
Сюжет художественных произведений завязан на персонажах и их действиях. Авторы датасета BookWorm изучили [1], насколько хорошо большие языковые модели (LLM) выявляют действующих лиц в длинном тексте, описывают их и анализируют образы.
Понятие «длинный текст» — относительное, но контекстное окно LLM не позволит обработать «Войну и мир» за раз. Произведение придется делить на части, что может обеспечить утрату информации. Кроме того, героев в подобном произведении много, и они меняются по ходу сюжета. Все это может представлять сложность для моделей.
Не забудем также, что персонажи взаимодействуют друг с другом. Исследователи [1] вводят понятие «Объединенное описание персонажей» (англ. Joint Character Description) как раз для того, чтобы учесть пересечения между образами героев.
Датасет BookWorm
В датасет BookWorm вошли персонажи классических произведений (романов, пьес, поэзии), доступных в проекте Gutenberg. Описания героев составлены пользователями сайтов Litcharts, Sparknotes, Gradesaver и Cliffsnotes, их анализ — читателями Sparknotes, Shmoop и Cliffsnotes. Авторы набора данных опустили описания, длина которых меньше 30 слов, и аналитические тексты короче 200 слов, так как они не подходят для исследования совокупности персонажей длинных произведений. Кроме того, обычно такие заметки относятся к второстепенным персонажам. Пример описания и анализа из датасета можно увидеть на Рис. 1.
![Рисунок 1. Пример описания и анализа персонажа из датасета BookWorm. Источник: [1]](https://sysblok.ru/wp-content/uploads/2025/05/image3.png)
Забавный факт: вы не найдете сам датасет в сети. Нигде. Вам придется самим соскрейпить данные по ссылкам на гитхабе с помощью машины времени архива интернета (Internet Archive Wayback Machine). Авторам пришлось поступить так из-за политики вышеперечисленных литературных ресурсов, которая запрещает распространять хранящиеся там материалы.
Статистику можно увидеть в Табл. 1. Средняя длина рассматриваемых произведений превышает 95 тыс. слов. Описания персонажей содержат примерно 88 слов, а их анализ значительно больше — 602 слова (усредненные значения).
Таблица 1. Описательные статистика датасета BookWorm. Источник: [1]
Рис. 2 показывает жанры произведений, из которых взяты персонажи. В основном это были романы и пьесы, реже — поэмы, рассказы и новеллы. В категорию Other авторы отнесли детскую и историческую литературу, биографии.
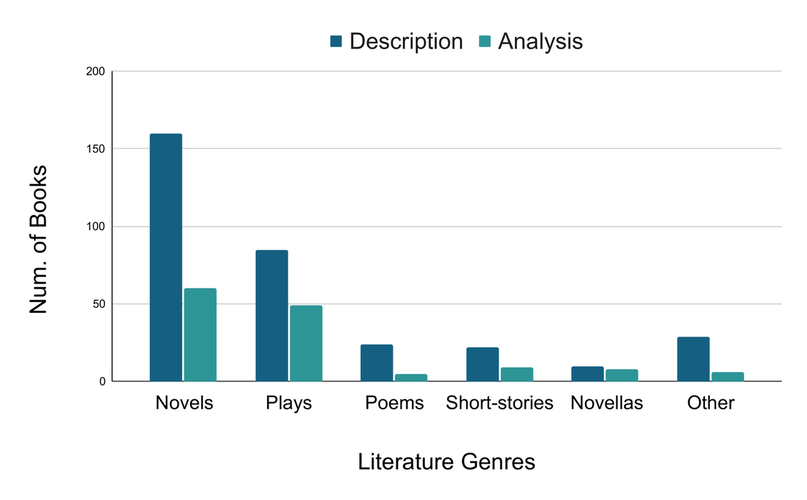
Рисунок 2. Дистрибуция жанров в датасете BookWorm. Источник: [1]
Как нейросети описания персонажей генерировали
Эксперименты по генерации описания и анализа персонажей в этой работе можно разделить на три группы.
- Использование экстрактивной эвристики
Экстракция — (в данном случае) извлечение информации из текста. Для подобной задачи необязательно использовать LLM. Если вы сильно ограничены технически, ищете простое и быстрое решение, можно попробовать эвристику — алгоритм, корректность которого не обоснована математически, но который «работает», хоть и не всегда.
Авторы опробовали следующие варианты:
Улучшенный Lead-k. В базовом виде предполагает извлечение первых k предложений из исходного текста в целом [2]. Вместо всего произведения исследователи использовали только фрагменты, содержащие упоминание персонажа. Для составления списка героев применили библиотеку BookNLP, которая позволяет кластеризовать различные варианты написания имени одних и тех же персонажей. Например, с ее помощью можно объединить Tom, Tom Sawyer, Mr. Sawyer и Thomas Sawyer в единое TOM_SAWYER. Также BookNLP поддерживает разрешение кореференции — позволяет понять, к кому или чему относятся местоимения в тексте.
Рандомное (случайное) извлечение k предложений, в которых упоминается персонаж.
Извлечение идеального (эталонного) варианта (ориг. extractive oracle). Автоматически извлекаются k предложений с наивысшей средней оценкой по метрике ROUGE (можно почитать о ней в оригинальной статье и попробовать самостоятельно приложение от HF) при сравнении с золотым стандартом (здесь — экспертными описаниями персонажей и их анализом, содержащимися в датасете BookWorm). Подробнее об алгоритме см. [2].
Во всех вариантах для описания персонажей k было равно четырем, а для анализа — 25 (выбор чисел аргументирован средним количеством предложений в датасете BookWorm для каждой из задач, см. в Табл. 1 самый правый столбец).
- Использование zero-shot Llama-3-8B-Instruct* [3] (т. е. без дообучения для задачи описания и анализа персонажей)
Модели подавали на вход отрывки произведений длиной чуть более 8000 токенов (потому что ее контекстное окно вмещает именно столько) и оставшееся просто обрезали. Токен — единица деления текста. В контексте работы с LLM токен может быть и целым словом, и слогом, и даже одной буквой — все зависит от конкретной модели. Пример для ChatGPT можно найти здесь.
Исследователи также попробовали улучшить выдачу несколькими способами. Первый предполагал извлечение релевантных отрывков текста (= персонажей и их описания) с помощью алгоритма BM25. На вход подали заранее заготовленный список героев и выявили 80 абзацев, наиболее подходящих по метрике. Для второго способа использовали библиотеку BookNLP. После в обоих случаях — BM25 и BookNLP — найденные фрагменты объединялись в единый текст и подавались на вход модели как контекст (см. промпты ниже).
Последний «подэксперимент» в этой ветке — иерархичная обработка произведений. Для начала текст делился на фрагменты по 8000 токенов, затем для каждого из них генерировалось описание. Финальным контекстом являлось соединенное описание всех фрагментов.
- Тонкая настройка (файн-тюнинг) LongT5-base [4] и уже упомянутой Llama*
Для T5 использовали фрагменты длиной 16+ тыс. токенов (ее контекстное окно позволяет это сделать). Сама генерация проводилась так же, как и в предыдущем пункте. Подробнее о процессе дообучения можно почитать в источнике [1].
Настройки генерации
Исследователи использовали два способа. Первый подразумевал генерацию описания и анализа для каждого персонажа изолированно, второй — для всех персонажей вместе (то самое Joint Character Description). Кроме того, был опробован вариант, при котором модели в промпте дается список всех персонажей с просьбой сгенерировать описание и анализ отдельно для каждого из них.
Для совокупного описания использовали Llama-3-70B-Instruct*, поскольку более маленькие модели не смогли выполнить эту задачу. Однако и у этой LLM возникали проблемы, если в произведении находилось много героев. В таких случаях задачу облегчали: просили описать и проанализировать по пять персонажей за раз или, если и это не помогало, переходили к индивидуальному разбору каждого героя.
Промпты для всех экспериментов с LLM звучали так (наш перевод / оригинал):
- Описание персонажа: Опиши персонажа {имя_персонажа}**, используя следующий контекст. Контекст: [..] / Describe character: {character_name} given the following context. Context: [..]
- Анализ персонажа: Подробно проанализируй персонажа {имя_персонажа}, используя следующий контекст. Контекст: [..] / Analyse in-depth character: {character_name} given the following context. Context: [..]
- Описание персонажа с заранее заданным списком имен: В следующем тексте есть данные персонажи: {список_персонажей} опиши персонажа {имя_персонажа}, используя следующий контекст. Контекст: [..] / The following story has these characters: {list_of_character} describe character: {character_name} given the following context. Context: [..]
- Объединенное описание персонажей: Опиши следующих персонажей: {список_персонажей}, используя контекст, и верни ответ, как в примерах \n\n*** {пример_1} \n\n {пример_2} \n\n {пример_3}. Контекст: [..] / Describe the following characters: {list_of_character} given the following context and return your output as in the following examples \n\n {example_1} \n\n {example_2} \n\n {example_3}. Context: [..]
** Фигурные скобки при работе со строками на Python означают место для вставки текста из переменной.
*** Знак \n обозначает один перенос строки.
Как оценивать качество генерации описаний
Оценить вручную качество автоматической генерации текста на основе множества романов, пьес и других произведений весьма сложно, поэтому авторы автоматизировали процесс.
Лексический уровень: совпадение с данными BookWorm
Первым делом исследователи сравнили полученное описание и анализ персонажей с их идеальными вариантами (подготовленными людьми вручную).
Использованные метрики:
- Rouge F1 — информативность описания или анализа по сравнению с золотым стандартом;
- Rouge-1 — совпадение по униграммам (= отдельным словам);
- Rouge-2 — совпадение по биграммам (= сочетаниям из двух слов);
- Rouge-L — самая длинная общая подпоследовательность между выходными данными модели и текстом золотого стандарта (= самая длинная строка, которая есть и в сгенерированном, и в «идеальном» тексте);
- Entity mention recall — процент именованных сущностей (англ. named entities; имена людей, организаций, географических объектов и т. п.), имеющихся в золотом стандарте и включенных в вывод моделью;
- BERTScore — похожа на ROUGE, но учитывает совпадение не строк, а контекстуальных эмбеддингов (векторов слов). Описана в статье (для нее тоже есть приложение).
Фактологический уровень
Вопросы и ответы (Question-Answering, QA)
С помощью GPT-3.5 исследователи составили список вопросов и ожидаемых ответов по описаниям персонажей из датасета. Затем дообучили RoBERTa-large и использовали ее для поиска информации в сгенерированных текстах. Ответы оценивались по F1 и точности совпадения (exact match). Чем выше качество, тем более удачное (с т. з. фактов) описание персонажа выполнила модель (Llama*, T5).
Следование
Здесь использовали модель T5-XXL [5] для расчета вероятности, что сгенерированное описание или анализ следует из исходного текста.
LLM-as-a-judge
Тут попросили другую модель, GPT-4o-mini, оценить работу «коллег».
Сначала опробовали метрику PRISMA [6].
PRISMA-precision — извлекаем факты сгенерированного текста и спрашиваем LLM, есть ли подтверждение этим фактам в золотом стандарте.
PRISMA-recall — извлекаем факты из золотого стандарта и сравниваем с тем, что есть в сгенерированном тексте.
Затем, используя полученные результаты по двум метрикам выше, рассчитали PRISMA-F1.
Также было решено разделить извлеченные факты на шесть категорий: «Роль» (персонажа в тексте), «Взаимоотношения» (дружба, семейные узы и т. д.), «Личность» (поведение персонажа, характер), «События» (действия и решения, в которые вовлечен персонаж), «Ментальное состояние» (например, убеждения, намерения, эмоции) и «Другие факты», которые не смогли отнести ни к одной из перечисленных групп. Классификация была произведена той же GPT-4o-mini. Для оценки качества разбиения на группы провели ручное аннотирование 200 фактов. Выдача модели высоко коррелировала с работой большинства аннотаторов.
Что удалось найти
- При анализе персонажей на протяжении длины всей книги нет смещения в пользу первых предложений
Вспомните эксперименты с эвристикой: там извлекались из текста k предложений различными способами. Получилось, что экстракция идеального варианта (extractive oracle) сработала лучше всего по метрикам ROUGE, две других эвристики справились плохо по всем параметрам (см. Табл. 2). В задаче анализа персонажа extractive oracle сильно превзошел даже LLM, но это неудивительно, ведь данный подход предполагает дословное цитирование отрывков золотого стандарта.
Таблица 2. Результаты работы использованных алгоритмов и моделей. Лучшие выделены полужирным шрифтом (кроме «эталонного варианта»). EntMent — Entity Mention, BS — BERTScore. Источник: [1]
- Модели с дополнением извлечения информации (retrieval-augmented) показывают наилучшие результаты как в описании персонажей, так и в их анализе
Здесь идет речь про использование BM25 и инструмента поиска персонажей по референции BookNLP для извлечения контекстов с упоминанием героя. При этом результаты иерархичной обработки произведений несколько ниже (см. Табл. 2). Объяснение следующее: в первом случае мы подаем модели на вход только необходимую информацию, во втором — весь текст сразу.
- Среди всех вариантов эксперимента наивысшие результаты были достигнуты дообученными моделями.
А тонко настроенная Llama* с извлечением на основе референции (BookNLP) оказалась самой точной. За метриками можно вернуться в Табл. 2, а результаты QA и следования указаны в Табл. 3.
Таблица 3. Результаты дообученных моделей по критерию следования и ответов на вопросы. EM (exact match) оценивает совпадение ответа на вопрос с ожидаемым вариантом; NLI (natural language inference) используется для оценки следования сгенерированного текста из исходного (следует/противоречит или никак не соотносится). Источник: [1]
Пример анализа, сгенерированного дообученной моделью, можно увидеть на Рис. 3.

- Моделям трудно правильно интерпретировать факты, связанные с событиями и отношениями. Описания ролей и личностей персонажей получили более высокие оценки, чем эти аспекты. И, конечно, результаты по всем параметрам были выше, если моделям подавался на вход нужный контекст (см. Табл. 4).
- Модели лучше справляются с изолированным описанием персонажей, чем с объединенным. LLM поменьше совсем не смогли выполнить задачу (не следовали данной в промпте инструкции) объединенного описания персонажей, более крупная — Llama3-70B-Instruct* — справилась, но слабо. Результаты (см. Табл. 5) получилось улучшить при перечислении в промпте персонажей. Пример объединенного анализа персонажей см. на Рис. 4.
Таблица 5. Качество сгенерированного Llama3-70B-Instruct* описания персонажей в изолированном и объединенном варианте. R-L — Rouge-L, наиболее длинная строка описания, выполненного моделью, совпадающая с экспертным текстом. EntMent — Entity Mention, % сущностей в золотом стандарте, упомянутых в сгенерированном описании. QA-F1 — качество ответов на вопросы. Источник: [1]

TLDR: что сделано и что можно сделать?
- LLM может найти персонажа в тексте, описать его и даже проанализировать;
- (использованным) моделям легче работать с отдельными персонажами, чем со всеми сразу;
- релевантные контексты и дообучение улучшают выдачу моделей;
- в сети есть код для сбора датасета, содержащего описание персонажей классических англоязычных произведений.
Больше примеров результатов и полный набор промптов, а также технические особенности реализации экспериментов можно найти в статье-источнике [1].
Дальше советуем почитать о том, что важнее для персонажа: думать или делать, что говорит о персонажах «Войны и мира» их речь и насколько хорошо LLM пересказывают истории.
* Компания Meta признана властями РФ экстремистской организацией
Источники
- Papoudakis A., Lapata M., Keller F. BookWorm: A Dataset for Character Description and Analysis // arXiv preprint arXiv:2410.10372. — 2024.
- Narayan S., Cohen S. B., Lapata M. Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization // arXiv preprint arXiv:1808.08745. — 2018.
- Grattafiori A. et al. The llama 3 herd of models // arXiv preprint arXiv:2407.21783. — 2024.
- Guo M. et al. LongT5: Efficient text-to-text transformer for long sequences // arXiv preprint arXiv:2112.07916. — 2021.
- Raffel C. et al. Exploring the limits of transfer learning with a unified text-to-text transformer // Journal of machine learning research. — 2020. — Т. 21. — №. 140. — С. 1–67.
- Mahon L., Lapata M. A modular approach for multimodal summarization of TV shows // arXiv preprint arXiv:2403.03823. — 2024.

