
У популярной языковой платформы «Дуолинго» есть как десктопная, так и мобильная версии. После регистрации можно выбрать желаемый язык (или сразу несколько) и немедленно приступить к занятиям: минималистичный интерфейс предлагает продвигаться по программе как по детским «классикам», а периодически появляющийся на экране дружелюбный маскот — зелёная совушка — подбадривает пользователя и отмечает особо важные достижения: например, сколько очков вы заработали за занятие.

Шаг за шагом
У людей, регистрирующихся на «Дуолинго» и ему подобных ресурсах, может не быть чёткой цели, но большинство из них всё-таки представляет, на каком уровне изучения языка сейчас находится. Для оценки этого уровня повсеместно используется шкала CEFR — вы наверняка сталкивались с ней ещё в те времена, когда учились в школе. Согласно этой шкале, любого пользователя «Дуолинго» можно отнести к одной из трёх групп — новичкам (A1-A2), людям, владеющих языком на среднем уровне (B1-B2), или продвинутым пользователям (C1-C2). Каждому из них нужно предлагать подходящие материалы, которые окажутся достаточно понятны, но будут содержать новые ключевые слова и грамматические конструкции.
Для подготовки курса, который содержал бы все необходимые тексты и упражнения, разработчики «Дуолинго» подготовили специальный инструмент — CEFR-чекер. Если напечатать в окошке слева любую фразу, чекер выделит разными цветами слова, которые обычно осваивают находящиеся на том или ином уровне люди (cat, dog или me, понятное дело, будут актуальны для начинающих, а вот accuracy или impeccable — для опытных студентов). Работать пока можно только с английским и испанским, но в будущем список поддерживаемых языков планируется расширить — это поможет и самим обучающимся, и тестировщикам.
Оценка материала, загружаемого в чекер или обрабатываемого на предмет актуальности для той или иной группы студентов, происходит несколькими способами.
Во-первых, для этого используется модель, основанная на методе ординальной регрессии — он помогает определить «целевую аудиторию» каждого слова в зависимости от того, какое место оно занимает в лексиконе своего языка (на сегодня модель обучена на англо-, испано- и франкоязычном корпусах). Во-вторых, в работе с другими языками применяются так называемый «перенос обучения» (transfer learning) и адаптация алгоритмов в зависимости от предметной области (domain adaptation). Благодаря им слова из разных языков размещаются в условном трёхмерном пространстве, внутри которого легче сгруппировать «кластеры прямых переводов».
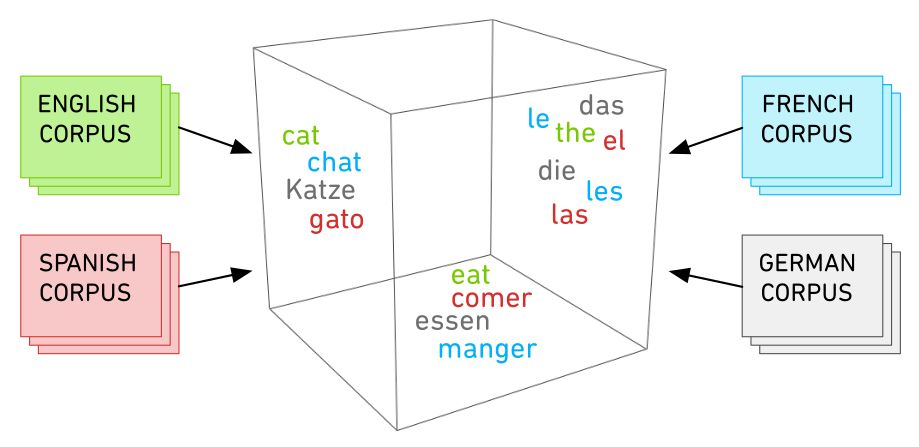
Контролировать то, из какого кластера будут браться слова для упражнений на том или ином уровне, довольно легко — по шкале CEFR оценивается преимущественно способность вступать в те или иные виды коммуникации (а значит, использовать те или иные лексические единицы); по этому же принципу строятся и промежуточные внутренние тесты. Разработчики заготавливают большой пул вопросов, проверяющих соответствие знаний студента нужным стандартам (говорите, у вас C1? Всё ещё помните, как переводится impeccable?), но каждому пользователю выдаётся только малая их часть — штук 10-15. Благодаря этому оценивается и успешность преподнесения информации, и точность её организации.
Правда, может возникнуть вопрос: почему же в таком случае не обойтись прямым переводом с одного языка на другой? Ответ прост: в основе даже самых простых фраз лежат устойчивые грамматические сочетания, которые в разных языках могут довольно сильно расходиться. Эквивалентом русскому «Я голоден», например, будут английское I am hungry (Я есть голоден) и испанское tengo hambre (Я имею голод), — даже это, согласитесь, уже не совсем одно и то же.
Давайте по-другому
Как знает любой владеющий иностранным языком, некоторые слова или предложения могут переводиться сразу несколькими способами; например, из-за того, что временная система русского языка довольно скудна, для передачи «играет» на всё тот же английский придётся выбирать как минимум между двумя вариантами — plays и is playing. «Дуолинго», разумеется, это учитывает: согласно блогу платформы, в среднем для каждого из упражнений на перевод предусмотрено более двухсот (а в отдельных случаях — несколько тысяч) вариантов ответа.
Большую часть из альтернативных версий предлагают сами обучающиеся: для этого можно нажать кнопку Report. Поступившие после этого в обработку фразы оцениваются с помощью метода логистической регрессии: каждой их характеристике приписывается тот или иной цифровой показатель, сигнализирующий о том, насколько присланная версия близка к уже одобренным, правильным. Если между ними заметны существенные различия, система вычисляет, насколько они критичны (и старается определить, что можно сделать, чтобы заставить человека запомнить правильный перевод).
В целом, поскольку «Дуолинго» учит преимущественно словам, подобные модели в пределах этой платформы функционируют также в основном на лексическом уровне. Впрочем, это не значит, что механизмы ресурса несовершенны: его основатели заявляют, что обучение системы с помощью фраз, предложенных англоязычными участниками курса французского, позже может помочь тренировать модели и для работы с теми, кто изучает, например, клингонский. Это вполне логично: чем больше мы знаем о том, как учатся носители конкретного языка (или даже его варианта), тем более точные даже при всей своей минималистичности методики сможем им предложить.
Источник: блог о работе Duolingo можно полистать вот здесь.



