределены по подкорпусам, что позволяет задавать гибкий диапазон поиска: от работ определенного автора, жанра и периода вплоть до конкретного произведения. На сайте НКРЯ окно выбора подкорпуса выглядит так:
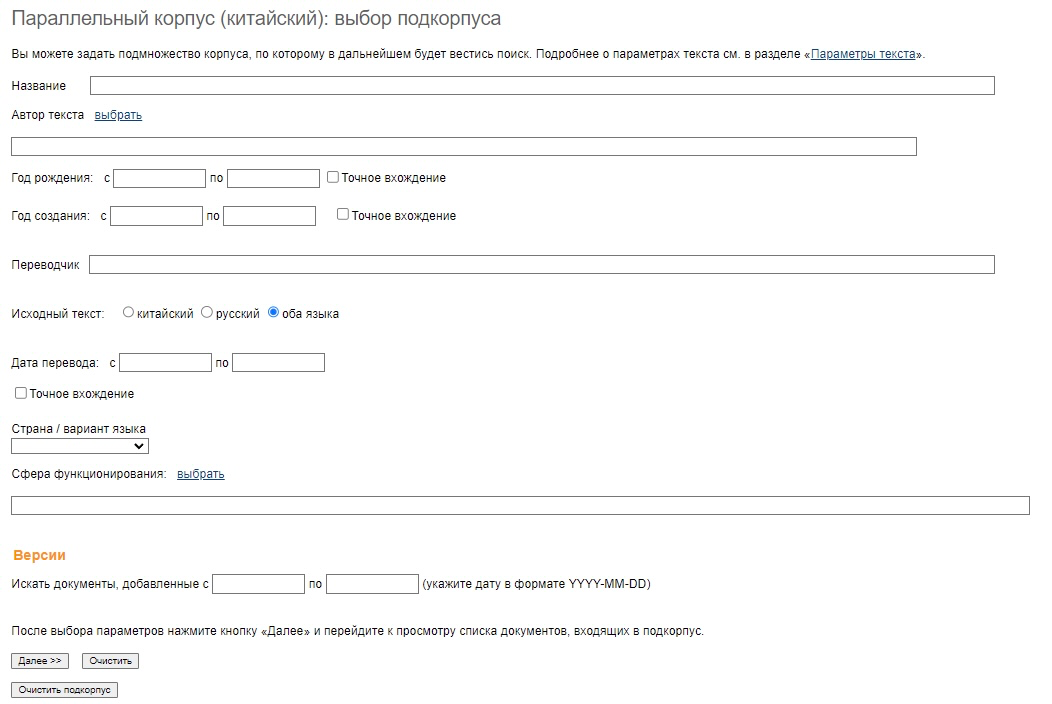
Среди всего прочего в параметрах можно выбрать вариант языка. Варианты китайского языка — это не диалекты, как можно было бы подумать, а именно варианты одного северокитайского диалекта, который сегодня является стандартом. В КНР принят вариант путунхуа, в Тайване — гоюй, а в Сингапуре — хуаюй. Причем тайваньский гоюй записывается традиционными иероглифами, в то время как в KHP и Сингапуре используется так называемая «упрощенная» система, созданная в рамках реформы правописания в 1950–1970-х годах. Хотя главное отличие между стандартными вариантами китайского заключается в орфографии, небольшие различия прослеживаются и на других уровнях языка, начиная от фонетики и заканчивая лексикой.
Важно понимать, что стандартные варианты китайского основаны на одних и тех же диалектах. Однако наряду с ними существуют другие диалекты китайского, отличающиеся гораздо сильнее. Южные диалекты отличаются что от путунхуа, что от гоюй настолько сильно, что носители этих диалектов при встрече не смогут друг друга понять. Наиболее известным таким диалектом является кантонский, распространенный в Гонконге и близлежащих городах КНР, но существуют десятки других не менее отличающихся диалектов.
Вариативность китайского языка наблюдается не только в пространстве, но и во времени, ведь история китайского письменного языка насчитывает несколько тысячелетий. Так, вплоть до пятидесятых годов XX века официальным языком Китая считался вэньянь — очень архаичная версия китайского языка и по сути модифицированный классический китайский язык, существовавший еще в начале прошлого тысячелетия. Если говорить об устной речи, то большая часть китайцев, живущих в городах, использовала байхуа — один из северных диалектов, на основе которого позже и были сделаны унифицированные стандарты путунхуа и гоюй.
На сегодняшний день в Русско-китайском корпусе содержатся тексты на путунхуа и гоюй, а также тексты начала XX века, написанные на байхуа. Также команда корпуса работает над добавлением диалектных текстов и текстов на вэньяне.
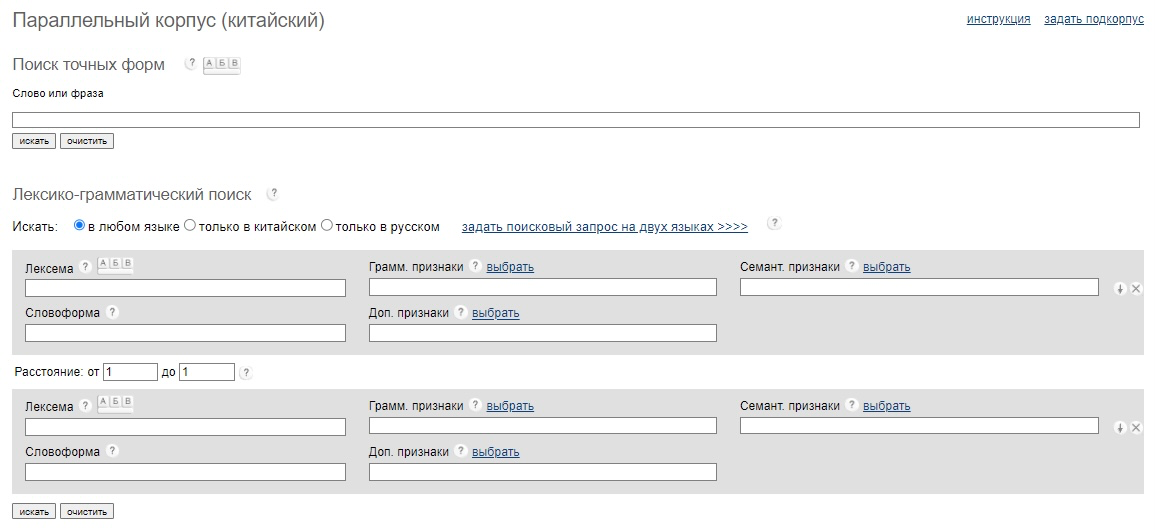
Окно поиска состоит из нескольких строк, в которых задаются грамматические, семантические и дополнительные признаки для одного слова или для каждого слова в цепочке фразы. При выборе грамматической формы отображаются часть речи, залог, время, китайские грамматические показатели и другие признаки. В качестве семантических показателей можно выбрать класс предметов, к которым относится слово (пространство, инструменты, растения, части тела и т.п.).
В корпусе поддерживается три варианта ввода: кириллицей, иероглифами и пиньинем — китайской транскрипцией. Поиск по лексеме (в русском языке) позволяет находить нужное слово во всем формах или уточнять запрос с помощью спецсимволов и поисковых операторов.
В результате поиска выдается пронумерованный список, который состоит из метаинфорации об источнике, оригинального предложения, его перевода и пиньиня, если предложение китайское. Все слова на двух языках размечены и отображаются при нажатии на словоформу. Также есть возможность узнать расширенный контекст и скачать часть результатов поиска в стандартных форматах Excel и CSV.

Чтобы пользователь получил такие понятные и удобные для анализа примеры, недостаточно загрузить текст и его перевод, ведь часто бывает так, что переведенное предложение не соответствует по объему исходному. К тому же, стоит учитывать разницу в системе иероглифического и буквенного письма: условные 100 машинописных страниц на китайском превратятся в 350 страниц на русском. Поэтому основная часть работы над параллельным корпусом заключается в процессе выравнивания предложений, в результате которого фрагменты исходного и переведенного текста разбиваются на отдельные предложения и становятся симметричными. Выравнивание бывает ручным и автоматическим. Если документ небольшой, то выровнять его получится и вручную, но в остальных случаях нужна специальная программа — выравниватель.
Создать параллельный корпус гораздо сложнее, чем обычный одноязычный, поскольку даже при наличии программы процесс выравнивания требует много времени, ресурсов и усилий целой команды специалистов разного профиля.
Что касается художественного подкорпуса, то . в нем собраны наиболее признанные произведения двух стран. Поэтому на русском языке в Русско-китайском корпусе хранятся произведения Л.Н. Толстого, Ф.М. Достоевского, А.П. Чехова, Н.В. Гоголя, И.С. Тургенева и других известных писателей. На китайском языке представлены произведения Лу Синя, основоположника современной китайской литературы, Лю Чжэньюня, известного современного писателя, Юй Хуа, по книге которого режиссер Чжан Имоу снял один из своих лучших фильмов «Жить» (1994), и других авторов.
Использование корпуса
Конечно, в первую очередь корпус предназначен для переводчиков и лингвистов. Для людей, изучающих китайский язык, Русско-китайский параллельный корпус может показаться недостаточно репрезентативным по сравнению с другими лингвистическими корпусами, чьи объемы достигают десятки миллионов слов. Хотя для обучения Русско-китайский корпус тоже используют — например, в паблике корпуса этой теме посвящена серия постов: о поиске сложных грамматических конструкций и многозначных слов, о разнице употреблений и так далее. Однако параллельный корпус обладает неоспоримым преимуществом, а именно коллекцией переводов, через которые можно прослеживать межъязыковые отношения между исходной и переводной культурами. Попробуем подтвердить это на следующих примерах.
«Ботвинья»
Наверняка вы знаете о таких языковых явлениях как безэквивалентная лексика и реалии или, возможно, слышали о том, что некоторые слова в русском языке, например, небезызвестный «надрыв» Достоевского довольно сложно перевести на иностранный язык. Параллельные корпуса позволяют узнать, какие приемы и стратегии использовал переводчик для передачи таких явлений.
Для работы с корпусом мы взяли пример пример реалии с сайта «Слово Толстого», а именно слово «ботвинья», обозначающее холодный суп на квасе. Добавляем его в поле поиска по лексеме и получаем следующий результат.
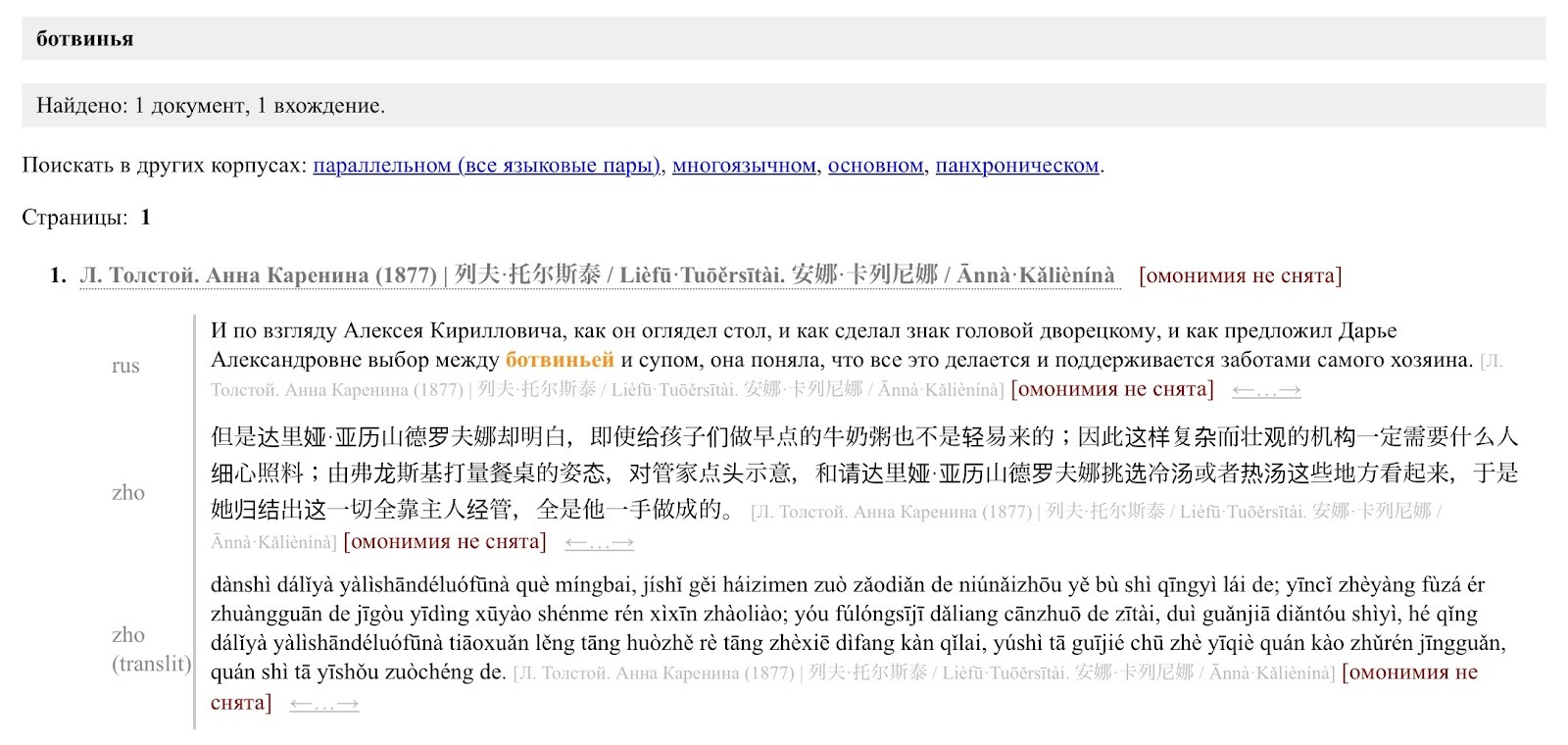
Так как в переведенном тексте искомое слово не выделяется, вбиваем часть предложения в словарь БКРС, чтобы сегментировать фразу и быстро найти перевод. Можно также использовать словарь Чжунга или английско-китайские словари Pleco и Line.
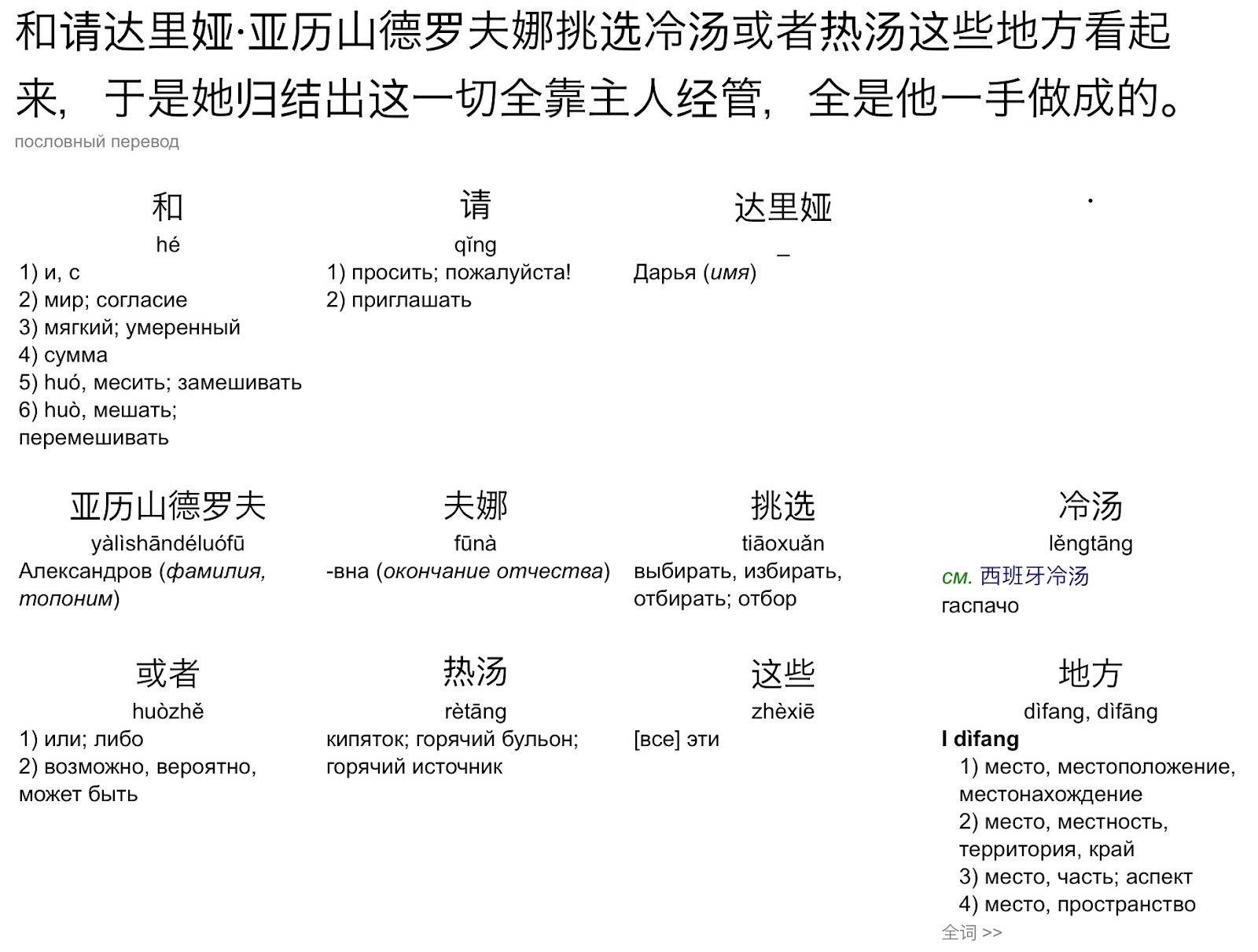
Видим, что суп «ботвинья» переведен как гаспачо и состоит из иероглифов 冷 lěng «холодный» и 汤 tāng «суп». Таким образом, мы увидели один переводческий прием. Если так продолжать, то можно собрать все возможные стратегии перевода и использовать найденные примеры уже для собственных исследований. Например, попробуйте посмотреть, как на китайский язык переводятся слова «щи» или «борщ».
«Судьба»
Другой вариант использования корпуса — сравнивать употребление слов, обозначающих какие-либо концепты, которые в двух культурах не совпадают по смыслу. К примеру, в китайском языке есть такое понятие как 缘分 yuánfen «судьба, предопределение». Оно обозначает неодолимую силу, притягивающую людей, часто возлюбленных или друзей. Русское слово «судьба» не передает этого значения, поэтому переводчики ищут другие способы донести его до читателя.

Таким образом, параллельный корпус пригодится людям , которые читают русскую или китайскую литературу и хотят видеть перед собой оригинальный текст, в котором можно быстро найти необходимые фрагменты на двух языках и сравнить их.
Для лингвистов и китаистов будет интересно почитать о качественных и количественных исследованиях, проведенных с помощью корпуса: про особенности перевода конструкций с предлогом 对 duì с русского на китайский язык, про перевод синтаксических конструкций с показателем 差 chā. На сайте также опубликованы статьи об автоматической разметке, выравнивании корпуса, автоматическому распознаванию текста и так далее.
Перспективы корпуса
Главными недостатками параллельного корпуса являются его объем и сбалансированность. Поэтому в первую очередь команда корпуса работает над поиском и обработкой самых разных текстов на русском и китайском языках. Например, создатели корпуса уже собрали некоторое количество параллельной научно-популярной литературы, поэзии и даже так называемой «наивной прозы» (более известной под названием фанфикшен или новеллы), и находятся в процессе ее обработки и проверки. Добавление текстов разных стилей (а не только художественной или официальной литературы) позволит делать более содержательные выводы о соответствии китайских и русских языковых процессов. Также участники проекта продолжают улучшать интерфейс корпуса, внедрять алгоритмы словоделения, транскрибирования и POS-тегов (то есть автоматического определения частей речи и других грамматических характеристик словоформ).
Источники
Сейчас для корпуса используется приложение Lingtrain Aligner, разработанная Сергеем Аверкиевым в качестве пет-проекта (это такой проект, который разработчик создает в свободное от работы время). Об опыте использования других программ можно почитать в отдельном посте.



