
На борьбу с фейками вышли ученые из университетов США совместно с японскими коллегами. Они разработали метод обнаружения фейковых новостей с помощью измерения разнородности тем. Оказывается, для фейковых новостей характерна меньшая тематическая разнородность сообщений. Эта находка может помочь фильтровать информацию и очищать ее от «вбросов» в полуавтоматическом режиме. Рассказываем, как ученые выяснили особенности фейковых новостей, какие алгоритмы они использовали и чем может объясняться обнаруженное различие.
В начале был… взрыв
После восточно-японского землетрясения 11 марта 2011 года в социальной сети Twitter распространилось множество слухов о взрыве на нефтехимическом комплексе, принадлежащем компании Cosmo Oil. Посты были о взорвавшихся нефтяных резервуарах и выбросе в воздух вредных веществ. Многие пользователи призывали не выходить на улицу, чтобы избежать токсичных дождей. Все это спровоцировало массовую панику, которая длилась до тех пор, пока правительство не выпустило официальные новости с опровержением. Только после этого дезинформация остановилась.
То есть во время землетрясения магнитудой от 9 до 9.1 фейковые новости провоцировали еще большую панику. Пугающие псевдо-новости мешали адекватно воспринимать информацию, отвлекали ресурсы от реальной спасательной операции и подвергали людей опасности.
Луч света в царстве фейков
Метод обнаружения фейков, который выявили ученые, заключается в вычислении разнородности тем с помощью подхода «микро-кластеризации». Обычная кластеризация — это метод анализа данных путем упорядочивания этих объектов в сравнительно однородные группы.
Микро-кластеризация, в отличие от обычной, собирает данные в более мелкие однородные группы и создает набор тем, каждый из которых состоит из одного или нескольких кластеров. Затем с помощью алгоритма «полировки» данных (в оригинале: «Data polishing») начинается процесс извлечения микрокластеров. В данном случае в микрокластеры объединяются ключевые слова из твитов о взрыве на нефтехимическом комплексе.
Далее исследователи анализировали изменение тематики в кластерах. При этом вычислялась мера разнородности тематики, учитывающая как количество кластеров, так и количество слов в одном кластере.
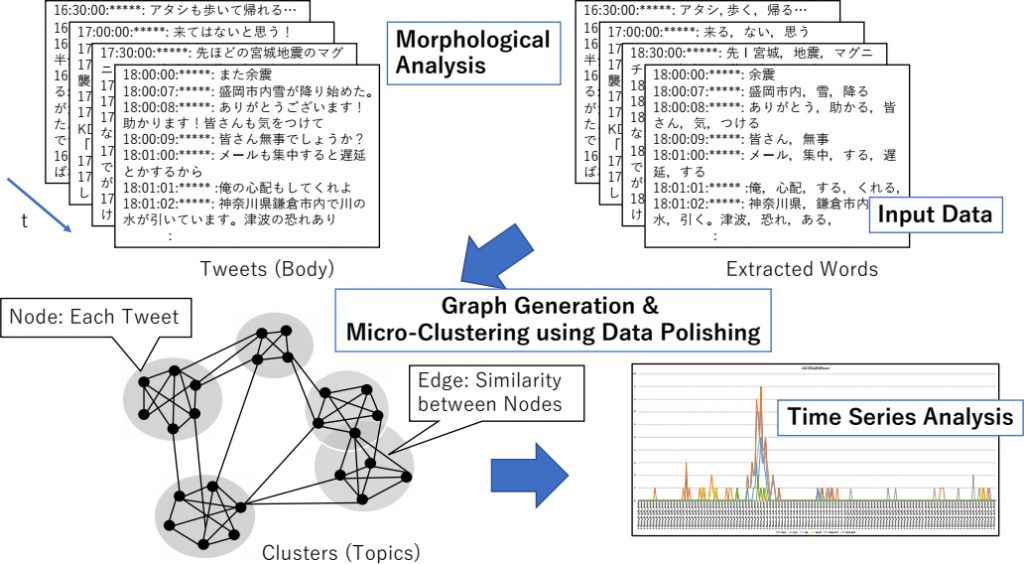
Схема метода:
Сначала строится график твитов: каждый твит является узлом, а ребро между двумя узлами представляет собой два твита, чье сходство по коэффициенту Жаккара больше 0,3. Это входные данные. Затем группы ключевых слов извлекаются микро-кластеризацией с использованием метода Data Polishing
И что, это сработало?
Ученые пришли к выводу, что сообщения о реальных событиях отличаются от фейков большей разнородностью. Объясняют это тем, что люди, которые пишут правдивые твиты, могут менять свое мнение и содержание постов, получив новую информацию. В результате показатель разнородности возрастает, даже если количество твитов не увеличивается. А вот пользователи, которые пишут в Твиттере фейковые новости, продолжают отстаивать свое мнение, упирая на одни и те же (ложные) утверждения. Соответственно, уровень «разнородности мнений» остается прежним и количество кластеров не меняется, даже если количество твитов увеличивается.
Выражаясь тезисно, ученые применили следующий рецепт:
У нас есть входные данные, то есть твиты о событии, из которых извлекли ключевые слова, проанализировали их в течении определенного времени и выявили уровень «разнородности» мнений в кластерах, из чего сделали вывод, какие твиты фейковые, а какие нет.
Как это устроено изнутри?
Мы уже знаем, что микрокластеры — это группы записей, которые имеют высокий уровень схожести, то есть, твитов, которые включают одинаковый набор слов. Для того, чтобы создать микро-кластеры с похожими твитами, перебираются максимальные кластеры (группировки), проще «МК». Эти «МК» связывают твиты, если они принадлежат одному кластеру, если же точки можно отнести к двум кластерам, то они считаются двусмысленными.
Микро-кластеризация создает набор тем, каждая из которых состоит из одного или нескольких кластеров. Затем переходы по темам анализируются путем расчета разнообразия кластеров, составляющих тему. Микро-кластеры — это группы похожих или связанных записей.
Откуда берутся данные?
Данные ученым предоставила компания по мониторингу социальных сетей Hotto Link Inc. х. Это более 200 млн. твитов, которые были сделаны во время землетрясения. Отслеживались пользователи, применившие один из 43 хэштегов, таких как #prayforjapan #nhk и #jishin, либо одно из 21 ключевых слов, связанных с катастрофой в период с 9 марта (до землетрясения) и 29 марта (после катастрофы).
Ученые прослеживали последовательность количества твитов каждые 30 минут. Эксперимент показал, что 11 марта за 30 мин. до землетрясения было написано 60–80 тыс. твитов, а сразу после землетрясения за тот же временной промежуток — уже 300–500 тысяч.
«Жизненный цикл» фейковой новости
Ученые выделили четыре этапа развития фейковой истории об аварии на нефтехранилище:
- Факты: около 15:00 11 марта, сразу после землетрясения загорелся нефтехимический комплекс Cosmo OIl в Тибе.
- Фейки: около 19:00 11 марта появились следующие фейковые твитты, которые часто ретвитили:
«Из нефтехимического комплекса в воздух попадают радиационные и вредные химические вещества. Будьте осторожны!»
«Не выходи! Потому что дождь радиоактивен и содержит вредные вещества в результате взрыва нефтехимического комплекса». - Поправки: около 15:00 12 марта (на следующий день после землетрясения) официальный сайт компании Cosmo Oil и твиттер-аккаунт местного правительства объяснили, что взрыва не было.
- 12 марта тему закрыли.
На рис. 2 показан ход фейковых новостей. На графике изображена взаимосвязь между количеством твитов и количеством микрокластеров. Каждый кружок на графике показывает один получасовой период времени.
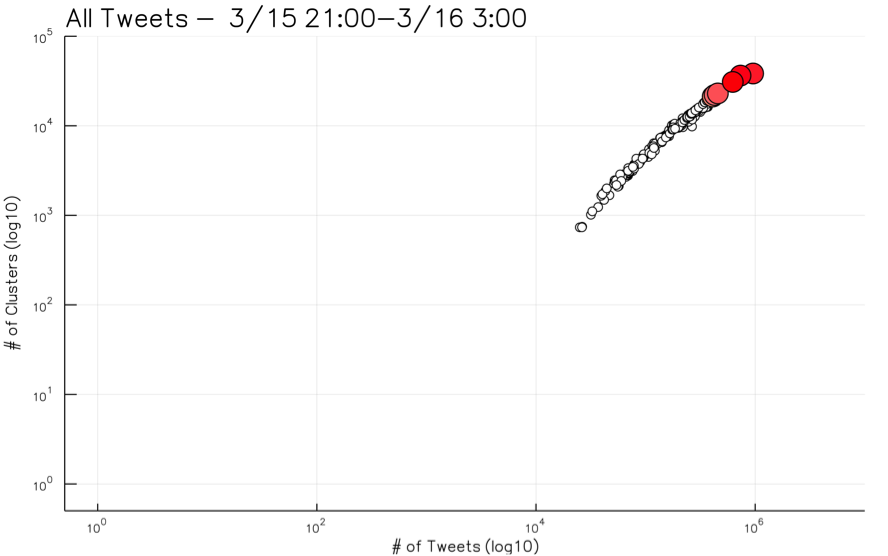
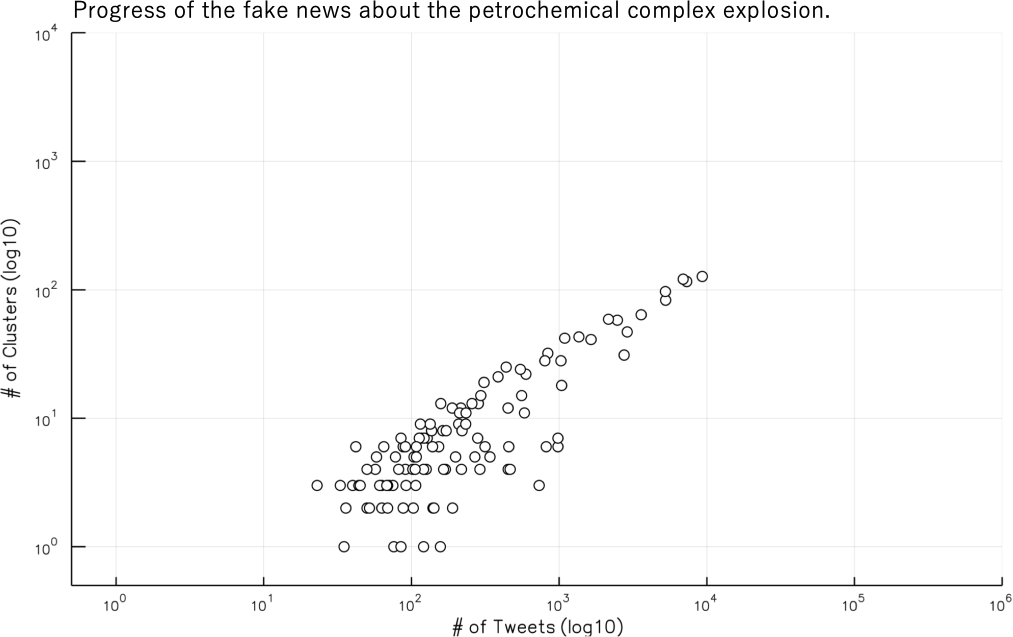
Фейковые новости демонстрируют низкую разнородность тем. Рисунки 2 и 3 иллюстрируют разницу между реальным сюжетом и фейковым. На обоих графиках показана взаимосвязь между количеством микрокластеров и количеством твитов, содержащих определенную фразу, в течение каждого получасового периода времени. На рис. 2 показано тематическое разнообразие фейковых новостей, твитов со словосочетанием «Cosmo Oil»; напротив, на рис. 3 показаны все твиты из набора данных за одно и то же время. Рисунок 3 указывает на реальную историю о Великом Восточно-Японском Землетрясении, в отличие от ложных слухов о взрыве на Cosmo Oil.
Для реальных новостей связь между количеством твитов и количеством микрокластеров является линейной. Т. е., чем больше пользователи пишут о каком-то реальном событии, тем разнообразнее обсуждение.
Для фейковых новостей количество микрокластеров намного ниже, чем количество твитов во многих периодах времени. Ученые предположили, что фейковая новостная лента с большей вероятностью будет иметь меньшее разнообразие тем, поскольку здесь меньше фактов, о которых следует сообщать.
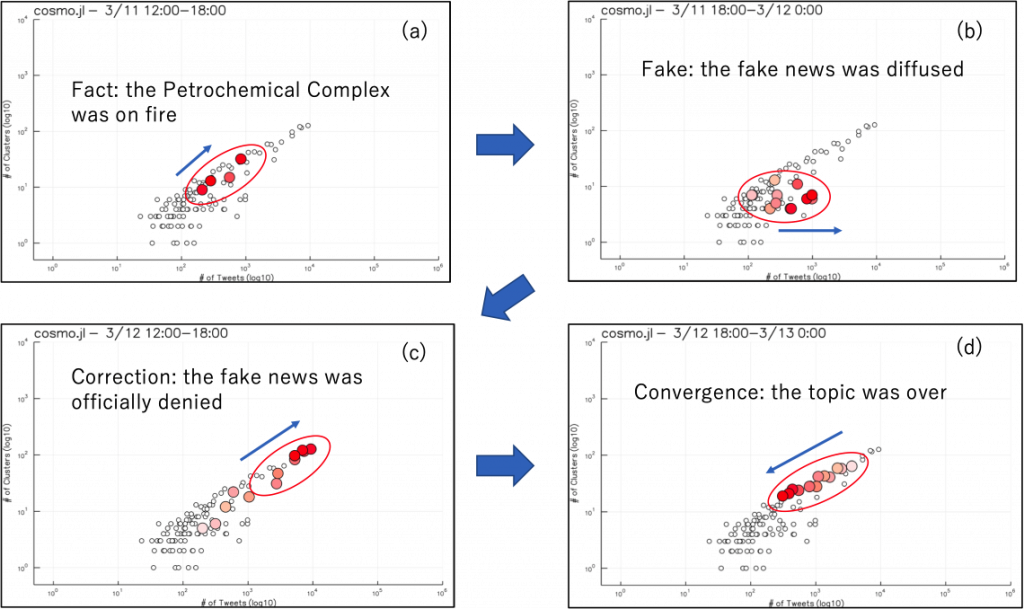
На рисунке 4 показано развитие обсуждения «Cosmo Oil». Сначала появилась правдивая тема (факт пожара на нефтехранилище). Затем «фейковая» тема появилась в виде слухов о взрыве, показанном на рисунке 4 (б). В периоды «факта» и «поправки», «фейковая» тема показывает низкую разнородность тем. Рисунок 4 © показывает период «поправки», когда правительство опровергло дезинформацию и это повлияло на распространение слухов. В то же время количество твитов и кластеров росли пропорционально, и поэтому разнородность увеличивалась.
Наконец, на рисунке 4 (d) показано, что история с Cosmo Oil пошла на спад, в то время как разнообразие тем оставалось высоким, но постепенно количество твитов уменьшилось. Этот процесс показывает динамику изменения темы и ее жизненный цикл.
Источник: The Narrow Scopes of Fake News: Detecting Fake News Using Topic Diversity Measures



