
Некоторое время назад Google Переводчик при попытке перевести определенные буквосочетания на суахили или маори выдавал пугающие религиозные пророчества. Кликбейт-сайты выдвигали предположения о заговоре, но на самом деле оказалось, что дело было всего лишь в особенностях обучающих датасетов — машинный перевод основывался на религиозных текстах и в сложных случаях обращался к привычным паттернам.
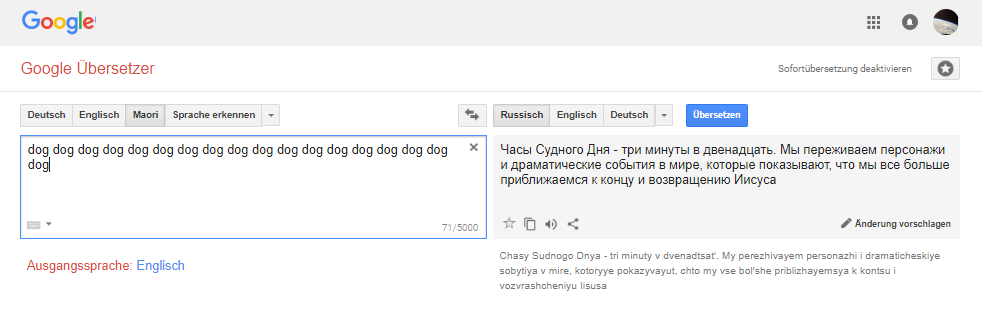
Эта ситуация в очередной раз породила волну обсуждений о сложностях машинного перевода. Тем не менее, как рассказал технический директор Google Translate Макдафф Хьюз (Macduff Hughes) изданию The Verge, именно возможность машинного обучения делает инструменты перевода Google такими успешными. Доступный, простой и быстрый перевод стал одной из тех привилегий XXI века, которую мы воспринимаем как что-то само собой разумеющееся, однако это стало возможным только благодаря искусственному интеллекту (ИИ).
В 2016 году Переводчик перешел с метода, известного как статистический машинный перевод по фразам, на метод, в котором задействованы нейросети. Старая модель перевода, когда текст переводился по одному слову, выдавала много ошибок, так как система не учитывала грамматические нормы, например времена глаголов и порядок слов. Новая же модель переводит предложение за предложением, а значит, учитывает чуть более широкий контекст.
«В результате мы получаем язык, который звучит естественнее, с более плавными переходами», — отмечает Хьюз, и обещает, что Google Переводчик ожидают еще большие положительные изменения. Скоро он сможет различать стили речи, (использует говорящий формальную лексику или сленг?), и чаще предлагать несколько вариантов формулировок.
Переводчик — это репутационно полезный для Google проект, который, как многие заметили, является для компании своего рода прикрытием применения искусственного интеллекта для спорных и неоднозначных целей, к примеру, военных разработок. Хьюз рассказывает, зачем компания продолжает поддерживать этот сервис, а также объясняет, как собираются решать проблему стереотипов при использовании данных для обучения искусственного интеллекта.
Интервью с Макдаффом Хьюзом
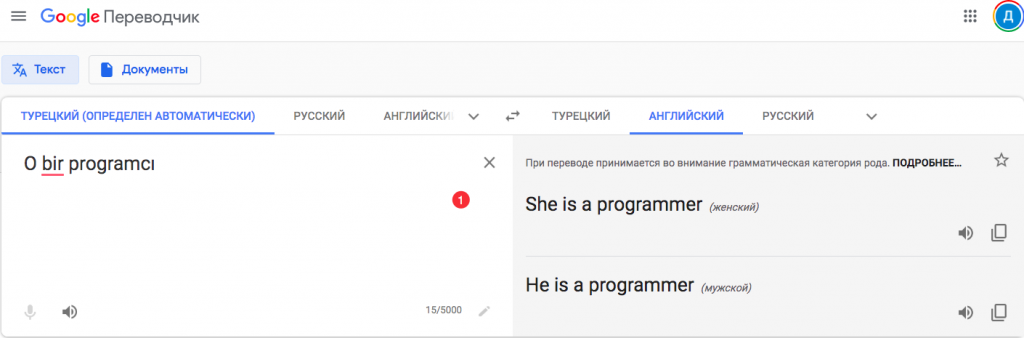
Главным нововведением в последней обновленной версии Переводчика стали гендерно обусловленные варианты перевода. Что сподвигло вас к таким изменениям?
Мы исходили из двух дополняющих друг друга факторов. Первый — обеспокоенность социальными предрассудками, которые встречаются во всех разработках с использованием машинного обучения и ИИ. Продукты и сервисы, использующие алгоритмы машинного обучения, отражают гендерные стереотипы, которые содержатся в обучающих данных, а те, в свою очередь, отражают социальные предрассудки, усиливая их и даже преувеличивая. Этой проблемой обеспокоены не только в Google, но и во всей индустрии. Мы, как любая компания, хотим занимать лидирующие позиции в решении этих проблем и мы знаем, что Переводчик тоже не идеален, особенно когда речь идет о гендерных стереотипах.
Классический пример стереотипного мышления: врач — мужчина, медсестра — женщина. Если такие предубеждения встречаются в языке, тогда и модель перевода запомнит их и будет распространять. Если, к примеру, в 60-70% случаев профессия относится к мужчинам, тогда система перевода может запомнить это и в 100% случаев будет указывать её как мужскую. Нам нужно бороться с этим.
Многие наши пользователей изучают языки и хотят понимать, какие существуют варианты выражения мыслей и какие при этом могут быть нюансы. Мы давно пришли к важности демонстрации нескольких вариантов перевода, и это тоже повлияло на наш гендерный проект. Нельзя точно сказать, каким образом стоит решать такие проблемы. Нельзя просто предлагать варианты в соотношении 50/50 или давать произвольный вариант (в случае, когда мы апеллируем к гендеру в переводе), правильней будет давать пользователям больше информации для выбора. Показать, что существует более одного варианта перевода данной фразы на другой язык, и отметить, какие существуют различия между предложенными вариантами. В переводе довольно много спорных культурных и языковых моментов; мы хотим хоть как-то решить проблему гендерных стереотипов и тем самым улучшить качество работы Переводчика.
Какова следующая проблема, связанная с предрассудками и нюансами перевода?
У нас есть три значительные инициативы. Первая — продолжать работу над проектом, который мы только что с вами обсуждали. Мы уже запустили перевод полных предложений с учётом гендерных факторов, но пока только с турецкого языка на английский. Далее мы хотим улучшить качество их перевода и подключить другие языки к данному проекту. Для некоторых языков мы завершили перевод отдельных слов.
Вторая инициатива касается перевода целых документов. В данном случае проблема предрассудков также существует, но она должна решаться иным образом. Например, возьмем статью из Википедии о женщине и переведем ее с другого языка, в котором нет категории рода, на английский. Вероятнее всего, большинство местоимений переведутся на английский как «он» и «его». Каждое предложение статьи переводится отдельно от других, и, если в тексте на исходном языке нет четких указаний на гендер, то с большей долей вероятности в переводе по умолчанию появятся местоимения, относящиеся к мужскому роду. Сегодня особенно оскорбительно использовать слово в неправильном роде, но решение этой проблемы требует абсолютно иного подхода, нежели мы использовали ранее. В нашем примере проблема решается обращением к контексту, остальной части документа. И эту проблему предстоит решить инженерам и исследователям.
Третья инициатива посвящена гендерно-нейтральным языковым конструкциям. Сегодня мы живем в самый разгар культурной нестабильности, отражающейся не только в английском языке, но и во всех языках, имеющих гендерно-окрашенные слова. В современном мире формируется движение за создание гендерно-нейтрального языка, и в связи с этим к нам поступает множество заявок от пользователей с вопросом, когда мы начнем его внедрять. Частый пример, который приводят в связи с этим, — использование в английском языке местоимения «они» в единственном числе. Вариант использования «они» по отношению к человеку в противовес местоимениям «он» или «она» очень популярен, хотя и не используется в учебниках и в стандартах. Такая же ситуация наблюдается в испанском, французском и многих других языках. Правила меняются с такой скоростью, что даже экспертам сложно уследить за всеми изменениями.
Любопытная ситуация произошла в прошлом году с Google Переводчиком, когда люди обнаружили, что при введении выдуманных бессмысленных слов он выдавал фрагменты религиозных текстов. Люди стали выдвигать фантастические теории на этот счет. Что вы предприняли по этому поводу?
Я не удивился, что это произошло, но меня поразило то, какой интерес это вызвало у пользователей. Стали появляться разные теории заговора — якобы Google зашифровал загадочные послания о космических пришельцах, тайных религиозных культах… На самом деле эта ситуация иллюстрирует основную проблему моделей машинного обучения, когда в ответ на ввод непредусмотренных данных система реагирует непредвиденным образом. Проблема, над которой мы работаем, заключается как раз в том, чтобы в ответ на бессмысленный запрос система не выдавала ничего осмысленного.
Но почему это произошло? Я не помню, чтобы вы когда либо озвучивали объяснение произошедшего.
Обычно это случается потому, что при обучении модели языку, на который вы переводите, в качестве обучающих данных используется большое количество религиозных текстов. Для каждой языковой пары, которая сейчас у нас имеется, мы используем в процессе машинного обучения всю доступную в Интернете информацию. Поэтому типичное поведение модели, столкнувшейся с непонятной фразой — подбор самого близкого варианта из обучающих данных. В ситуации с редкими языками, на которые в интернете очень мало переведенных текстов, модель чаще всего выдает фразы религиозного толка.
Для некоторых языков первым переведенным документом, который мы нашли, была Библия. Мы берём всё, что можем найти, и обычно всё в порядке, но если вводить бессмыслицу, результат часто бывает именно такой. Если бы основными переведенными документами были юридические документы, то модель бы выдавала термины из юриспруденции, если бы это были руководства по управлению самолетом, то выдавались бы летные инструкции.
Это невероятно. Напоминает то, как Библия короля Джеймса повлияла на становление английского языка. Мы и сегодня используем многие фразы, взятые из этого перевода Библии 17-го века. Что-то похожее происходило с Google Переводчиком? Много ли необычных источников и фраз используется в обучающих базах?
Да, иногда нам попадаются необычные фразы из интернет сообществ, например, сленг с игровых форумов и сайтов. И такое бывает! Увеличивая количество языков, мы собираем более разнообразные данные для обучения, и да, иногда на просторах интернета встречается довольно занимательный сленг. Но, боюсь, пока не могу припомнить ничего определенного.
Итак, Google Переводчик особенно интересен тем, что, в отличии от ИИ, о котором ведутся споры, как и где его можно применять, все единодушны во мнении, что перевод — вещь полезная и относительно беспроблемная. Что, на ваш взгляд, мотивирует Google вкладывать средства в перевод?
Наша компания ставит перед собой довольно идеалистические цели. Я считаю, что команда разработчиков Google Переводчика еще большие идеалисты. Мы усердно работаем, чтобы сказанное вами было правильно понято. И именно поэтому так важно бороться с предрассудками и исправлять неверный перевод, который может принести вред.
Но зачем Google в это инвестировать? Нас часто об этом спрашивают, и ответ довольно прост. Наша миссия заключается в том, чтобы систематизировать всю информацию в мире, и сделать её доступной для каждого, а мы еще очень сильно далеки от достижения «доступности каждому». И пока большая часть жителей планеты не сможет получить доступ к онлайн информации, ее нельзя считать всемирно доступной. Чтобы выполнить основную миссию компании, Google должен решить проблему перевода, и я думаю, что основатели понимали это еще десятилетие назад.
А вы считаете возможно решить проблему перевода? Недавно в журнале The Atlantic вышла статья известного профессора-когнитивиста Дугласа Хофштадтера, в которой он отмечает «ограниченность» Google Переводчика. Что вы можете ответить на его критику?
То, на что он указал, было справедливым, и это правда так. В работе Переводчика есть эти проблемы. Но пока они для нас не на первом плане, потому что при переводе они выявляются в очень малом проценте случаев. Если мы возьмем типичные тексты, которые люди обычно переводят, там эти проблемы возникают крайне редко. Но он прав: чтобы на самом деле решить проблему перевода и позволить машинному переводу достичь уровня опытного переводчика, необходимы серьезные технические усовершенствования. Обучаясь только на примерах параллельных текстов, невозможно узнать о нескольких оставшихся процентах случаев.
Ведь как уже очень давно говорят, перевод — это основная проблема ИИ. Поэтому, чтобы полностью решить проблему перевода, необходимо полностью решить проблемы ИИ. И я согласен с этим. Однако я считаю, что можно решить очень большой процент этих проблем, чем мы сейчас и занимаемся.
Материал подготовлен совместно с группой переводческих компаний AKM Translations
Источник: Google’s head of translation on fighting bias in language and why AI loves religious texts



