В этой статье мы расскажем, как проанализировать героев «Войны и мира» с помощью двух количественных методов. Отметим, что исследование было бы невозможно без предварительной семантической разметки текста. Размеченный датасет находится в открытом доступе на сайте репозитория Пушкинского Дома.
Как стилометрия помогает моделировать систему персонажей
Под стилометрией обычно понимают анализ текста, который позволяет определить стиль или авторство произведения. Наиболее популярный метод стилометрии — Дельта Берроуза. Суть ее применения в следующем: из корпуса текстов создается список наиболее частотных слов или цепочек символов (символьных n-грамм). Далее каждый из текстов представляется как вектор нормализованных частотностей слов или n-грамм и становится точкой в многомерном пространстве. Между векторами можно вычислить расстояние на основе распределения частотностей и таким образом определить степень сходства текстов. Для полного стилометрического анализа используется библиотека stylo для языка R. В этой библиотеке есть функции stylo и classify, и Дельта в них уже интегрирована.
Применение методов стилометрии не заканчивается на атрибуции и компьютерной стилистике — они также подходят для анализа речи персонажей и создания системы персонажей в произведении. Так, в случае с «Войной и миром» автор исследования выбрал 16 героев, чей объем прямой речи во всей книге превышает 1000 словоупотреблений. Для анализа их речи метод Дельты пригодился в том смысле, что, основываясь на списке 130 наиболее частотных слов в корпусе реплик каждого персонажа, Дельта правильно определила особенности их речи и успешно находила героя, кому принадлежит та или иная реплика.
Результаты построения системы персонажей с использованием Дельты представлены в иллюстрациях ниже. В них каждый из 16 героев — «точка» в двумерной системе координат, и чем ближе точки персонажей, тем больше похожа их речь.
Для визуализации применялись методы уменьшения размерности: метод главных компонент (матрица ковариации и матрица корреляции) и метод многомерного шкалирования. Метод главных компонент нужен, чтобы сократить число повторяющихся или ненужных векторных данных и таким образом сделать визуализацию более простой и точной. Метод многомерного шкалирования сжимает объекты данных с минимальными потерями и представляет их в виде точек на числовой прямой, плоскости или в трехмерном пространстве.
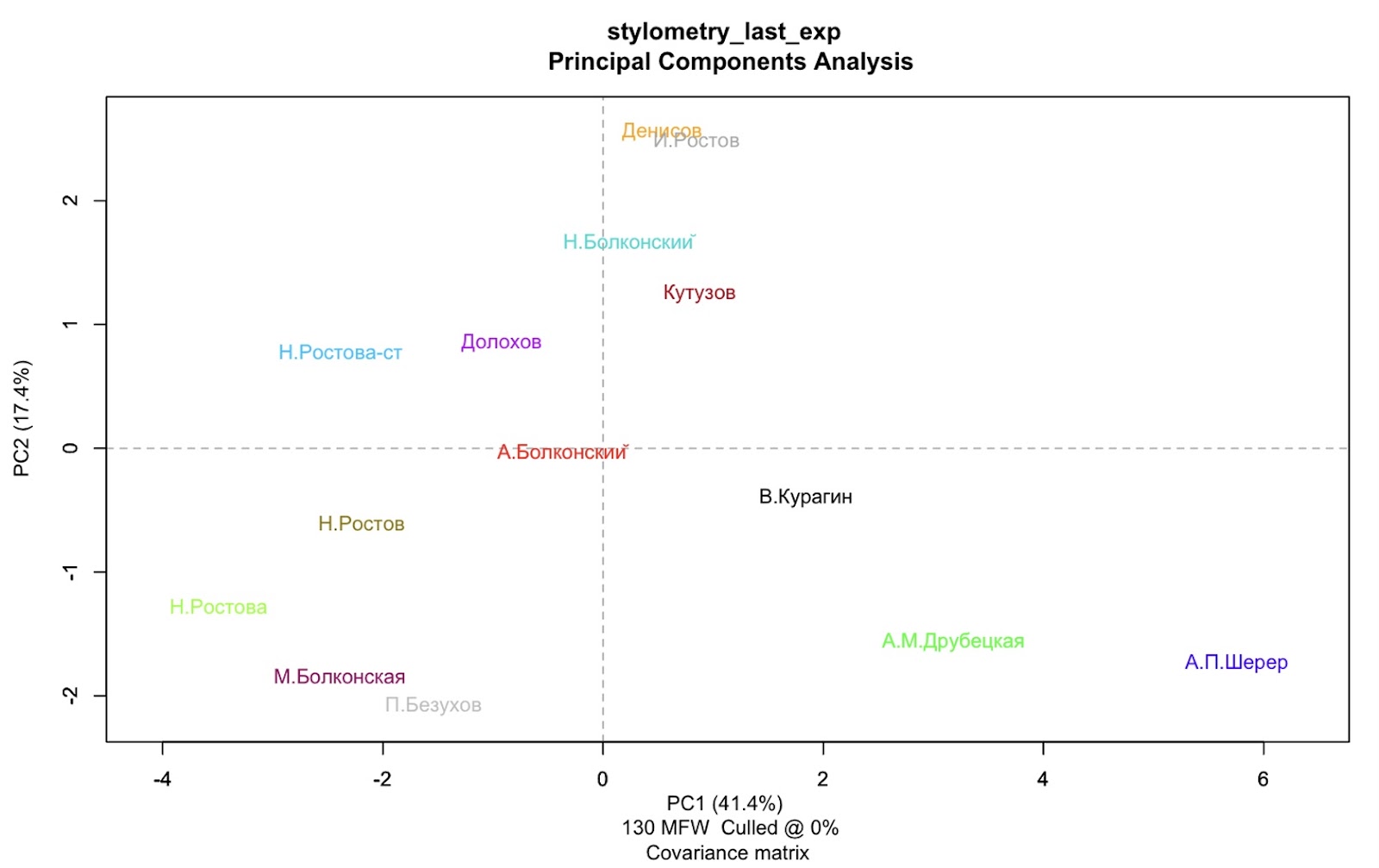


Видно, что на графиках персонажи условно разделяются на три группы. Примечательно, что при использовании метода главных компонент Андрей Болконский находится на периферии в своей группе протагонистов, потому что стилометрические параметры его речи схожи с речевыми портретами статичных второстепенных персонажей, «светских антагонистов» в лице Василия Курагина, Анны Шерер и Анны Друбецкой. Кстати о «светских»: их группа выделяется наиболее явно по сравнению с другими. Это также заметно при использовании иерархической кластеризации. Кластеризация нужна, чтобы разбить объекты на такие группы, чтобы объекты одного кластера были похожи друг на друга, а объекты разных кластеров наоборот отличались.
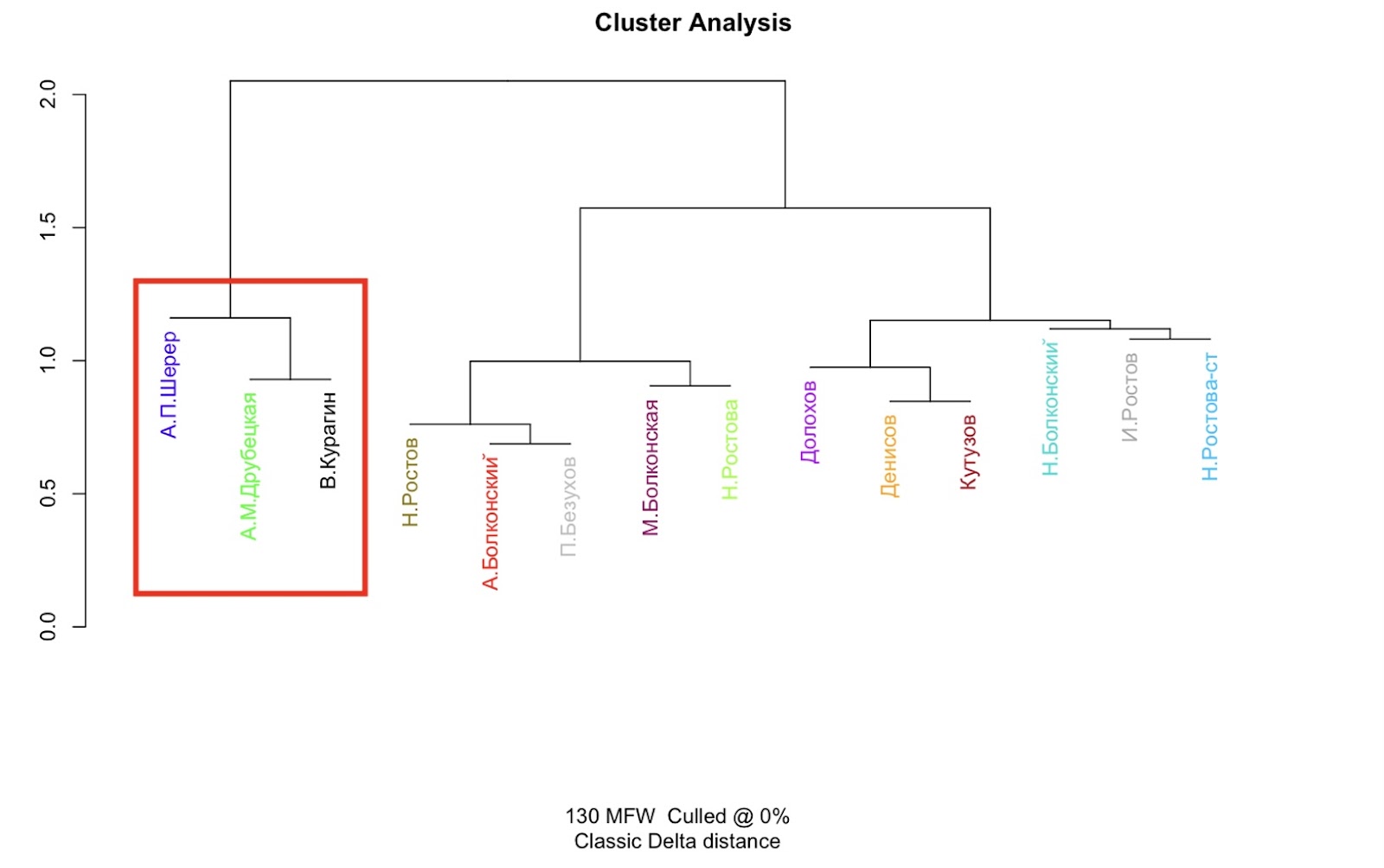
В рамках иерархической кластеризации персонажи разделились на главных неисторических героев (Андрей Болконский, Пьер Безухов, Николай Ростов, Наташа Ростова, княжна Марья Болконская), персонажей второго плана (Денисов, князь Николай Болконский, граф Илья Ростов, графиня Наталья Ростова, Кутузов) и группы второстепенных персонажей «светского Петербурга», влиятельных при дворе (Василий Курагин, Анна Шерер, Анна Друбецкая). Персонажи также разделены на подгруппы. Это объясняется тем, что стилометрический метод объединил героев в том числе из-за большого количества диалогов между ними.
Отдельного внимания заслуживает перемещение графини Ростовой из группы протагонистов в группу персонажей второго плана. Автор исследования предполагает, что это объясняется «промежуточным положением графини Ростовой между «взрослым миром» Долохова и Денисова и миром ее детей, Наташи и Николая». Ее промежуточное положение в пространстве персонажей подтверждается также результатами кластеризации с использованием метода дерева решений, который может обобщить несколько стилометрических измерений с разными параметрами (в нашем случае — в диапазоне от 50 до 150 самых частотных слов):

Как с моделированием справляется метод оценки нелексических признаков прямой речи
Нелексические параметры речи — это, например, доля восклицаний, вопросительных реплик, отношение числа знаков препинания к числу слов, частотность дискурсивных маркеров (частиц, предлогов, междометий и т.д.), читабельность, рассчитанная на основе 5 метрик, которые опираются на среднюю длину слова и предложения. О том, что такое читабельность текстов и как она вычисляется, Системный Блокъ писал тут и тут.
При этом эти параметры гораздо легче интерпретировать, чем результаты применения Дельты. Их также можно исследовать с помощью метода главных компонент, многомерного шкалирования и иерархической кластеризации. Вот так выглядит пространство персонажей, визуализированное методом главных компонент:
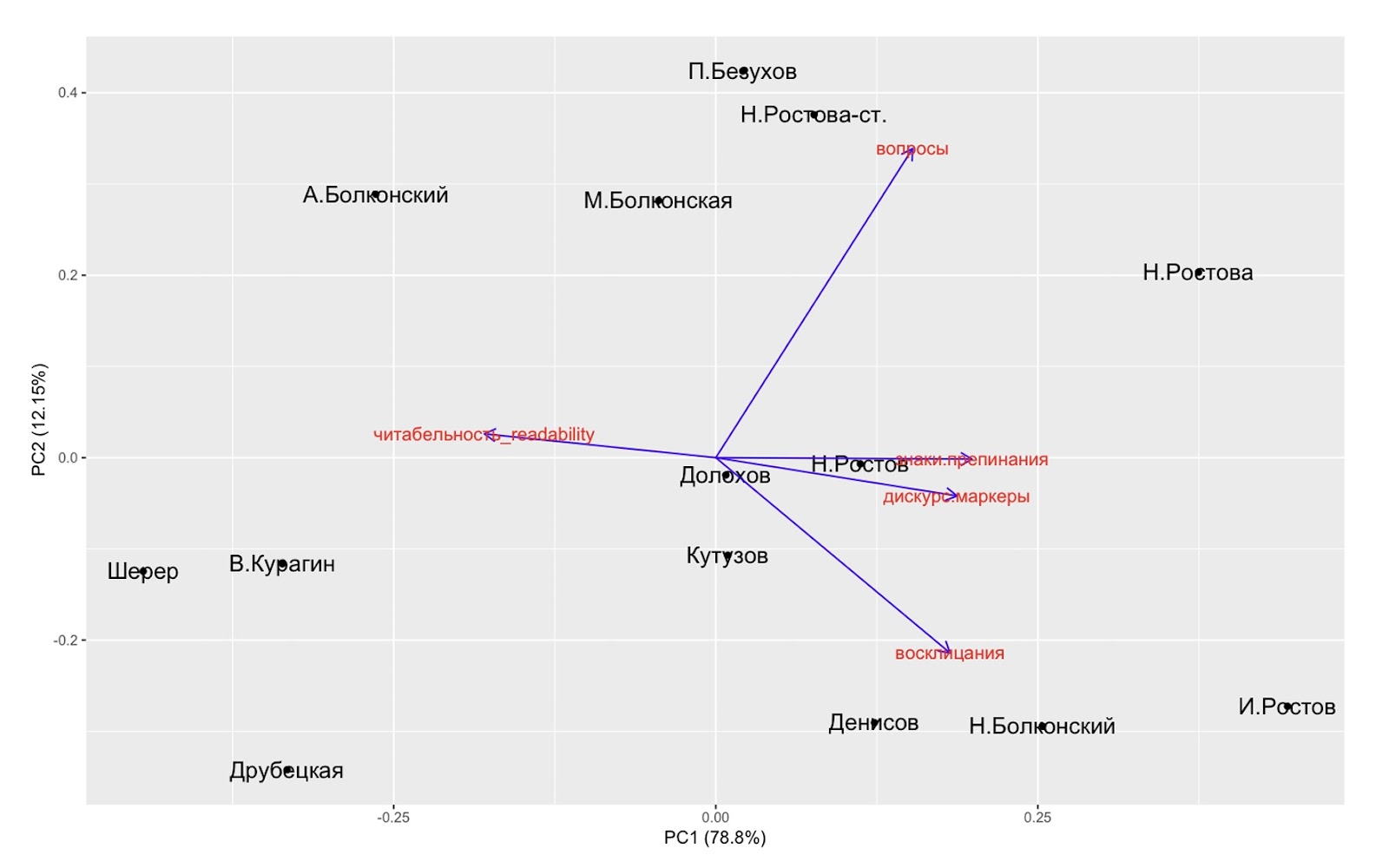
В левом нижнем углу находятся персонажи с трудночитаемой речью с небольшим количеством вопросов, восклицаний и знаков препинания. Здесь снова выделяется группа с Василием Курагиным, Анной Шерер и княгиней Друбецкой, потому что их речь максимально неразговорная и усложненная.
В правом верхнем углу все наоборот: речь должна быть хорошо читабельной, с большим количеством дискурсивных маркеров, вопросительных и восклицательных реплик. Неудивительно, что в нем находится Наташа Ростова — персонаж со спонтанной и экспрессивной речью. Отметим и положение отца семейства Ильи Ростова, который находится рядом с военными персонажами, но не попадает в их число, так как по своему «безыскусному» речевому портрету больше схож с Наташей, чем с «мужским военным пространством».
Также мы видим, что Андрей Болконский отделился от других протагонистов, так как его речь оказалась менее «живой» по сравнению с речью других главных героев книги (особенно Наташи Ростовой) — она трудночитаема, в ней мало восклицаний и дискурсивных маркеров. Но это не сближает его со «светской» группой в нижнем углу, потому что в его репликах есть высокая доля вопросов. Поэтому он расположен ближе к группе княжны Марьи, Пьера и графини Ростовой, которых отличает такая же характеристика.
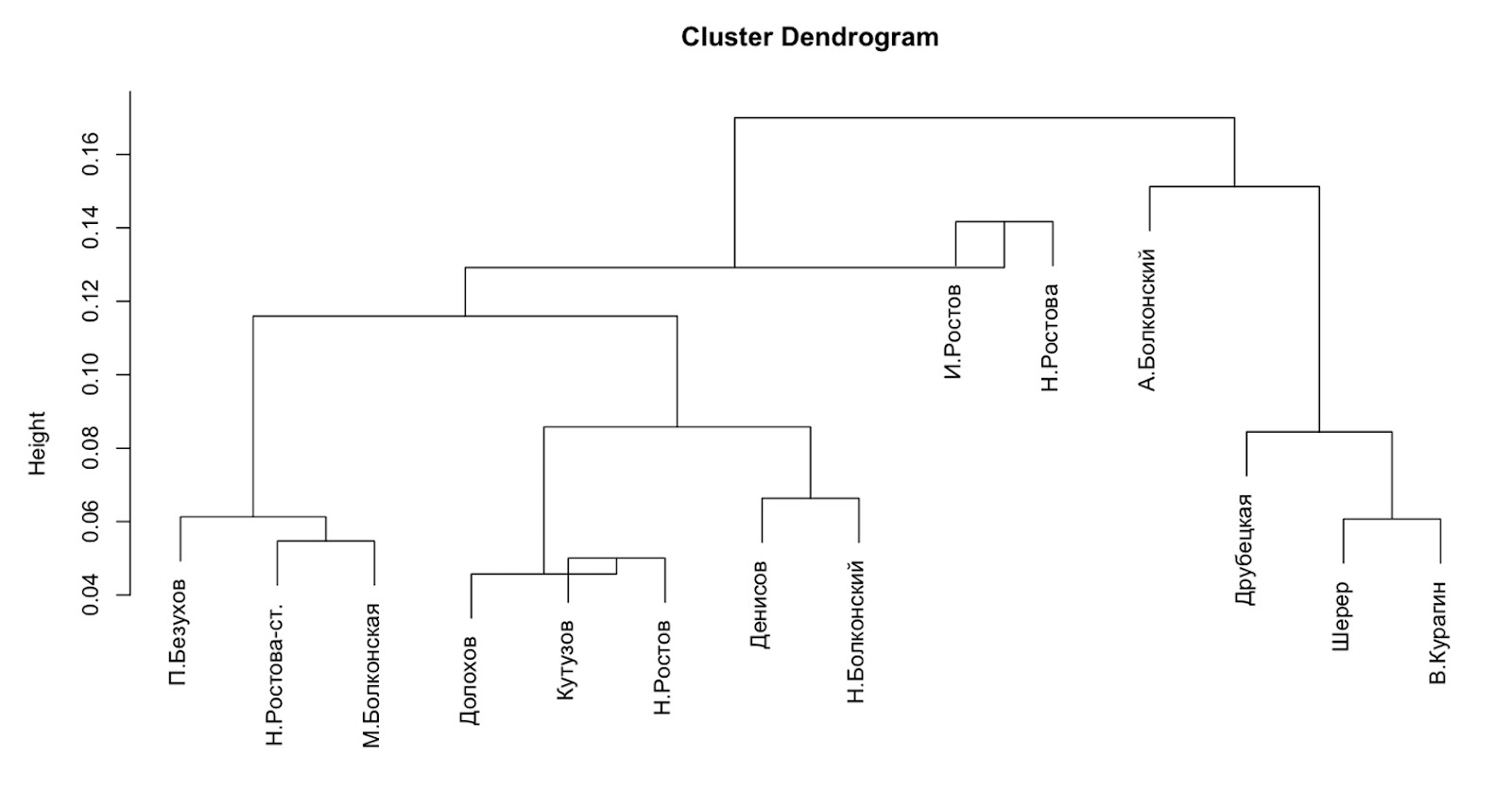
Посмотрим теперь на результаты иерархической кластеризации. Они схожи с показателями стилометрии, но имеют несколько важных отличий. Во-первых, сразу замечаем, что персонажи разделены на большее количество групп, причем по парам: Илья и Наташа Ростовы, Денисов и Николай Болконский, Василий Курагин и Анна Шерер. Каждую из этих пар объединяют не только похожие показатели параметров нелексической речи, но и темперамент. «Ростовская непосредственность» Ильи и Наташи, прямодушная резкость Николая Болконского и Денисова, цинизм Курагина и Шерер, — предыдущий метод кластеризации не смог определить эти свойства персонажей.
Во-вторых, Андрей Болконский снова образует отдельную группу, что тоже объясняется «сухостью» его речи. Более того, Толстой, используя эту особенность речевого портрета Болконского, указывал на высокомерие князя Андрея. Получается, что результаты метода кластеризации на основе нелексических параметров речи могут раскрывать авторские приемы и применяться для создания специфического портрета персонажей.
Заключение
Таким образом, при помощи двух методов можно анализировать речевые портреты литературных героев и на основе полученной статистики моделировать систему персонажей. Стилометрический метод основан на анализе частотностей слов в репликах персонажей и на том, как эти частотности соотносятся между собой. Однако этот метод довольно сложно интерпретировать, так как он зависит от содержания реплик. Поэтому стилометрический метод лишь ограниченно применяется для анализа системы персонажей. Это отличает его от метода оценки нелексических признаков, который создает более дробную классификацию и уже позволяет ее интерпретировать. Другими словами, этот метод больше показывает то, как (a не что) говорит персонаж.
Количественные методы анализа объединяет то, что они иллюстрируют статистические данные, которые цифровые филологи могут использовать для проверки различных литературоведческих гипотез. Но у этих методов есть весомый недостаток — они требуют большой объем текстовых данных на вход. Даже в такой эпопее, как «Война и мир», модель персонажей состоит только из наиболее «разговорчивых» героев, которая к тому же остается статичной, потому что объема корпуса прямой речи не хватает для стилометрического анализа изменения речевых портретов персонажей по ходу сюжета. Поэтому для более глубокого исследования применяются другие методы анализа системы персонажей, например, сетевой анализ.