Датасет (англ. dataset), или выборка — это структурированный набор данных, который используется для обучения и тестирования моделей машинного обучения. Это фундамент для разработки и улучшения алгоритмов. Датасеты позволяют моделям «учиться» на примерах и применять полученные знания для решения реальных задач.
Из чего состоит датасет?
Датасет состоит из:
Это сами объекты исследования. Они могут быть разных типов (тексты, изображения, аудио- и видеозаписи).
- разметки (опционально)
Это метаданные или дополнительная информация для описания и классификации данных. Например, в изображениях это могут быть метки объектов на фото, в текстах — выделенные именованные сущности.

Пример разметки текста, где PER — Person — имя человека или группы людей, FAC — Facility —учреждение и CHAR — Characteristic — характеристика человека (звание, профессия, национальность или принадлежность к социальной группе)
В датасете ImageNet собрано около 14 млн изображений. Каждое из них сопровождается меткой класса, к которому принадлежит (например, указана порода собаки или название растения на фото).
Какие бывают датасеты
Датасеты классифицируют по разным признакам. Разберём некоторые из них.
По типу данных:
- изображения: например, ImageNet, ObjectNet,
- тексты: например, корпус исторических дневников «Прожито», датасет «Размечено»,
аудио/видео: датасеты для распознавания речи, эмоций или действий. Датасет ESC-50 содержит в себе звуки окружающей среды, такие как шум дождя, пение птиц или лай собак. Kinetics-700 состоит из 650 тыс. клипов, где каждый клип длится около 10 секунд. Датасет охватывает 700 классов человеческих действий, к примеру, игру на музыкальных инструментах (взаимодействие человека с объектом) или рукопожатия (взаимодействие человека с человеком).
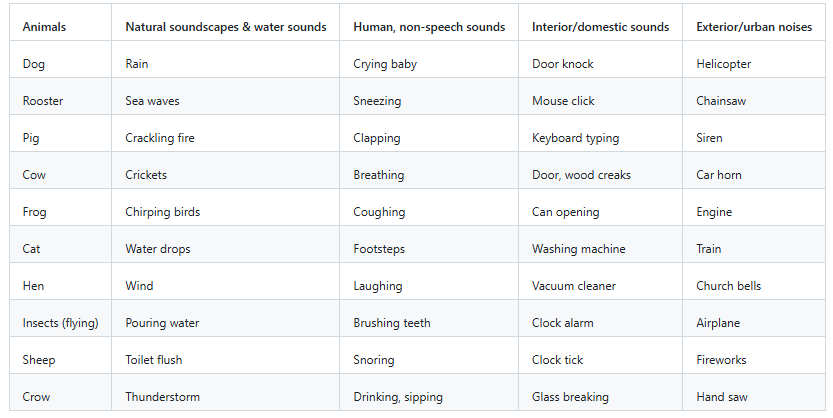
Категории звуков в датасете ESC-50. Скриншот с сайта Github
По способу получения данных:
- реальные данные: собранные из реального мира.
Такие данные собирают университеты и исследовательские лаборатории, например, Stanford и OpenAI. Также существуют open source проекты, такие как Zooniverse, где в сборе данных участвуют волонтёры. Для YMYL-тем (Your Money or Your Life), таких как медицина, финансы и юриспруденция, существуют специальные проекты. Например, в CheXpert врачи участвуют в маркировке рентгенограмм грудной клетки, важных для диагностики и лечения многих опасных заболеваний.
- синтетические данные: сгенерированные алгоритмами или моделями, как в случае использования OpenPose для создания изображений на основе скелетонов. Или тексты, сгенерированные LLM — большими языковыми моделями.
По наличию разметки:
- размеченные датасеты: данные сопровождаются аннотациями,
- неразмеченные датасеты: данные без дополнительной информации.
Выборка для датасета
Чтобы датасет был хорошим, он должен быть репрезентативным — достаточно точным и полным. То есть при создании выборки нужно обратить внимание на:
- разнообразие данных
Для изображений учитываются разные погодные условия, освещение и ракурсы, для текста — стили и контексты, а для числовых данных — диапазоны значений, шкалы.
Например, создатели датасета ObjectNet привлекли фрилансеров для сбора фотографий объектов в неожиданных ракурсах и контекстах, чтобы устранить однообразие, присущее другим датасетам.
- количество данных
Для обучения моделей с высокой точностью требуется достаточный объём датасета. Какой? Зависит от самих данных, модели и её задач.
- качество данных
Они должны быть достоверными, соответствовать действительности и подходить для задач, которые будут решать обучаемые на этих данных модели.
Зачем моделям датасеты
В машинном обучении датасет обычно делят на три части: тренировочную (train), валидационную (validation) и тестовую (test).
Первая нужна для самого обучения моделей. Например, находить именованные сущности в исторических документах — для этой задачи был создан датасет «Размечено».
Вторую часть датасета используют для валидации разных параметров обучения и настроек модели: проверяют, насколько точно и эффективно модели, обученные с разными параметрами, справляются с новыми данными.
Третья часть используется для тестирования финальной версии модели, обученной с оптимальными параметрами, подобранными на валидационной части.
Иногда валидационную часть используют также в качестве тестовой.
Наконец, обученная модель помогает в исследовании похожих наборов данных, позволяя автоматизировать их анализ.
Пример датасета Тitanic
Рассмотрим один из классических датасетов для машинного обучения — про пассажиров «Титаника» и их судьбу.
Датасет Titanic на Kaggle содержит информацию о пассажирах самого знаменитого затонувшего судна и о том, удалось ли им выжить. Вы можете скачать его самостоятельно и открыть в приложении для редактирования таблиц или с помощью кода.
Датасет разбит на два файла — train и test, которые содержат 850 и 459 записей соответственно. Сейчас для нас это разбиение неважно, можем считать, что это один датасет на 1 309 записей.
Каждая запись включает следующие данные:
- идентификационный номер пассажира,
- класс, которым он плыл (1-й, 2-й или 3-й),
- имя, возраст и пол,
- количество родственников на борту,
- номер билета и его стоимость,
- номер каюты,
- порт посадки,
- и другие.
Требуется построить модель, предсказывающую выживание пассажира на основе предоставленных данных. Выживание — бинарная целевая переменная (то есть 1 означает, что пассажир выжил, 0 — не выжил). Проверить точность прогноза можно также с помощью этого датасета.
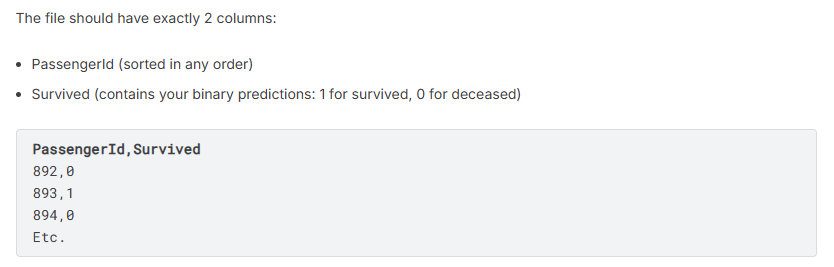
Скриншот из обзора датасета Titanic на сайте Kaggle, где в одной колонке ID пассажиров, а в другой — бинарный прогноз их выживания (1, 0)
Датасет Titanic часто используется как стандартный набор данных для задачи классификации для начинающих в области Data Science. Работая с ним, можно изучить различные методы предобработки данных, обработки пропущенных значений, создания новых признаков и оценки качества модели.
Где искать датасеты?
- Открытые источники и платформы:
- Kaggle: платформа для обмена датасетами и совместного анализа самых разных данных: от характеристик покемонов до мирового уровня преступности. На платформе проводятся соревнования по машинному обучению, где пользователи могут изучать, публиковать и решать задачи в области данных. Kaggle также предоставляет облачные инструменты для экспериментов с моделями.
- HuggingFace: крупнейшее хранилище датасетов и моделей.
- ImageNet: масштабный датасет изображений, аннотированных по категориям, используемый для обучения и оценки моделей компьютерного зрения. Это ключевой ресурс для задач классификации изображений и развития нейронных сетей.
- UCI Machine Learning Repository: один из самых известных источников данных для машинного обучения, предлагающий разнообразные наборы для анализа, от медицинских до финансовых. Репозиторий ориентирован на исследовательские задачи и образовательные цели.
- Государственные ресурсы: Порталы открытых данных различных министерств и ведомств, например, Портал государственных закупок или Открытые данные ПФР.
- data.mos.ru: данные Правительства Москвы, включая статистику, справочники, реестры и другую информацию.
- Исследовательские проекты и инициативы:
- «Прожито»: корпус исторических дневников и других эго-документов.
- «Размечено»: датасет для распознавания именованных сущностей в исторических текстах.
- «Если быть точным»: платформа с данными по социальным проблемам России.
- Самостоятельный сбор данных:
- С помощью Python и различных библиотек, таких как requests, pyquery.
- С помощью фреймворков для веб-скрейпинга, например, Scrapy (Python), можно собирать данные с веб-сайтов в собственные датасеты.