
Введение
Faststylometry
Faststylometry — библиотека, позволяющая использовать дельту Бёрроуза. Это не единственный вариант для стилометрии на Python, однако, как пишет Томас Вуд, создатель библиотеки, другие инструменты сосредотачиваются на визуализации результатов, а не на подсчёте вероятности авторства. Он попробовал исправить этот недостаток.
По той же ссылке [1] можно найти исчерпывающий англоязычный гайд, но мы его немного переработали, перевели и пояснили несколько моментов, которые могли бы показаться туманными для начинающих пользователей.
Важно! Увы, fastsylometry работает сейчас только с текстами на латинице. Библиотека была издана в 2023 году, надеемся, она будет развиваться дальше.
Перед началом
Уметь программировать — это всегда здорово, но для нашего тьюториала была сделана тетрадка в Google Colab, не требующая особых навыков. Всё, что вам нужно, — подставлять свои данные и нажимать на кнопку запуска кода (или сочетание клавиш Ctrl+Enter).
Перед началом работы не забудьте скопировать тетрадку на ваш диск, иначе внесённые изменения не сохранятся. Сделать это можно вот так:
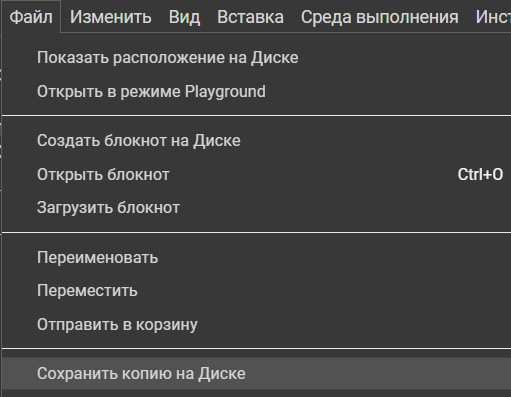
Копирование блокнота с кодом в личное хранилище
Теперь можно перейти к коду.
Всё готово, приступим
Установка/загрузка библиотек и инструментов
Для начала нужно установить саму библиотеку. Сделать это можно вот так:
!pip install faststylometryNB! Если Colab попросит перезапустить сеанс — сделайте это и выполните код в ячейке повторно.
Теперь загрузим нужные для эксперимента модули.
from faststylometry import Corpus
from faststylometry import download_examples
from faststylometry import load_corpus_from_folder
from faststylometry import tokenise_remove_pronouns_en
from faststylometry import calculate_burrows_delta
from faststylometry import predict_proba, calibrate, get_calibration_curveОни дают возможность:
- работать с корпусами текстов,
- рассчитывать значение дельты,
- работать с вероятностями и калибровать модель (об этом ниже).
Faststylometry имеет встроенный токенизатор (инструмент для деления текста на слова), но, к сожалению, он поддерживает только английский язык. Модуль токенизатора импортируйте следующим образом:
from faststylometry import tokenise_remove_pronouns_enОбратите внимание, что встроенный токенизатор удаляет из английского текста местоимения. Считается, что это повышает точность установления авторства [2] на этом языке.
Вы также можете воспользоваться и другим токенизатором. Главное, как пишет Вуд, — инструмент должен превращать текст в список строк (объектов типа str) [1].
Загрузка текстов
Можно поработать с вариантами, которые собрал автор библиотеки с ресурса Project Gutenberg. Задача, которую ставил перед собой Вуд и которую мы за ним повторим, — это определим авторство двух произведений: Sense and Sensibility и Villette.
download_examples()Для эксперимента нужно две папки: train_corpus и test_corpus. В первой должны находиться тексты, в авторстве которых мы уверены, — с их помощью алгоритм выделит присущие писателям особенности стиля. Во второй — произведения, авторство которых мы хотим установить. В таблицах 1 и 2 можно увидеть названия романов, включённых Вудом в тренировочный и тестовый сеты соответственно.
| Тренировочный корпус |
| Jane Austen «Emma» |
| Jane Austen «Northanger Abbey» |
| Jane Austen «Persuasion» |
| Jane Austen «Pride and Prejudice» |
| Charlotte Brontё «Jane Eyre» |
| Charlotte Brontё «Shirley» |
| Lewis Carroll «Alice’s Adventures in Wonderland» |
| Arthur Conan Doyle «The Adventures of Sherlock Holmes» |
| Charles Dickens «Christmas Carol» |
| Charles Dickens «Bleak House» |
| Charles Dickens «David Copperfield» |
| Charles Dickens «Great Expectations» |
| Charles Dickens «Oliver Twist» |
| Jonathan Swift «A Modest Proposal» |
Таблица 1. Состав тренировочного корпуса
| Название | Объяснение имени |
| Currer Bell «Villette» | Реальный псевдоним Шарлотты Бронте |
| Jane Doe «Sense and Sensibility» | Это обозначение женщины, имя которой неизвестно. Используется в США и Великобритании; чем-то сродни нашему «Иванову Ивану Ивановичу» для мужчин [4] |
Таблица 2. Состав тестового корпуса с пояснениями
Если вы хотите проанализировать другие произведения, их можно загрузить непосредственно с личного устройства в Colab.
Для этого нужно назвать файлы особым образом, собрать в архив, загрузить в Colab и затем разархивировать в Colab’е.
Шаблон для названия файлов: автор_-_название (заметьте, он отличается от того, который используется в Stylo). Формат, как обычно, txt, кодировка — UTF-8.
Лучше брать достаточно длинные произведения. Обычно говорят о 5 тыс. словах, реже — 2 тыс., но чем больше — тем надёжнее [3]. В оригинальном гайде автора библиотеки [1], например, тексты романов будут разделены на фрагменты по 80 тыс. слов (мы тоже так сделаем, но ниже).
Загрузим данные в среду Colab. Найдите в меню слева значок папки, нажмите на него. Вы перейдёте в менеджер файлов.
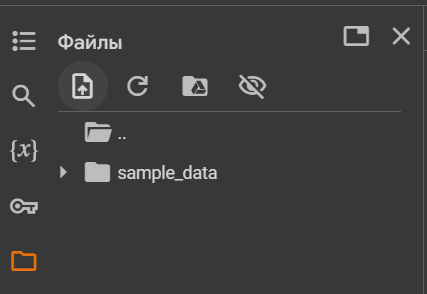
Менеджер файлов Google Colab
Нажмите на самую первую иконку — загрузку файлов. Дальше можно будет выбрать папки с вашего компьютера. NB! Они должны быть заархивированы в zip-архив, иначе файлы нужно будет загружать по отдельности.
Процесс загрузки не быстрый, не пугайтесь. В итоге должно получиться следующее:
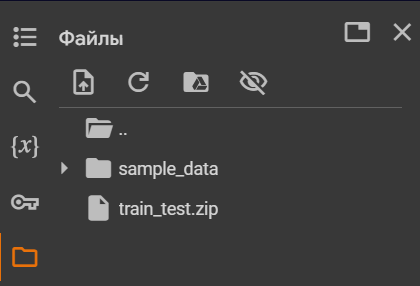
Файлы, загруженные в среду Google Colab
Теперь файлы нужно разархивировать. Для этого используем кусочек кода из исходного файла библиотеки examples.py.
import zipfile
import os
data_path = "data"
os.makedirs(data_path)
with zipfile.ZipFile("/content/train_test.zip", 'r') as zip_ref:
zip_ref.extractall(data_path)
print(f"Extracted contents of zip file to {data_path}.")Корпусы разархивируются в папку data (если она у вас не появилась — нажмите на значок обновления файлов):
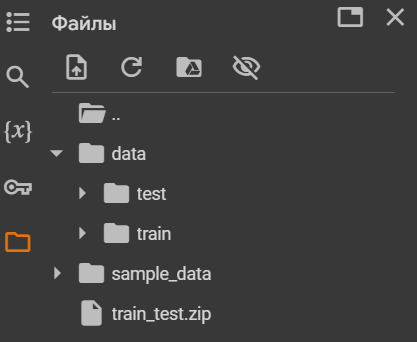
Разархивированные папки с тренировочными и тестовыми текстами
Предобработка текстов
Превратим коллекции в тип данных «Корпус» и токенизируем тексты:
train_corpus = load_corpus_from_folder("data/train")
train_corpus.tokenise(tokenise_remove_pronouns_en)
test_corpus = load_corpus_from_folder("data/test", pattern=None)
test_corpus.tokenise(tokenise_remove_pronouns_en)Посмотрим на результат:
train_corpus.tokens[0][200:210] # Выводим 10 токенов из первого документа тренировочного корпуса
Результат токенизации тренировочного корпуса
Всё хорошо, можно приступить к самой стилометрии.
Ура, дельта
Вводим следующий код:
calculate_burrows_delta(train_corpus, test_corpus, vocab_size = 50)Vocab_size — количество слов, используемых для анализа (подробнее — в статье «Системного Блока» про дельту). Число можно менять.
Получаем таблицу со значениями дельты:
| Писатель | Значение дельты | Значение дельты |
| currerbell — villette | janedoe — sense_and_sensibility | |
| austen | 0.9831 | 0.4483 |
| bronte | 0.4906 | 0.9212 |
| carroll | 1.0486 | 1.3522 |
| conan_doyle | 0.8627 | 1.0175 |
| dickens | 0.7761 | 0.9901 |
| swift | 1.5051 | 1.5567 |
Таблица 3. Результат стилометрического эксперимента
Мы получили какие-то числа, при этом реальные авторы произведений имеют наименьший результат. Хочется узнать, с какой вероятностью писатели являются авторами тестовых произведений. С этим разберёмся в следующем пункте.
Перейдём к вероятности
Для начала откалибруем модель, то есть настроим её, чтобы она посчитала вероятности (может занять некоторое время):
calibrate(train_corpus)Теперь выведем вероятности (Табл. 4):
predict_proba(train_corpus, test_corpus)| Писатель | Вероятность авторства | Вероятность авторства |
| currerbell — villette | janedoe — sense_and_sensibility | |
| austen | 0.2946 | 0.7792 |
| bronte | 0.7489 | 0.3484 |
| carroll | 0.2432 | 0.0873 |
| conan_doyle | 0.4030 | 0.2668 |
| dickens | 0.4882 | 0.2888 |
| swift | 0.0494 | 0.0406 |
Таблица 4. Вероятности, с которыми писатели являются авторами тестовых текстов
Получается, что Шарлотта Бронте и Джейн Остин являются авторами своих романов с вероятностью 75% и 78% соответственно.
Оценка результатов
Насколько правильно модель провела расчёты? Давайте проверим с помощью ROC-AUC. ROC-AUC — это метрика, которая показывает, насколько хорошо модель различает между собой классы. В нашем случае мы пытаемся определить, какой текст к какому автору (классу) относится. Значение AUC измеряет площадь под кривой ROC, где ROC — это график, который показывает долю верных и неверных ответов модели. Чем больше площадь, тем точнее модель.
Найдём значение AUC:
import numpy as np
ground_truths, deltas = get_calibration_curve(train_corpus)
probabilities = train_corpus.probability_model.predict_proba(np.reshape(deltas, (-1, 1)))[:,1]
from sklearn.metrics import roc_curve, auc
fpr, tpr, thresholds = roc_curve(ground_truths, probabilities)
roc_auc = auc(fpr, tpr)
print(roc_auc)Чем ближе значение к 1, тем выше качество модели. Если получится 0,5 — классификация носит случайный характер. У нас вышло 1,0, значит, модель справляется хорошо.
Можно нарисовать ROC-кривую:
import matplotlib.pyplot as plt
plt.figure()
plt.plot(fpr, tpr, color='darkorange', # цвет можно поменять
label='ROC-кривая (площадь = %0.4f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC-кривая работы классификатора дельты Бёрроуза')
plt.legend(loc="lower right")
plt.show()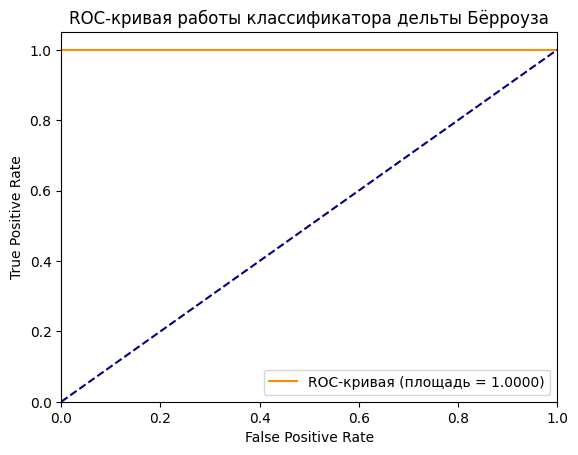
График оценки работы алгоритма
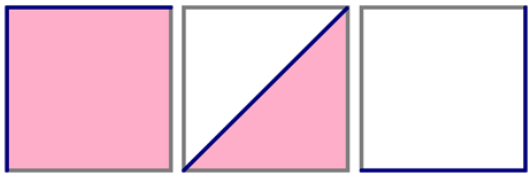
ROC-кривые для наилучшего (AUC=1), случайного (AUC=0.5) и наихудшего (AUC=0) алгоритма. Источник: блог Александра Дьяконова
Что ещё может faststylometry?
Нарисовать график стилистической схожести текстов с помощью PCA. PCA — это статистический метод, который уменьшает размерность модели и также визуализирует данные в двух- и трёхмерном пространстве. Чем более произведения похожи по стилю, тем ближе будут точки на изображении.
Загрузим ещё одну библиотеку и модуль:
import pandas as pd
from sklearn.decomposition import PCAВместо тестового корпуса будем использовать тренировочный. Подгрузим его ещё раз и токенизируем:
test_corpus = load_corpus_from_folder("data/train")
test_corpus.tokenise(tokenise_remove_pronouns_en)Разделим «новый» тестовый корпус на сегменты по 80 тыс. слов. С числом можно и нужно экспериментировать!
split_test_corpus = test_corpus.split(80000)Снова рассчитаем дельту:
df_delta = calculate_burrows_delta(train_corpus, split_test_corpus)Выберем z_scores (подробнее о z-оценке можно почитать в нашем материале про дельту):
z_scores = split_test_corpus.author_z_scoresПостроим модель, чтобы нарисовать двумерный график:
pca_model = PCA(n_components=2)
pca_matrix = pca_model.fit_transform(z_scores.T)Выделим названия авторов и сделаем так, чтобы они отображались на графике:
authors = split_test_corpus.authors
df_pca_by_author = pd.DataFrame(pca_matrix)
df_pca_by_author["author"] = authorsРисуем график!
plt.figure(figsize=(15,15))
for author, pca_coordinates in df_pca_by_author.groupby("author"):
plt.scatter(*zip(*pca_coordinates.drop("author", axis=1).to_numpy()), label=author)
for i in range(len(pca_matrix)):
plt.text(pca_matrix[i][0], pca_matrix[i][1]," " + authors[i], alpha=0.5)
plt.legend()
plt.title("Стилистическая схожесть тренировочных текстов", size=25)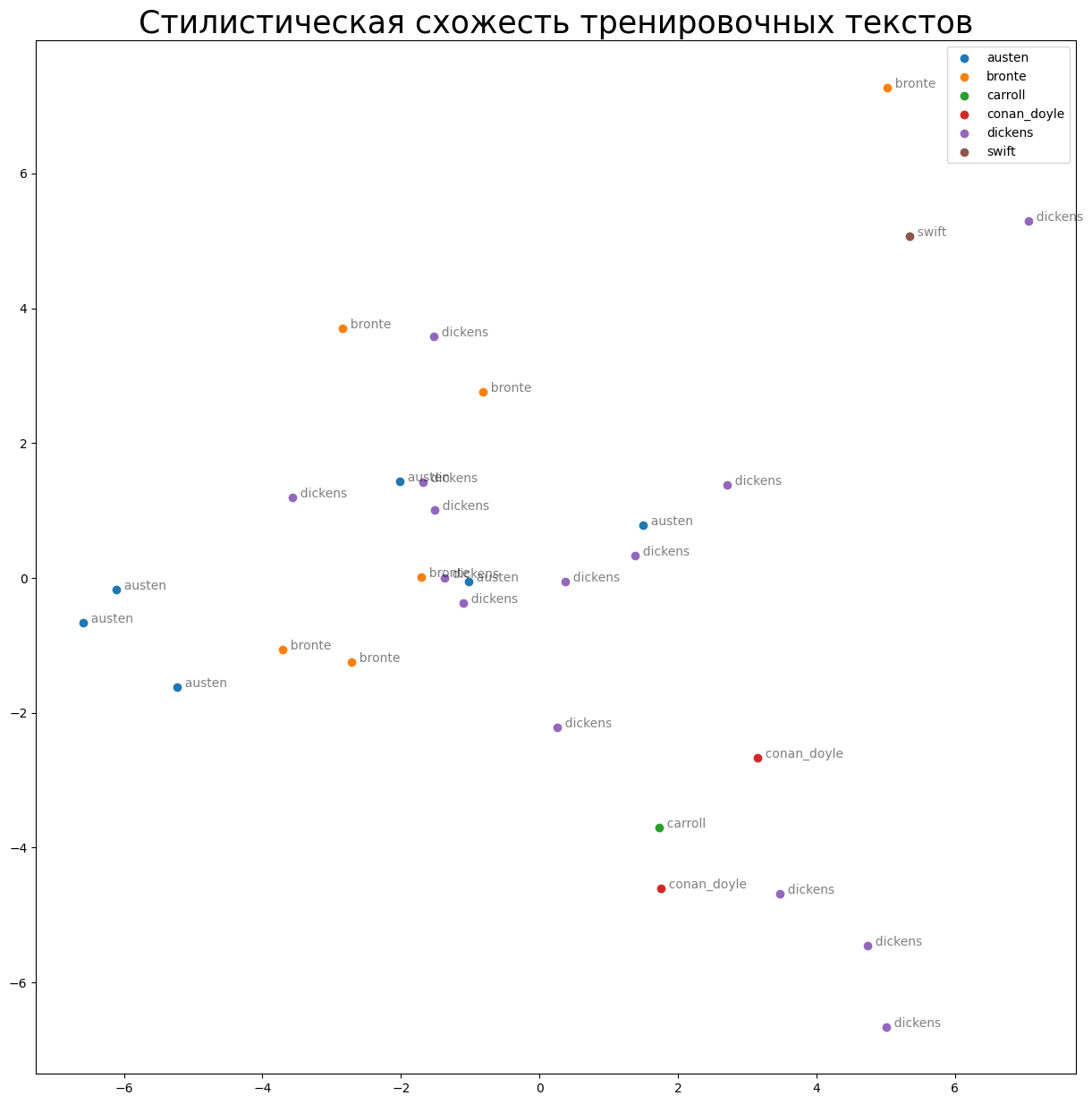
График с использованием PCA
Судя по картинке, некоторые точки с именами Остин, Диккенса и Бронте расположены ближе друг к другу (посмотрите на центр графика). Это значит, что некоторые фрагменты из романов этих писателей похожи по стилевым характеристикам.
Заключение
Итак, сегодня мы научились:
- атрибутировать текст,
- выявлять стилистическую схожесть произведений,
- оценивать результаты работы алгоритма,
- и всё это на Python!
Дальше можно экспериментировать с параметрами и другими текстами. И, конечно, читать стилометрические статьи «Системного Блока»: о загадочной Элене Ферранте, кинодиалогах, древнегреческих текстах и об испанской поэзии.
Источники
- Wood T. A. Fast Stylometry [Computer software] (1.0.4). Data Science Ltd. // Fast Data Science. 28.07.2023 URL: https://fastdatascience.com/natural-language-processing/fast-stylometry-python-library/, DOI: 10.5281/zenodo.11096941 (дата обращения: 15.08.2024)
- Hoover D. Testing Burrows’s delta // Literary and Linguistic Computing, 2004, №19(4). Pp. 453–475.
- Eder M. Does size matter? Authorship attribution, small samples, big problem // Digital Scholarship in the Humanities, 2015, №30(2). Pp. 167–182.
- John Doe // Wikipedia. 28.07.24. URL: https://en.wikipedia.org/wiki/John_Doe (дата обращения: 15.08.2024).
- Дьяконов А. AUC ROC (площадь под кривой ошибок) [Электронный ресурс] // Анализ малых данных. КвазиНаучный блог Александра Дьяконова. 28.07.2017 (дата обращения: 15.08.2024).
- Стилометрия на Python. Jupyter-тетрадка. https://colab.research.google.com/drive/1q2IFYYkgbKIk73h2UVZEsvETjY9RSERD?usp=sharing

