Трансформер придумали ученые из Google Research и Google Brain. Целью исследований была обработка естественного языка, но позже другие авторы адаптировали трансформерную архитектуру под любые последовательности. Сегодня если нейросеть распознает или генерирует текст, музыку или голос, скорее всего, где-то замешан трансформер.
В тексте будут попадаться термины, о которых мы уже писали подробнее. Если нужно, сперва почитайте наши тексты:
- о векторном представлении слов
- о рекуррентности в нейросети, о векторе активации и о том, зачем его куда-то передавать
- о работе механизма внимания в рекуррентных нейросетях и о том, что такое энкодер-декодер
Зачем изобретать трансформер?
Эта нейросетевая архитектура избавляется от рекуррентности, то есть от последовательных вычислений. Можно больше не ждать, пока закончит работу прежний шаг программы, а провести подсчеты параллельно, нейросеть станет работать быстрее. Современные видеокарты как раз заточены под параллелизацию.
Еще данные в трансформере идут по укороченному пути по сравнению с рекуррентной архитектурой. Все благодаря механизму внимания — он фокусируется на отдаленных, но важных словах, и отдает их напрямую в обработку. В результате у нейросети улучшается долгосрочная память.
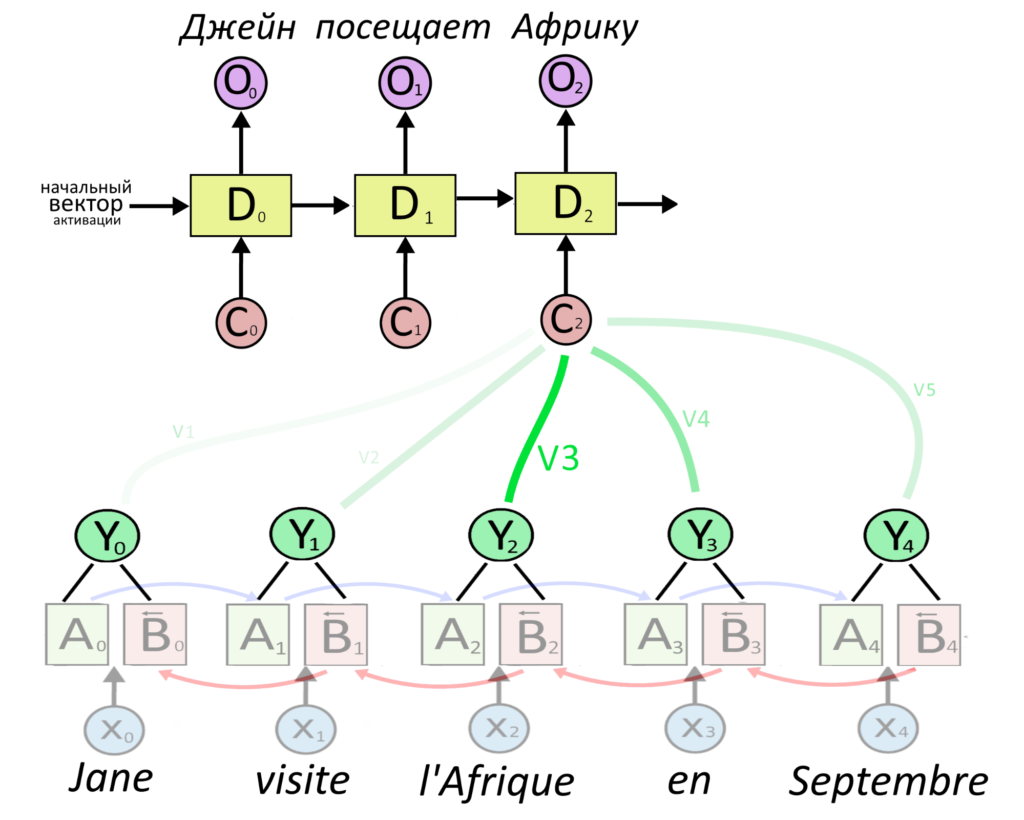
Допустим, надо что-нибудь перевести. Вот схема старого подхода — когда в RNN без внимания слово проходит путь к переводу через всё предложение:
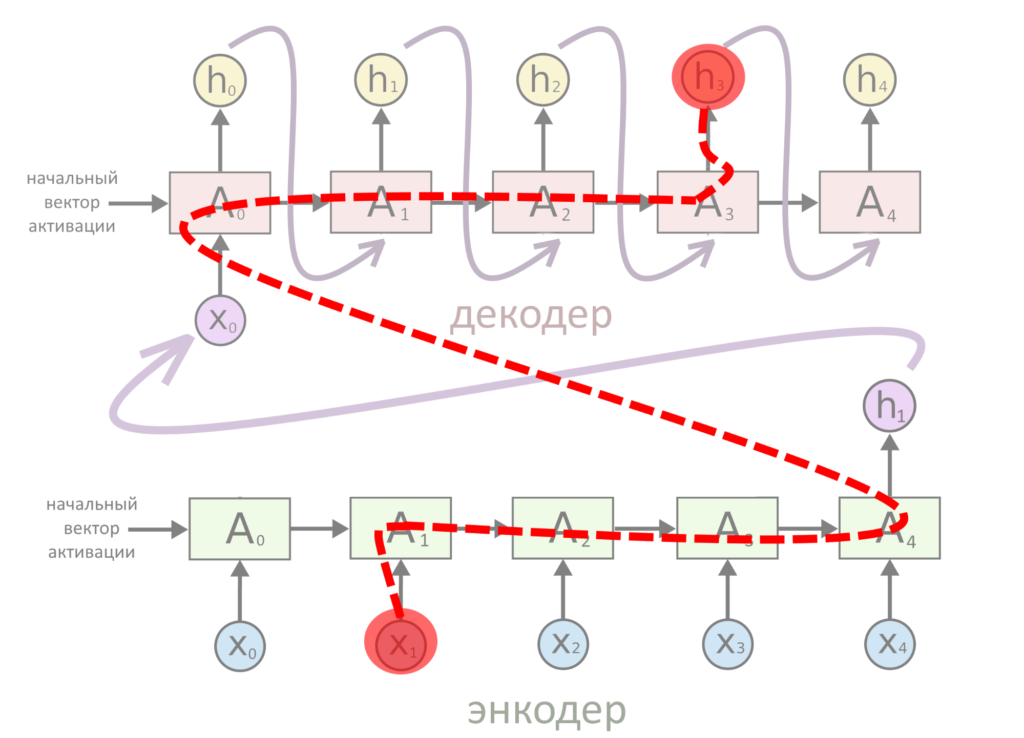
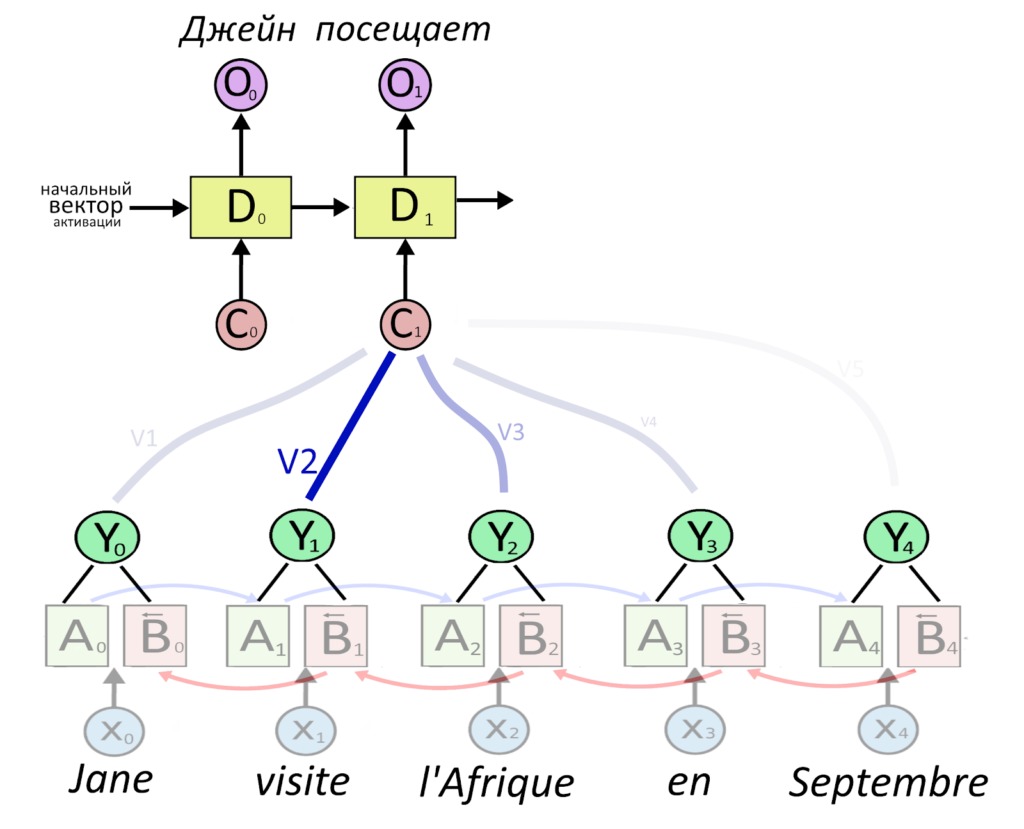
Тут информация передается с энкодера на декодер напрямую. Механизм внимания смотрит на все слова и говорит, что второе слово оригинала важно для выбора второго слова перевода.
Why didn’t chicken cross the road?
Нейросеть-трансформер может проворачивать хитрые лингвистические трюки! Представим предложение: «Курица не перебежала дорогу, потому что она слишком устала».
Из этого предложения компьютеру (но не читателю!) сложно понять, к какому слову относится «она», ведь информация не закодирована в предложении грамматически, она следует из человеческого знания о мире, дорогах и курицах.
Нейросеть-трансформер справляется с разрешением такой неоднозначности, почему — толком никто не знает, но мы расскажем о технических подробностях того, как она это делает.
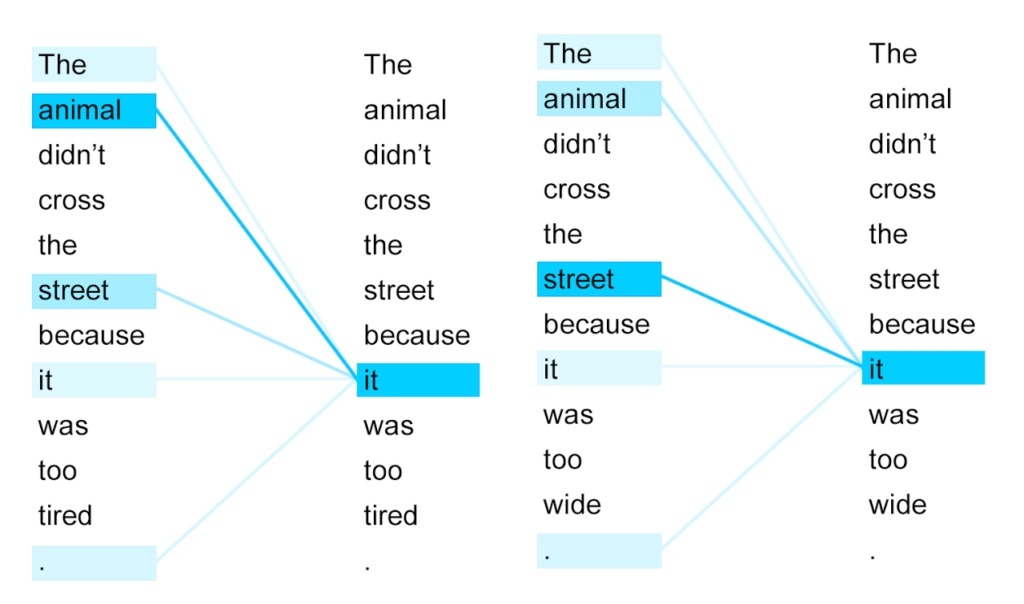
Так визуализируются веса внимания, которые трансформер присвоил словам при переводе английского предложения на французский. В этой задаче правильно перевести it важно, потому что животное и улица — слова разного рода во французском языке.
Еще трансформер хорош, потому что универсален. Архитектуре неважно, какие вектора перемножать и складывать, лишь бы они были подходящей размерности и лишь бы был датасет, на котором можно обучаться. Поэтому трансформер обрабатывают любые последовательности, которые люди научились кодировать векторами.
Если добавить к трансформеру предобучение (об этой идее расскажем отдельно), получится совсем хорошо — что-нибудь вроде GPT-2 или BERT. Если вы знаете Порфирьевича (умеет дописывать за вас истории) — это как раз нейросеть GPT-2, обученная на текстах на русском.
Нейросеть как большой черный ящик
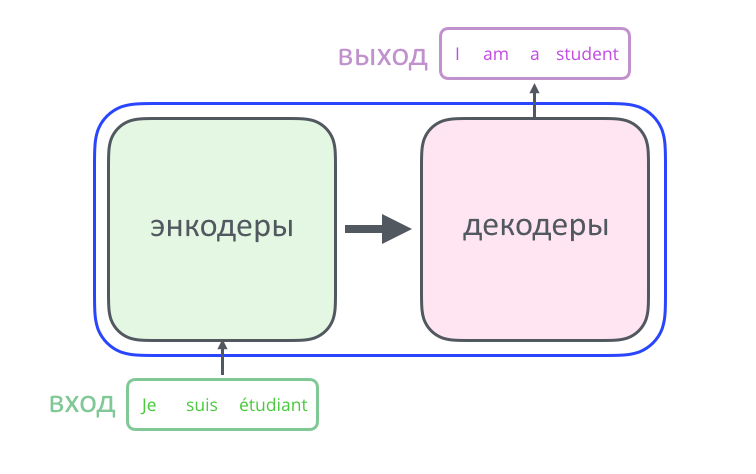
Черным ящиком иногда можно назвать механизм, который выполняет комплексную работу, если для контекста разговора не важно, как он это делает. На первый взгляд нейросеть-трансформер — это «черный ящик», который, например, неплохо переводит текст на иностранный язык.

Внутри ящика трансформер состоит из двух частей: энкодера и декодера. Энкодер кодирует входную последовательность (например, слов) в вектор (т.е. набор чисел), декодер — декодирует ее в виде новой последовательности (например, слов на другом языке, или ответа на вопрос, который изначально пришел на вход в энкодер — смотря как и для чего обучали нейросеть).
Спустимся на уровень ниже: энкодер и декодер в стандартном трансформере содержат по шесть слоев, то есть наборов математических операций. Эту цифру разработчики подобрали опытным путем, ее можно увеличивать.
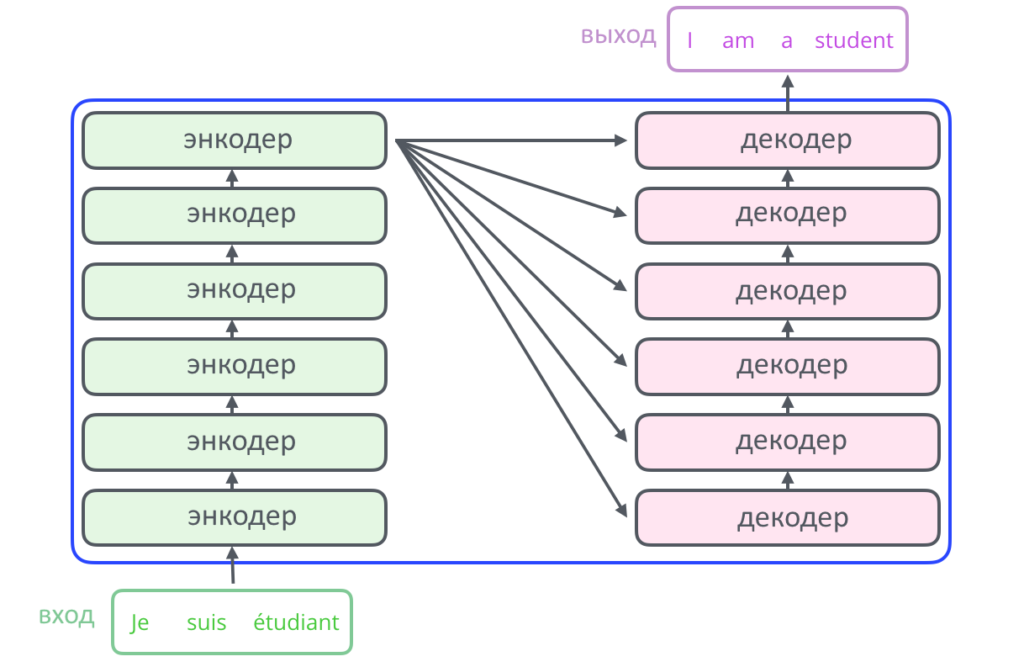
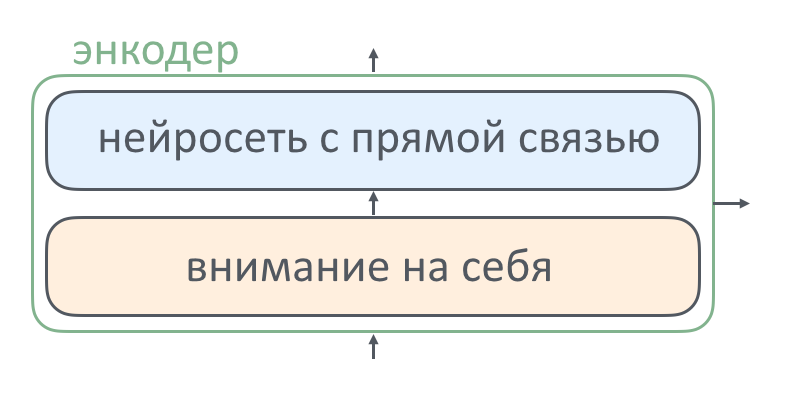
Внутри каждого слоя энкодера есть две составные части: слой внимания и нейросеть с прямой связью. Как работает каждый из элементов и зачем он там нужен, мы расскажем ниже. Декодер в этот текст уже не поместился, про него — в следующей серии.
Внутри каждого слоя энкодера есть две составные части: слой внимания и нейросеть с прямой связью. Как работает каждый из элементов и зачем он там нужен, мы расскажем ниже. Декодер в этот текст уже не поместился, про него — в следующей серии.
Зачем нужен механизм внимания
В тексте про работу механизма внимания мы описали его работу в рекуррентной нейросети. Вектор важного слова умножался на большой «вес», а вектор неважного — на маленький «вес». Вес — это тоже вектор. Взвешенные вектора всех слов складывались и получался вектор контекста, из него делался перевод.
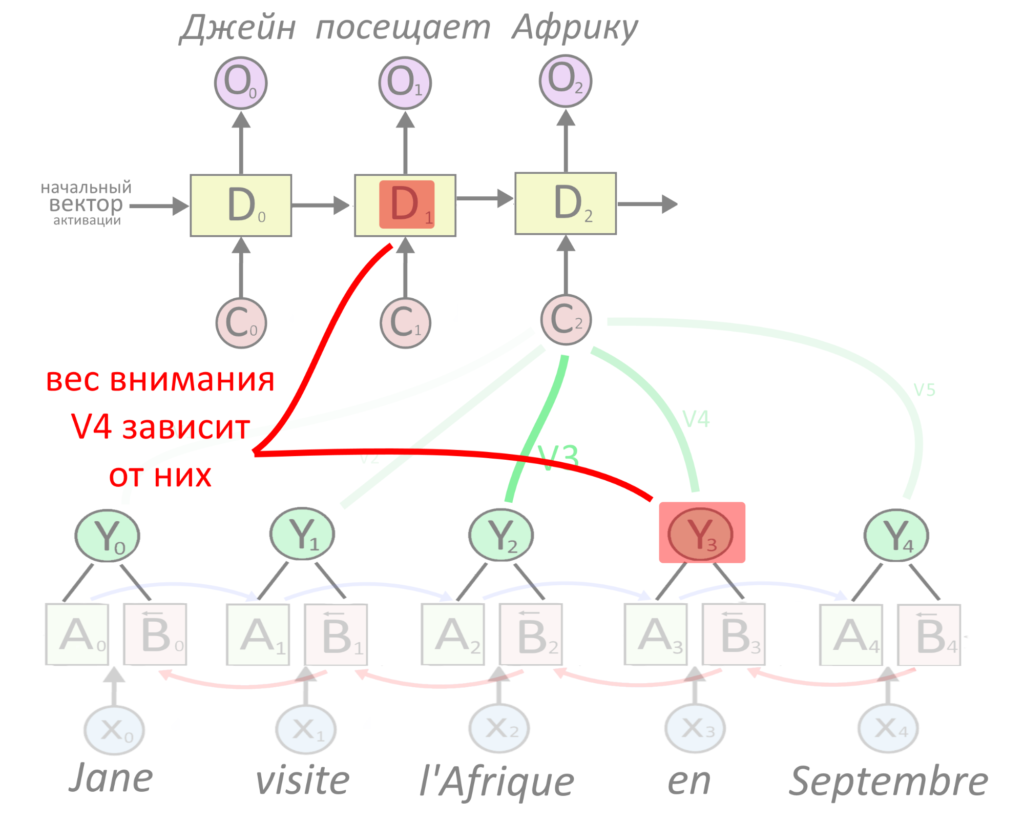
Чтобы решить, важное слово или нет, активацию энкодера нужно было склеить с прошлой активацией декодера, а потом умножить на матрицу весов внимания: она обучается в процессе тренировки нейросети. В начале обучения в матрице случайные числа.
Произведение проходило через функцию активации Softmax, что делало элементы вектора веса неотрицательными и в сумме дающими единицу. Если вектор слова умножить на вектор после Softmax’a, мы как бы выбираем из семантики слова несколько интересных частей, а остальные умножаем на ноль. Сложим эти смысловые «обрезки» всех слов — получится вектор контекста.
Эти принципы появились в 2014 году в академической статье про нейросетевой машинный перевод. Трансформер появился в 2017, и его авторы придумали свою систему терминов и описание механизма внимания, так что ниже речь пойдет почти о том же самом, но другими словами.
Что поместилось в эту статью
- Расскажем, что такое «внимание на себя» (self-attention) и зачем нужна нейросеть с прямой связью
- Введем новые термины, которые придумали изобретатели трансформера
- Расскажем подробнее о dot product attention, «скалярном внимании», (обычно это название не переводят).
- Расскажем о том, как из «скалярного внимания» сделать «взвешенное скалярное внимание»
- Объясним, зачем одну и ту же операцию «взвешенного скалярного внимания» повторять несколько раз с разными настройками: так получится описание «multi-head attention» — «многоголового внимания». Именно этот механизм задействован в нейросети-трансформере.
Что такое self-attention, внимание на себя
В прошлый раз, когда мы описывали внимание, оно было направлено с одной части нейросети на другую.
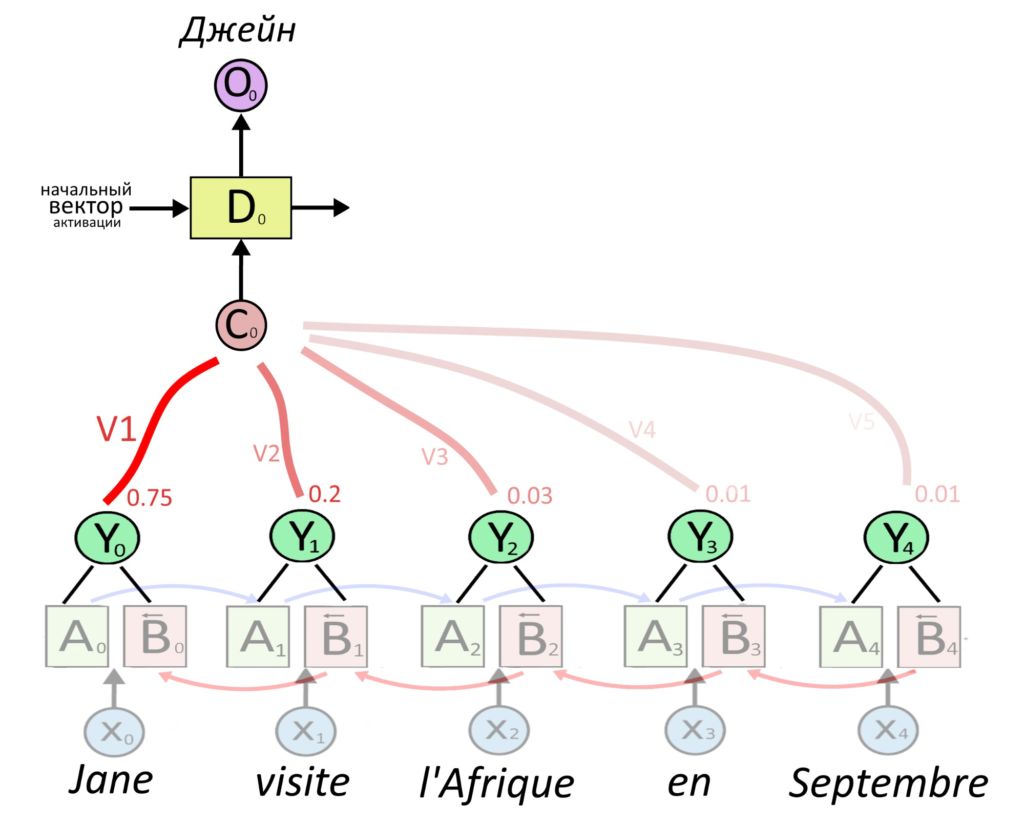
Декодер переводил фразу и одновременно решал, на какой части оригинала сосредоточиться, чтобы сделать перевод точнее.
В трансформере тоже работает подобное, но не в кодирующей части. Здесь применяется self-attention («внимание на себя»). Внимание энкодера обращено на предыдущий слой энкодера, то есть как бы на себя же, но в прошлом.
На самом первом слое предыдущих нет, поэтому трансформер получает «сырые» вектора слов и концентрирует внимание на некоторых из них. Новый вариант входного предложения, где какие-то слова уже помечены как важные, попадает в нейросеть с прямой связью, зачем она там — в следующем разделе. Оттуда переделанный вектор попадает на следующий слой энкодера, и так повторяется 6 раз.

Следующий слой снова добавляет веса каким-то словам (но уже другим, потому что у него другие начальные настройки, то есть веса), результат идет дальше.
Смысл повторения — в том, чтобы каждый новый слой энкодера обратил внимание на что-нибудь интересное, но по-своему.

Вот иллюстрация: оранжевые связи — работа одного слоя энкодера, зеленые — работа другого. Можно сказать, что один слой понял, что животное — это «оно», а другой — что оно «устало». Вместе получается цельная картинка.
Для чего нужна нейросеть с прямой связью
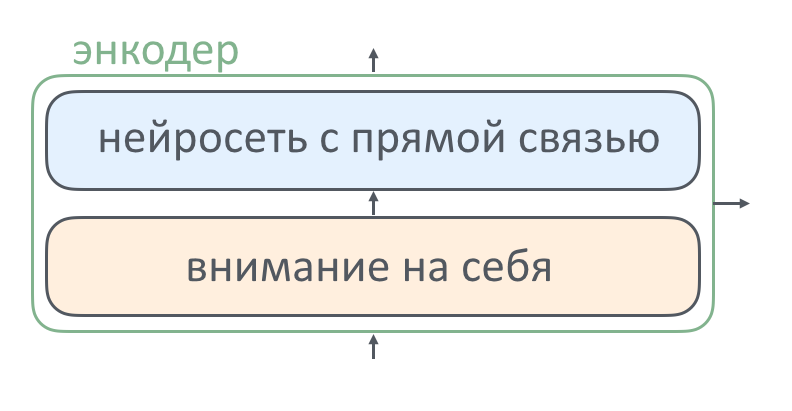
В каждом слое энкодера после слоя внимания идет слой «с прямой связью».
Он нужен, чтобы моделировать более сложные функции. Функции на слое внимания энкодера — линейные. Бессмысленно передавать результат от одной линейной функции к другой по цепочке, добавление новых слоев не усложняет модель и не приближает ее к комплексной реальности. Эта проблема решается, если между линейными слоями внимания добавить слои с нелинейными функциями активации.
В трансформере нейросеть с прямой связью — это матрица весов, на которую надо умножить вектор, нелинейная функция активации, через которую идет результат, и еще одна матрица весов, на которую снова умножается результат. Матрицы весов нужно сначала выучить, в необученной нейросети там случайные числа. После каждого умножения на матрицу добавляется некоторое число, «сдвиг».
Функция активации может быть разной, но стандартный выбор для трансформера называется ReLU. Эта функция сравнивает элемент вектора с нулем, и если элемент положительный — оставляет, как есть. Если отрицательный — вместо него пишет ноль. График ReLU выглядит вот так:
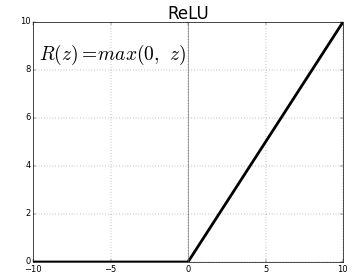
Нейросеть с прямой связью в трансформере — это умножение на матрицу, «сдвиг», функция ReLU, умножение на вторую матрицу, еще один «сдвиг».
Пока непонятно, как работает механизм внимания, но важно, что после каждого его применения результат проходит через нелинейную функцию. Это происходит несколько раз и усложняет итоговую модель.
Теперь разберемся непосредственно с вниманием.
Новые термины для механизма внимания
В публикации про трансформер авторы вводят три новых понятия: запрос (query), ключ (key) и значение (value).
Есть аналогия, которая поможет лучше понять, зачем нужны «запрос», «ключ» и «значение». Представьте, что вы ищете видео на Ютубе. В базе данных Ютуба хранится видео — это значение, V . Там есть ключи K — это набор тегов к видео. Одному ключу, то есть набору тегов, соответствует одно видео, то есть значение. Есть запрос Q — то, что вы пишете в поисковой строке. Запрос Q сопоставляется со всеми ключами (тегами) K в базе данных, находятся самые близкие к запросу ключи, а пользователь получает значения V (то есть видео), сопоставленные найденным ключам.
Итого: дан запрос Q, ищем самые близкие к нему ключи К и выдаем соответствующие значения V
Скалярное внимание, «dot product attention»
Термин из подзаголовка на русский переводится по-разному и нечасто: в этой статье мы выбрали вариант «механизм внимания на основе скалярного произведения», а для краткости будем писать «скалярное внимание».
В разделе про «self-attention» указано, что «внимание на себя» смотрит на предыдущий слой энкодера. Вот, как именно это происходит.
На каждом слое внимания есть три разных матрицы весов — матрицы веса «запроса», «ключа» и «значения». Они заполняются случайно при первом запуске, и выучиваются во время обучения. На каждом слое они разные: так слои учатся обращать внимание на разные вещи и дополняют друг друга.
Вектор с прошлого слоя энкодера (или вектор самого слова, если слой энкодера — первый) умножается на три этих матрицы и получается вектор «запроса» (Q), вектор «ключа» (K) и вектор «значения» (V).
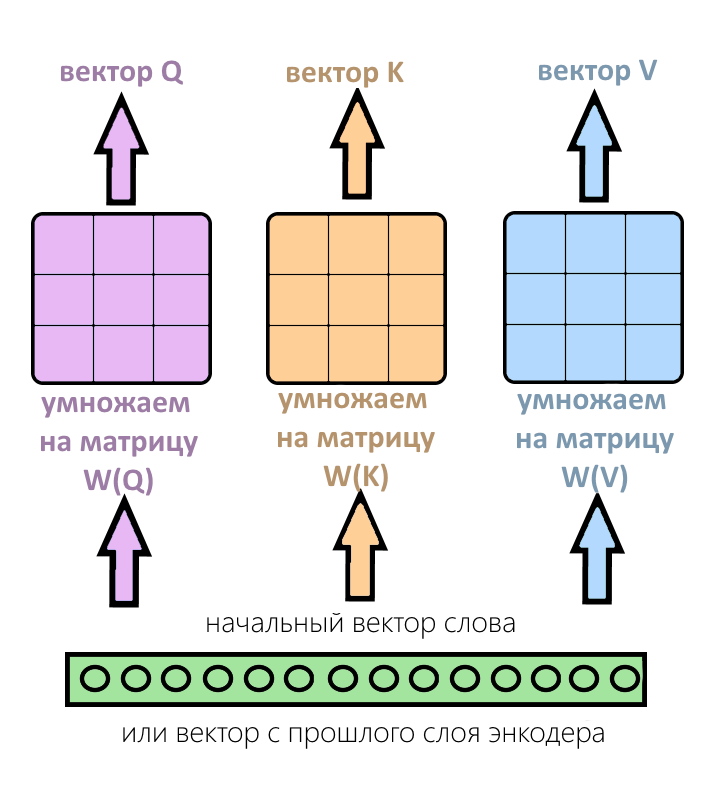
Из входного вектора слова получились три вектора — Q, K, V. Вот, что происходит дальше.
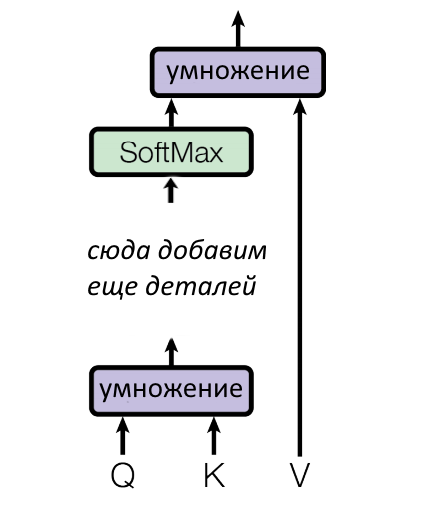
Параллелизация (за которую так любят трансформеры)
В трансформере входные слова обрабатываются параллельно и независимо друг от друга (это одно из важнейших преимуществ по сравнению с рекуррентными нейросетями). Это значит, что у нас только что получилось не одна, а несколько троек Q, K, V — по тройке на каждое входное слово из предложения.
Слова из предложения можно обрабатывать параллельно, если склеить их в матрицы. Один вектор слова — одна строчка. Был вектор слова, стала матрица предложения.
Если надо найти «запрос» Q под каждое входное слово — умножаем матрицу предложения на матрицу весов, и получаем матрицу запросов Q. В ней одна строчка равняется одному запросу, а матрицы умножаются быстрее, чем отдельные вектора по очереди. То же самое работает с матрицами K и V.
Что происходит с матрицами Q и K?
Вспомните аналогию с Ютубом: цель механизма внимания — найти значения V, которые лучше всего подходят под запрос Q конкретного слова.
Для этого матрица с запросами Q умножается на транспонированную матрицу ключей K. Индекс T над K как раз означает транспонирование.
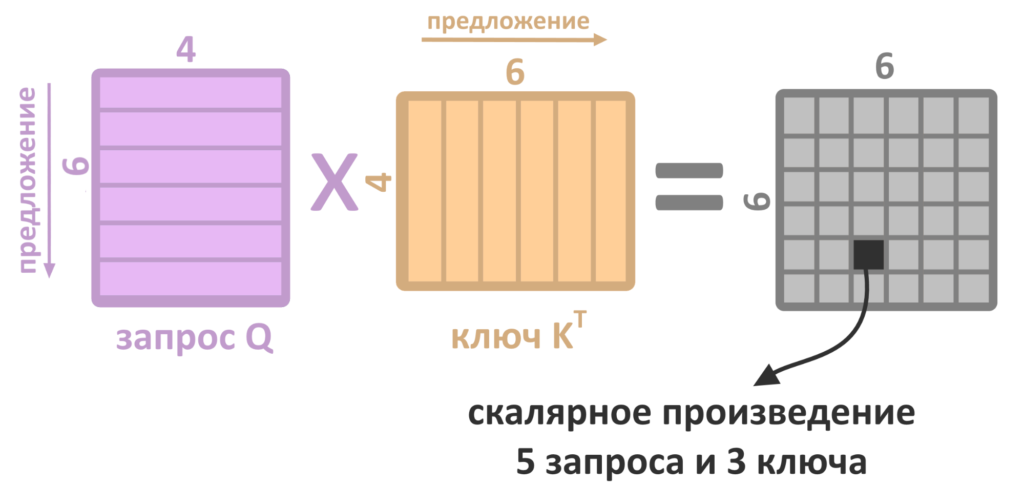
Что происходит при произведении матриц?
Каждая строка матрицы Q — «запрос» одного слова, а каждый столбец транспонированной матрицы K — «ключ» одного слова. Скалярное произведение столбца и строки матрицы — число, которое занимает одну ячейку в результирующей матрице.
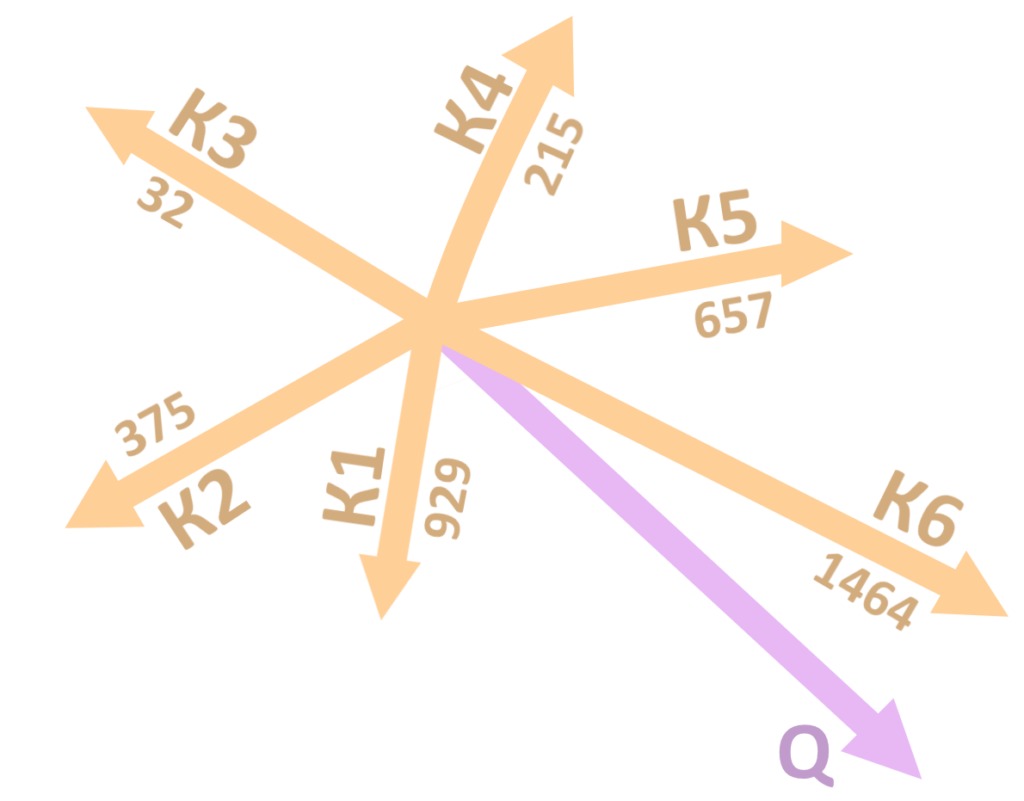
Например, произведение 5 строки Q на 3 столбец K(T) — число, которое займет ячейку в 3 столбце и 5 строке новой матрицы. Строку серой матрицы можно трактовать как набор произведений «запроса» Q одного из слов на каждый из «ключей» K: на первый столбец матрицы К, второй столбец и так далее. Умножать запрос на каждый ключ приходится, чтобы выяснить, какой результат получился самым большим, то есть какой ключ лежит ближе всего к запросу. Но почему большой результат произведения означает, что ключ «близок» запросу?
Вот, в чем дело: большое скалярное произведение получается только у векторов, направленных (примерно) в одну сторону, так работает математика. Запросы и ключи — вектора в многомерном пространстве, почти все они смотрят в разные стороны. Но если направление векторов совпадает хотя бы примерно, скалярное произведение заметно вырастет. Скорее всего, только с одним вектором K скалярное произведение Q получилось большим, а остальные значительно меньше.
Чтобы сильнее подчеркнуть разницу между большим результатом и маленькими, применим Softmax (о том, как работает эта функция, мы рассказывали здесь) к скалярным произведениям данного запроса и всех ключей, то есть к одному ряду серой матрицы.
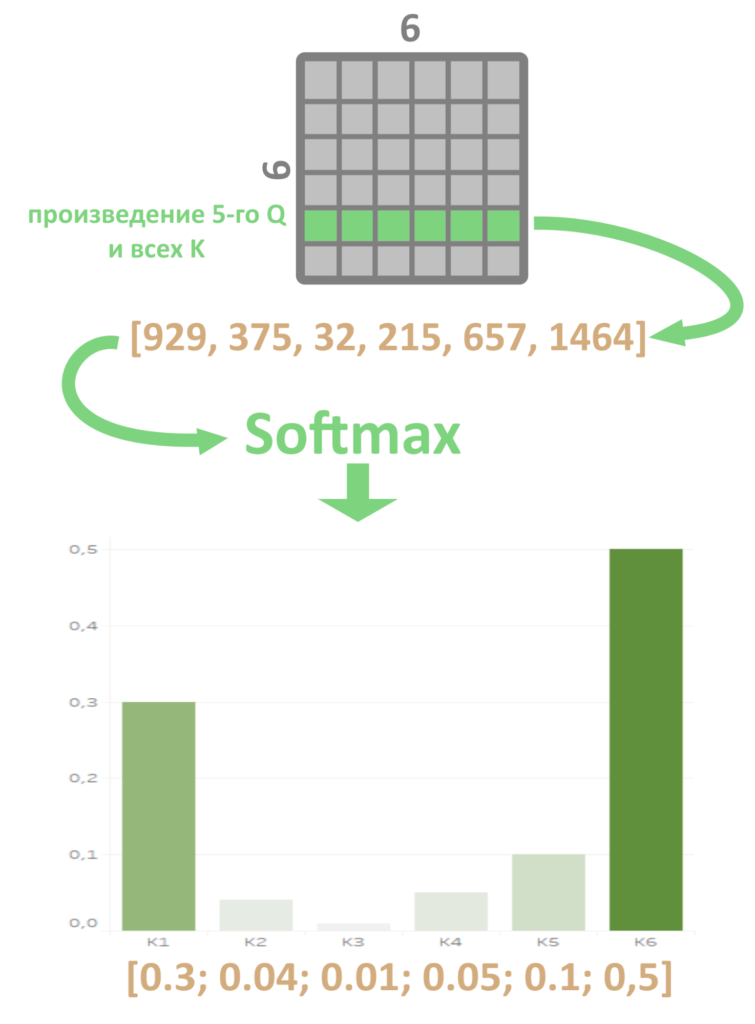
В последовательности было одно большое скалярное произведение и много маленьких. Softmax сделает из такого числового ряда набор неотрицательных чисел, одно из которых (бывшее самое большое) уйдет в отрыв, а все остальные будут плавать возле нуля.
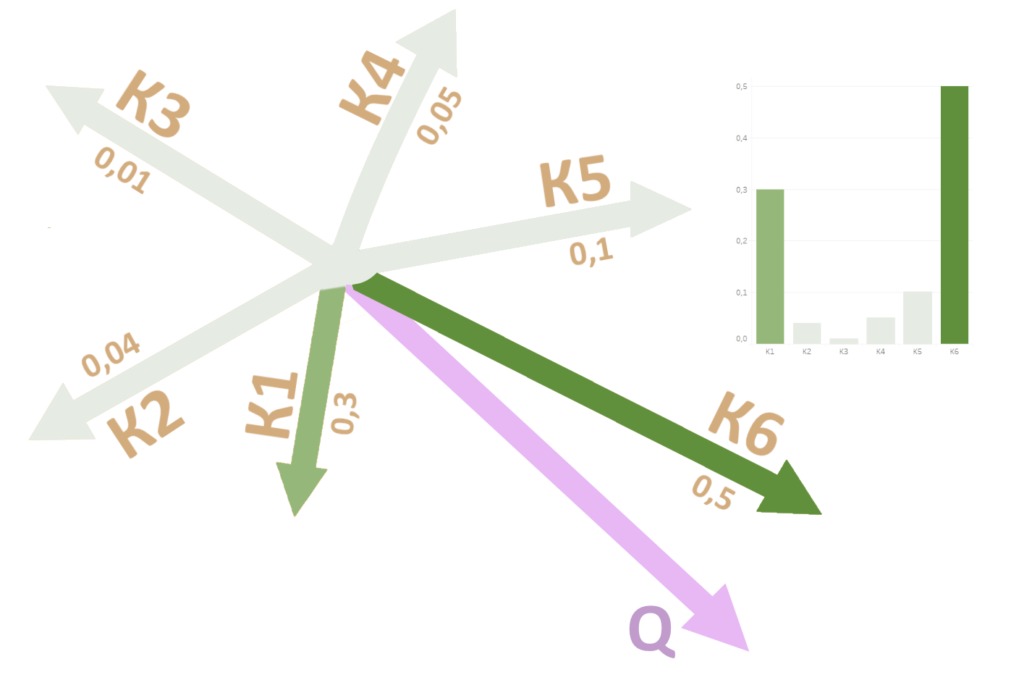
Теперь работу Softmax можно рассматривать как вектор «веса», который выбирает из всех ключей К ближайший к запросу Q. Так компьютер поймет, какие «теги» соответствуют «запросу» В свою очередь выбрать один ключ K — значит выбрать соответствующее ключу значение V. Задача решена, по данному Q нашлось V! Да?
На самом деле не совсем.
Нельзя выбирать единый вектор V из готовых. Их лучше смешать в нужной пропорции, «взвесив» каждое значение V, умножая его на вектор веса из серой матрицы (он получился из произведения Q и К и результата выполнения функции Softmax). Тогда в итоговом векторе внимания Z могут ужиться два или три элемента V, умноженных по степени важности. Вектор внимания Z и есть результат работы скалярного внимания.
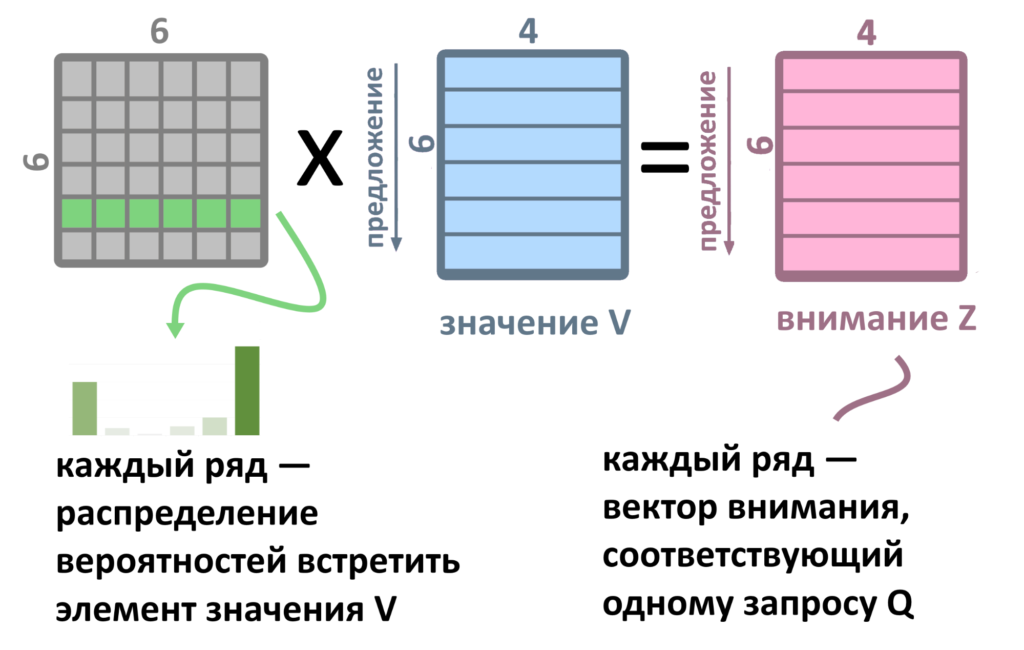
Взвешенное скалярное внимание
Выше мы описали механизм скалярного внимания (dot-product attention). Оно включает в себя перемножение огромной кучи матриц. Чтобы куча матриц перемножалась быстрее, разработчики трансформера добавили операции масштабирования и линейных проекций. Эти уловки позволяют уменьшить размерность матриц.
Чтобы найти ближайшие к запросу ключи, нужно умножить матрицу ключей K на матрицу запросов Q. Этот процесс ускоряется масштабированием (scaling) — делением полученной матрицы (Q*K) на квадратный корень длины одного ключа — d(k).
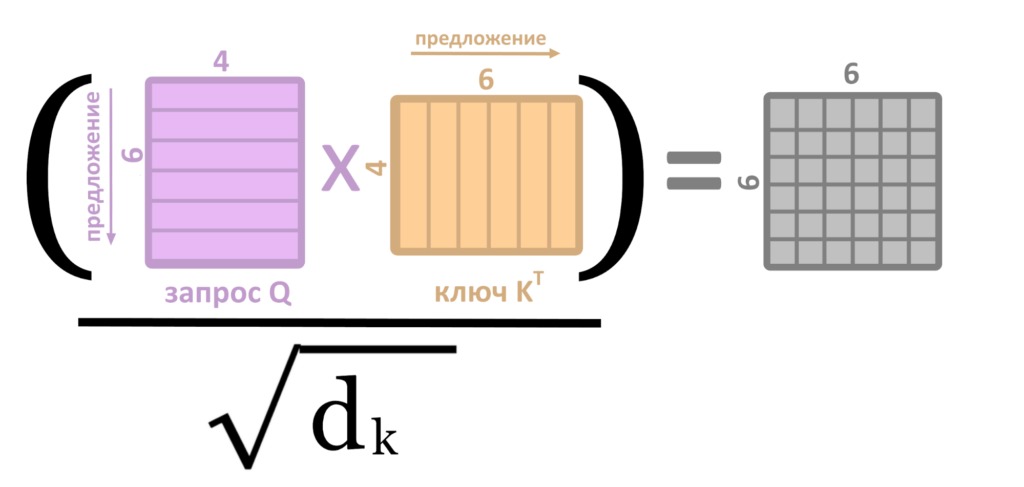
Поэтому полная схема работы взвешенного скалярного внимания, приведенная в оригинальной научной работе, выглядит вот так.
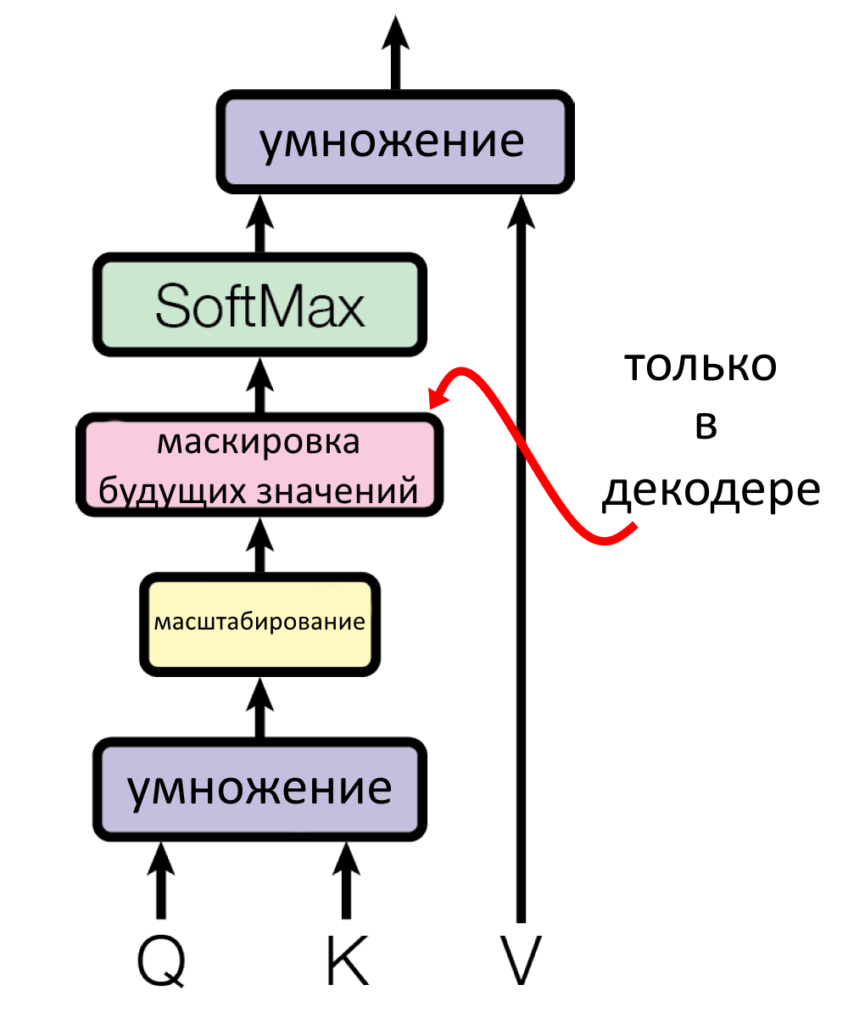
Неразобранным остается только розовый кирпич с маскировкой будущих значений. Он есть только в декодере, который мы пока не рассматривали.
Что такое линейная проекция?
Умножение вектора на матрицу.
Чтобы перенести («спроецировать») начальный вектор слова в пространство ключей, запросов или значений, нужно умножить его на соответствующую матрицу весов (результат умножения матрицы на вектор — вектор). Вектора слов предложения перед умножением объединяются в матрицу (одна строчка — слово), поэтому корректнее будет представить линейную проекцию вот так:
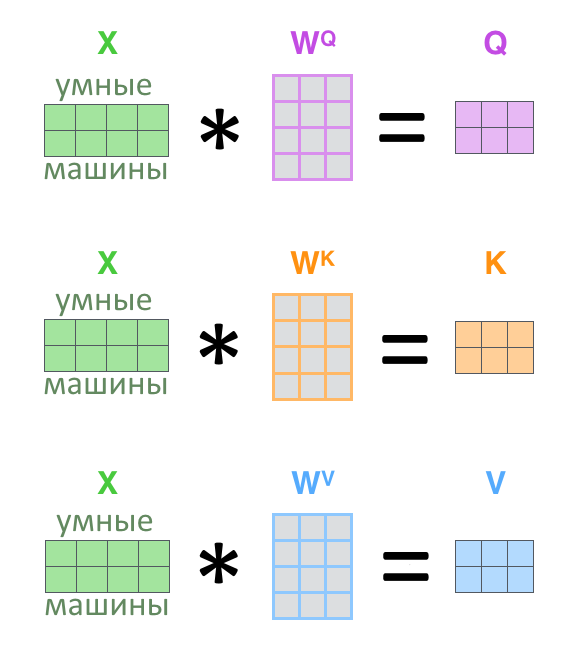
Линейная проекция уменьшает размерность матриц Q, K, V: W(Q), W(K), W(V) нарочно сделаны меньше исходных векторов по размеру.
Три линейных проекции, по одной для Q, K, V, плюс взвешенное скалярное внимание называются «головой внимания» (attention head).
Multi-head attention («многоголовое» внимание)
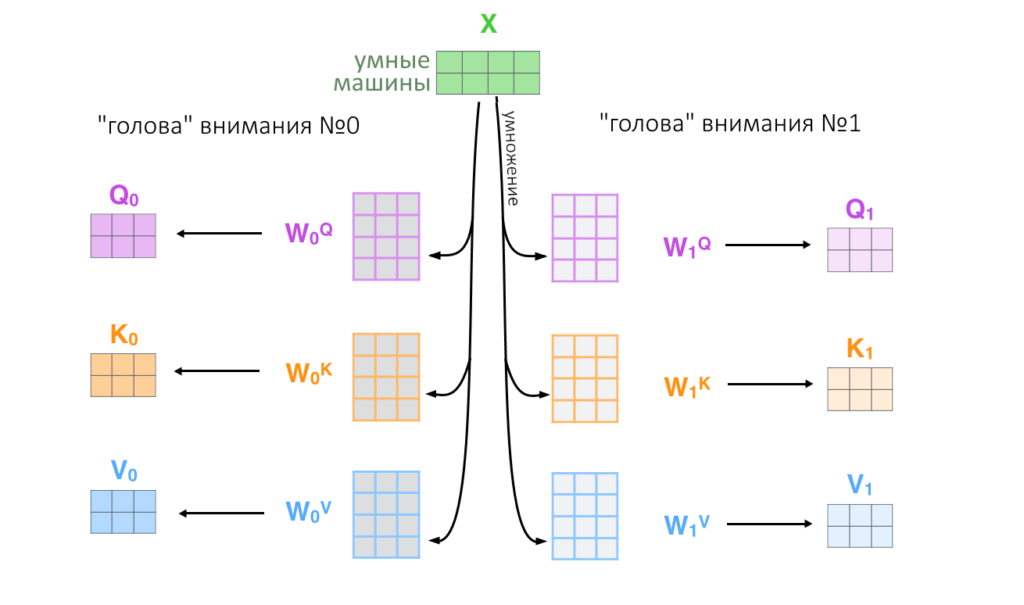
Разработчики решили, что лучше работать не с одной головой внимания, а с восемью: умножить исходные вектора на восемь разных маленьких матриц весов W(Q), W(K), W(V). Восемь получившихся матриц Q, K, V параллельно проходят через механизм скалярного внимания. В конце их результаты конкатенируются и попадают на слой с нелинейной функцией активации.
Зачем нужно делать несколько «голов»? Рандомизируя начальные веса каждой «головы внимания», можно заставить систему как бы «обратить внимание» на разные аспекты слова и получить восемь его разных «запросов», «ключей» и «значений»: это полезно и повышает качество анализа.
Посмотрите, какое место в multi-head attention занимает взвешенное скалярное внимание.
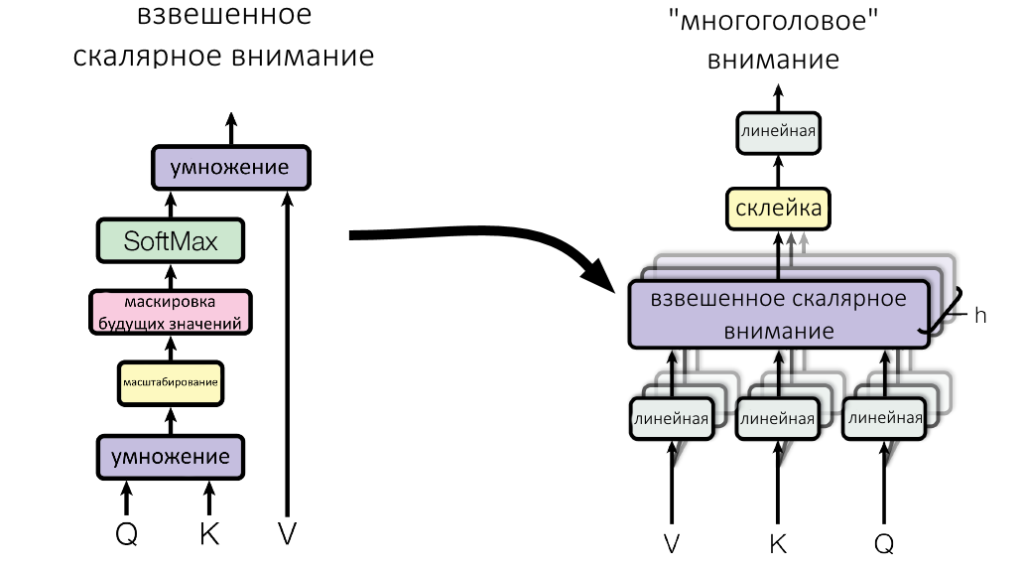
Показанная выше схема окончательно дополняет идею механизма внимания в трансформере.
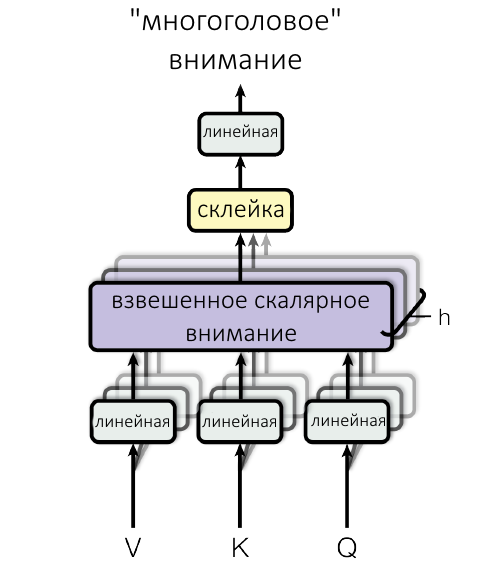
Итак, входные вектора слов, «упакованные» в матрицу, проходят через линейную проекцию h=8 раз (число подобрали эмпирически). Это значит, что исходную матрицу 8 раз умножают на разные маленькие матрицы, получая восемь троек Q, K, V.
Восемь троек Q, K, V параллельно проходят через механизм взвешенного скалярного внимания (scaled dot product attention), который мы ранее разобрали.

Результат работы всех восьми «голов внимания» (где на выходе каждый раз получается матрица) склеивается («конкатенируется») в одну длинную матрицу и она опять умножается на матрицу весов, которая обучалась вместе с моделью.
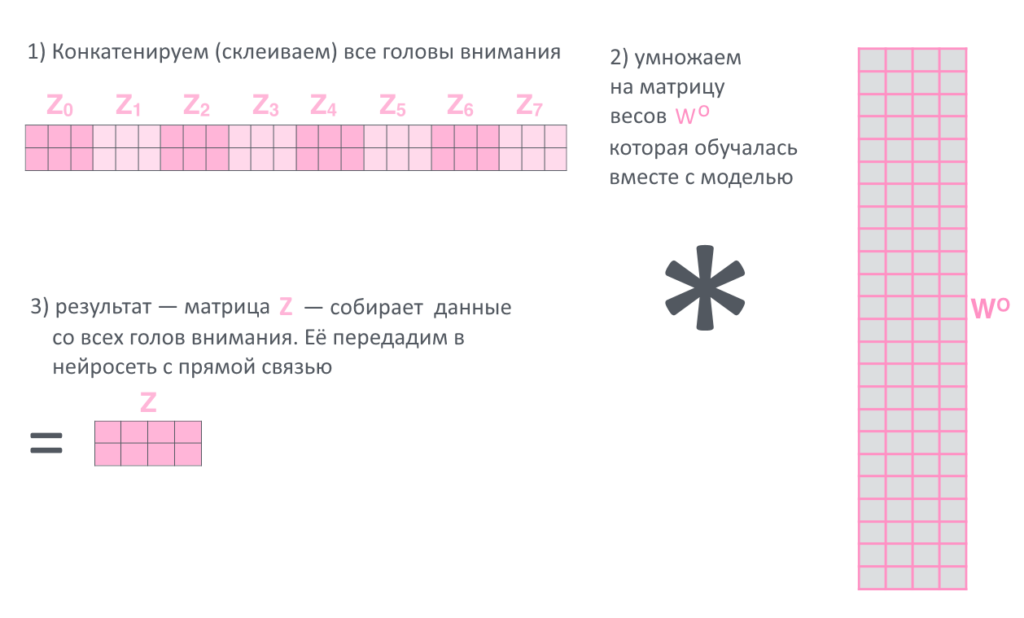
Последняя матрица Z — и есть результат работы большого и сложного слоя «многоголового» внимания энкодера. Этот результат попадет в работу нейросети с прямой связью, а оттуда — на следующий слой энкодера, где снова будет «разбит» на части Q, K и V.
Заключение
Это был механизм внимания кодирующей части трансформера. По сравнению с ней внимание декодера проще разобрать — там почти все то же самое, только некоторые вектора строятся по-другому.
Во второй части этой серии статей мы расскажем о механизме внимания декодера и посмотрим на трансформер с высоты птичьего полета, чтобы понять, как связаны разные его части. Кроме того, расскажем об оставшихся хитрых уловках (там есть еще парочка).
В этом тексте было много технических деталей и умножения матриц. Надеемся, что получилось рассказать о них не слишком сложно — и что принципы работы нейросетей-трансформеров стали вам чуточку понятнее. Оставайтесь с нами!
Источники
- The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time. — источник иллюстраций и основа нашего текста
- Attention Is All You Need — видеолекция на Ютубе с пересказом научной публикации, где изложена идея трансформера
- Transformer: A Novel Neural Network Architecture for Language Understanding
- What exactly are keys, queries, and values in attention mechanisms? — аналогия механизма внимания через запросы на Ютубе
- Illustrated: Self-Attention — анимированные объяснения о том, что такое «внимание на себя»



