
Retrieval Augmented Generation (RAG) — это технология, сочетающая в себе поиск релевантной информации в существующих хранилищах данных и генерацию текста с помощью языковых моделей, для создания более точных и информативных ответов.
Языковые модели любят выдумывать
Современные языковые модели вроде ChatGPT способны отвечать на самые разные вопросы — начиная от фактов об императорских пингвинах и заканчивая рассуждениями о смысле жизни. Однако зачастую они генерируют фактологически неверную информацию. То есть, проще говоря, фантазируют. Например, если попросить языковую модель рассказать о несуществующем произведении известного писателя, то с большой вероятностью нейросеть выдумает его описание вместо того, чтобы сказать, что такого произведения не существует.

Пример галлюцинации ChatGPT
Подобное поведение языковых моделей называют галлюцинациями. Галлюцинации — одна из ключевых проблем, мешающих использованию языковых моделей для решения реальных задач. Например, в качестве справочника или аналога поисковых систем.
Исследователи пока работают над полным устранением этого недостатка. Но уже сейчас можно снизить вероятность ложного ответа. Для этого существует множество различных техник, и одна из них — RAG (retrieval-augmented generation, генерация, дополненная релевантной для пользователя информацией).
RAG: вопрос вместе с релевантной информацией
Перед тем, как перейти к описанию техники RAG, нужно вспомнить, как обычно языковая модель генерирует ответ. Рассмотрим обычную генерацию, при которой модель получает от пользователя только сам вопрос.
Языковая модель принимает на вход текст запроса от пользователя и слово за словом генерирует его вероятное продолжение. Информацию о том, какое слово будет наиболее вероятным в качестве продолжения, она «выучивает» в процессе обучения. Иными словами, языковая модель хранит в себе только ту информацию, на которой её обучали. Именно поэтому, например, ChatGPT может отвечать только про события, случившиеся до определённой даты. Подробнее об устройстве языковых моделей можно прочитать в нашем материале.
Но что, если кроме самого вопроса подать на вход информацию, которая потенциально могла бы помочь модели ответить правильно?
Например, помимо вопроса о среднем росте императорского пингвина, дать модели справку об императорских пингвинах из энциклопедии? Вероятность, что модель даст правильный ответ, будет выше, поскольку релевантная справка из энциклопедии уже содержит в себе ответ на вопрос — модели нужно будет только его извлечь.

Средний рост императорского пингвина — 120 см. Фото: Flickr
Техника RAG основана как раз на этой идее: модели на вход кроме вопроса пользователя нужно подать информацию, которая будет потенциально полезна для ответа.
Таким образом, RAG — это генерация, расширенная поиском. Но помимо поиска в RAG есть и две другие составляющие: данные, среди которых производится поиск, и сам процесс генерации. Разберём каждую компоненту отдельно.
Компоненты RAG: данные, поиск и генерация
Данные
В качестве данных может выступать любое хранилище информации, по которому можно производить поиск. Например, база данных службы поддержки с парами вопрос-ответ, документация компании, база с текстами из энциклопедии, база с персональными данными пользователя (сведения из телефонной книги, календаря и т. д.) и даже поисковые системы вроде Google.
Поиск
Под поиском подразумевается процесс нахождения полезной информации, исходя из запроса пользователя. Поиск может производиться разными способами.
Например, его можно производить на уровне совпадения слов. В таком случае наиболее релевантными будут данные, которые содержат в себе самое большое количество слов из вопроса пользователя.
Поиск может быть устроен сложнее. Вопрос пользователя и данные в базе могут быть представлены эмбеддингами — наборами чисел, которые отражают семантику (смысловое значение) данных. Чем у двух текстов наборы чисел более похожи, тем эти тексты семантически более близки, и наоборот.
Компьютер способен эффективно сравнивать наборы чисел. Поэтому, храня таким образом данные, можно реализовать поиск: нужно просто сравнить эмбеддинг запроса с эмбеддингами всех текстов в базе. А затем выбрать те из них, чьи эмбеддинги наиболее близки к эмбеддингам запроса. Похожая идея представления текстовых данных лежит в Word2Vec, однако там наборами чисел представляются не тексты, а слова.
Генерация
Последний этап — генерация ответа на вопрос с использованием найденной информации. Генерация производится с помощью языковой модели и специальных шаблонов, по которым с использованием найденного конструируется итоговый запрос, который будет подан на вход модели.
Например шаблон для ответов на фактологические вопросы выглядит так:
«Пользователь задал вопрос: {вопрос}. Вот релевантная информация, найденная в справочнике: {найденная информация}. Ответь на вопрос пользователя, основываясь только на данной выше информации. Если данная информация не содержит ответ на вопрос пользователя, то ответь, что ты не знаешь».
Требование к языковой модели сообщить, что она не знает, если собранная информация не содержит ответ на вопрос, необходимо, чтобы уменьшить галлюцинации. Если явно не прописать это требование в запросе модели, то она будет склонна к выдумыванию ответов.
Благодаря исключению выдуманных ответов, RAG можно использовать для помощи операторам службы поддержки. В этом случае для заданного пользователем вопроса в базе уже существующих вопросов-ответов производится поиск, например, трёх самых похожих вопросов. А затем результат добавляется в вопрос для языковой модели по следующему шаблону:
«Пользователь задал вопрос: {вопрос}. Вот список похожих вопросов с ответами на них:
- {Вопрос 1}. Ответ: {Ответ на вопрос 1}.
- {Вопрос 2}. Ответ: {Ответ на вопрос 2}.
- {Вопрос 3}. Ответ: {Ответ на вопрос 3}.
Ответь на вопрос пользователя, основываясь только на ответах на похожие вопросы, которые перечислены выше. Если данная информация не содержит ответ на вопрос пользователя, то ответь, что ты не знаешь».
Содержимое шаблона зависит и от решаемой задачи, и от модели и подбирается специалистами вручную.
Собираем всё вместе: пример работы RAG
Теперь, когда мы разобрали все компоненты, разберём работу RAG на конкретном примере с императорским пингвином.

Иллюстрация работы RAG
Пользователь задаёт вопрос: «Какой средний рост императорского пингвина?»
Первый шаг — поиск релевантной информации в базе с текстами энциклопедии. Вопрос пользователя подаётся на вход системе поиска по базе, и она выдаёт релевантную информацию.
Допустим, что в базе нашлась справка об этом виде пингвинов со следующим содержанием:
«Императорский пингвин — самый крупный и тяжёлый из современных видов семейства пингвиновых. Его средний рост составляет около 120 см, а вес колеблется между 22 и 45 кг».
Второй шаг — формирование запроса для языковой модели по определённому шаблону (мы их уже разбирали в разделе про компоненты).
В шаблон вставляется вопрос пользователя и найденная на первом шаге информация:
«Пользователь задал вопрос: Каков средний рост императорского пингвина?
Вот релевантная информация, найденная в справочнике: Императорский пингвин — самый крупный и тяжёлый из современных видов семейства пингвиновых. Его средний рост составляет около 120 см, а вес колеблется между 22 и 45 кг.
Ответь на вопрос пользователя, основываясь только на данной выше информации. Если данная информация не содержит ответ на вопрос пользователя, то ответь, что ты не знаешь».
Третий шаг — генерация финального ответа.
Языковая модель извлекает нужную информацию из запроса, сформированного на предыдущем шаге, и генерирует финальный ответ:
«Средний рост императорского пингвина составляет 120 см».
Сложности и проблемы, связанные с RAG
RAG требует аккуратной настройки каждой компоненты:
- Данные, которые используются для RAG, должны быть полными и разнообразными, иначе высока вероятность не найти релевантную информацию. Также существует ряд задач, в которых нужно поддерживать актуальность данных (например, генерация ответов на вопросы о документации компании или текущей статистике).
- Поиск должен выдавать действительно полезную информацию. Качество результата при этом зависит от алгоритма поиска и его настройки. Ещё один важный фактор — скорость поиска.
- Плохо подобранный шаблон для генерации может существенно ухудшить качество ответов модели.
Также стоит учитывать, что длина текста, которую можно подать на вход языковой модели, ограничена, поэтому нужно подавать либо самую релевантную информацию, либо сжимать её специальными методами.
Где используется RAG
RAG используется для решения задач, в которых поиск ответов на вопросы пользователя нужно провести во внешних источниках информации. Например, связанных с фактами, документами, работой службы поддержки.
Также RAG используют для создания более продвинутых поисковых систем. В традиционных поисковых системах пользователь в ответ на запрос получает выдачу релевантных сайтов, на которых может оказаться ответ.
Используя RAG и поисковую выдачу, можно ускорить процесс поиска ответа: вместе с запросом пользователя подать языковой модели содержимое нескольких релевантных сайтов, из которых она и сгенерирует ответ.
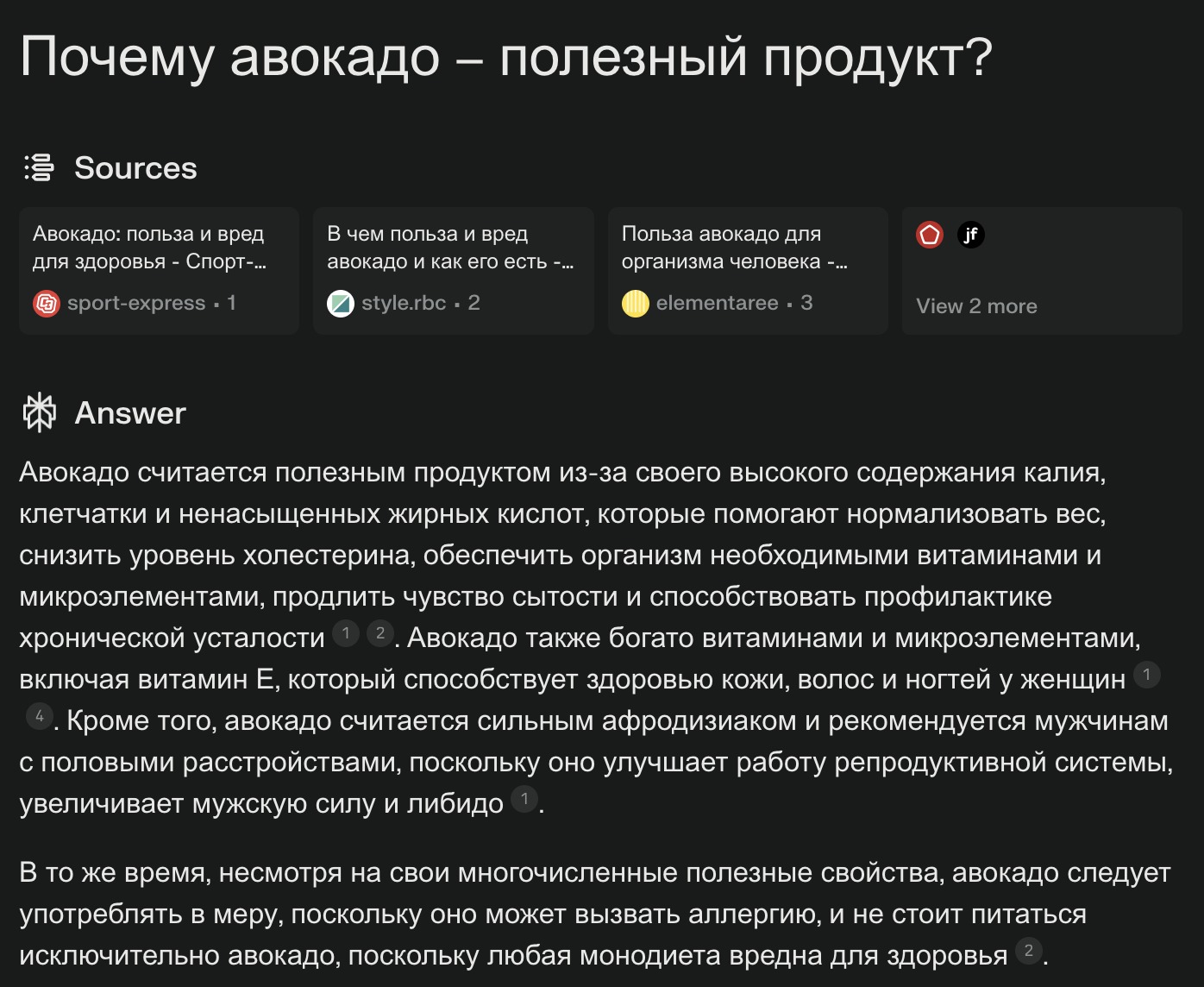
Пример работы RAG в поисковой системе Perplexity.ai: система нашла несколько релевантных сайтов (они отображены в секции Sources), взяла из них информацию и подала её и исходный вопрос в языковую модель, которая сгенерировала финальный ответ (в секции Answer)
Также RAG часто используют для генерации выжимок и отчётов: например, исследователь может подать на вход модели несколько научных статей по интересующей его теме и попросить сгенерировать выжимку со ссылками на данные статьи.

