Улыбочку
В условиях карантина коммуникация онлайн становится единственно возможным способом поддержания отношений с друзьями и организации рабочего процесса. В интернете появляются курсы по ведению деловой переписки, но этические нормы в рамках мессенджеров и социальных сетей очень размыты и неустойчивы.
Давайте порассуждаем. Работодатель получил ваш отчет и отправил вам в ответ:
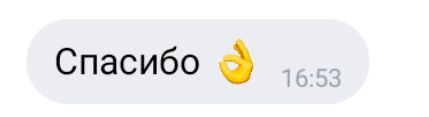
(Спасибо👌)
Что он о вас думает? Что означает этот смайлик?
Тут, кажется, все просто: «Принял!»
А если так?

(Спасибо👌)
«Спасибо, все отлично»? «Спасибо, наконец-то»?
А так?

(Спасибо😏)
Вот тут уже совсем сложно. Зачем думать, если можно попросить об этом компьютер?
С чего все началось
Во второй половине 20 века с развитием технологий, позволяющих расширить границы письменного общения, люди стали писать чаще, больше и короче. Письменная коммуникация стала скорее похожа на диалог, чем на смену монологов, однако коммуникации все еще не хватало главного — невербальных средств.
В 1969 году Владимир Набоков высказал интересную мысль: «Мне часто приходит на ум, что надо придумать какой-нибудь типографический знак, обозначающий улыбку, — какую-нибудь закорючку или упавшую навзничь скобку, которой я бы мог сопроводить ответ на ваш вопрос.» А в 1982 появился первый официальный смайлик. Скотт Эллиот Фалман, американский профессор, предложил использовать сочетание символов «:-)» для обозначения шутки. Уже в 2000-х эмодзи (пиктографические изображения) захватили мессенджеры и Интернет.
Сам концепт эмодзи как коммуникации с помощью картинок возник в Японии и быстро распространился по всему миру. Слово эмодзи тоже японского происхождения и состоит из трех частей: e (изображение) + mo (писать) + ji (символ).
Смайлик сегодня
Сейчас переписку без смайликов представить очень сложно. Они заменяют нам интонацию, жесты и по сути стали главным способом выражения эмоций в письменной речи. Они могут выступать в качестве слов или просто выражать отношение говорящего к ситуации.
Как мы уже заметили, смайлики не всегда легко проинтерпретировать, однако с обычными словами может возникнуть та же проблема. Что мы обычно делаем, чтобы понять значение слова?
Во-первых, мы смотрим на контекст. Часто он помогает понять, что автор имеет в виду. Со смайликами этот метод тоже работает.
Тут сердечко означает благодарность.

А тут настоящую любовь к питомцу.
Во-вторых, если контекст не помогает понять значение слова, мы можем обратиться к словарю. И снова эмодзи похожи на слова! Существует настоящий словарь с описаниями изображений от разработчиков Unicode. Только вряд ли кто-то в него заглядывает…
У смайликов есть одно очень важное отличие от слов — визуальная информация. Глядя на слово мы понимаем его значение, потому что оно уже хранится у нас в голове, а картинку мы сравниваем с образами из повседневной жизни и поэтому можем угадать значение по визуальному сходству проявлений эмоций или ситуаций.
При чем же тут цифровые исследования?
Дело в том, что современные специалисты в области NLP используют именно эти три основные идеи для переноса значения смайликов в машиночитаемый формат.
Ученые уже давно пользуются моделями, переводящими слово в вектор его контекста, то есть совместной встречаемости с другими словами. Word2vec — одна из самых популярных моделей такого типа, основанная на нейросетевых технологиях. Используемый в ней алгоритм Skip-Gram пытается предсказать контекст справа и слева по центральному слову. Почему бы не сделать то же самое с эмодзи?
Если вам хочется узнать больше о том, как работает word2vec, советуем посмотреть нашу статью об этом.
Попытки автоматического анализа эмодзи начались в 2015 году с анализа изображений в Инстаграме — самой «визуальной» социальной сети. Томас Димсон, один из разработчиков Инстаграма, рассказал о своем анализе текстов под постами. Оказалось, что на тот момент в англоязычном Инстаграме каждая десятая подпись под фотографией содержала смайлик.
Программист обучил word2vec на выборке в 50 миллионов комментариев и решил поделиться результатами с пользователями. Оказалось, что самые популярные эмодзи довольно устойчиво ассоциируются с тем, что они изображают. Так, флаги стран соотносятся с хэштегами, содержащими их названия, а смеющиеся смайлики — с сокращениями ‘lol’, ‘lmao’ и различными вариациями смеха. Подробнее об этом исследовании можно прочитать в нашей статье.
Пост Димсона положил начало целому направлению в исследованиях дистрибутивной семантики. Чуть позже вышла статья группы испанских ученых под руководством Франческо Барбери. Ученые представили модель, обученную на текстах англоязычного Твиттера, и проанализировали результаты ее работы.
Для оценки близости смайликов были предложены два критерия:
- Сходство (Можно ли заменить один смайлик с другим?)
- Соотнесенность (Можно ли встретить эти смайлики в одном контексте?)
Группе респондентов было предложено оценить 50 пар смайликов по этим двум критериям. Коэффициент корреляции между оценками людей и сходством, предсказанным моделью, оказался довольно высоким. Ученые считают, что дальнейшие разработки позволят использовать модель в исследованиях коммуникации в интернете.
Кроме того, авторы работы провели кластеризацию 100 самых популярных смайликов. Чтобы было проще заметить близость изображений, авторы визуализировали векторы значений смайликов, предварительно сократив их размерность с 300 измерений до 2 при помощи метода t-SNE. Чем ближе смайлики, тем больше они похожи.
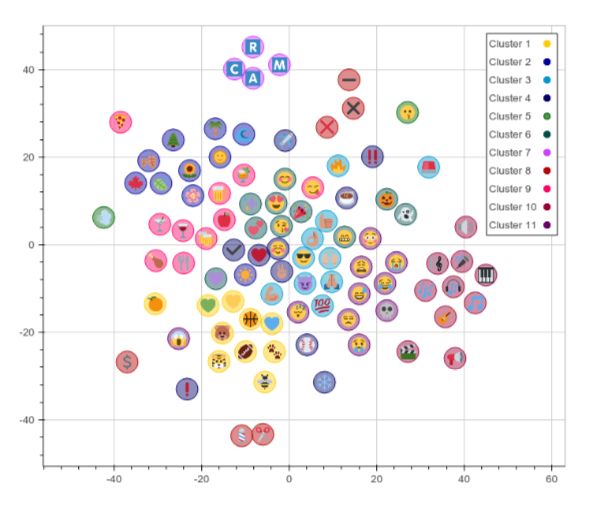
На графике видно, что модель довольно успешно объединяет в группы изображения еды, музыки буквенных символов и растений.
Emoji-арифметика
Лондонские nlp-специалисты решили пойти другим путем. В 2016 году они представили своеобразно расширение для традиционной предобученной модели word2vec — emoji2vec.
Ученые обучили модель на описании 1661 эмодзи. Emoji2vec значительно превосходит своего предшественника по предсказательной силе. Интересно, что для векторных представлений смайликов в ней работает «правило суммы значений». Для обычной модели word2vec его часто описывают так:
король — мужчина + женщина = королева
Математические операции с векторными представлениями действительно работают. С разложением смайлика на элементы значения дело обстоит сложнее, но авторы статьи предложили несколько примеров похожих математических операций над векторами для изображений:

В пятерке наиболее похожих слов есть результаты, удовлетворяющие таким семантическим пропорциям, и это уже очень значимый результат! Подход с анализом словарных статей для смайликов хорош тем, что он не зависит от кодировки смайлика: вектор значения, хранящийся в модели, един для различных вариантов одного изображения.
Последний способ толькования значения смайлика состоит в интерпретации визуальной состовляющей, однако попытки подступиться к ней пока не увенчались упехом. С 2019 года группа программистов из Индии занимается созданием модели, учитывающей как визуальное сходство смайликов, так и сходство векторных представлений их значений.
А что используется уже сейчас?
С 2017 года Яндекс.Переводчик умеет переводить тексты в эмодзи. Он использует «словарный» алгоритм, выбирая изображение, в описании которого используется введенное слово. Конечно, набор эмодзи ограничен, поэтому, если слова в словаре нет, переводчик выбирает слово с самым близким вектором значения и выдает соответствующий смайлик.
Вот так выглядит Системный Блокъ на языке эмодзи:
⚙️ 🗼
Наука не стоит на месте и мы надеемся, что когда-нибудь т9 будет предлагать нам не только слова и их корректное написание, но и анализировать смайлики, отвечая на главный и вечный вопрос: «Что хотел сказать автор?»
Больше о смайликах в науке
- Исследование про смайлики в инстаграме
- Статья о модели, обученной на постах Твиттера
- Статья об emoji2vec
- Исследование визуальных характеристик смайликов и их связи с векторами значений
- Яндекс.Переводчик – бонус для тех, кто любит загадки