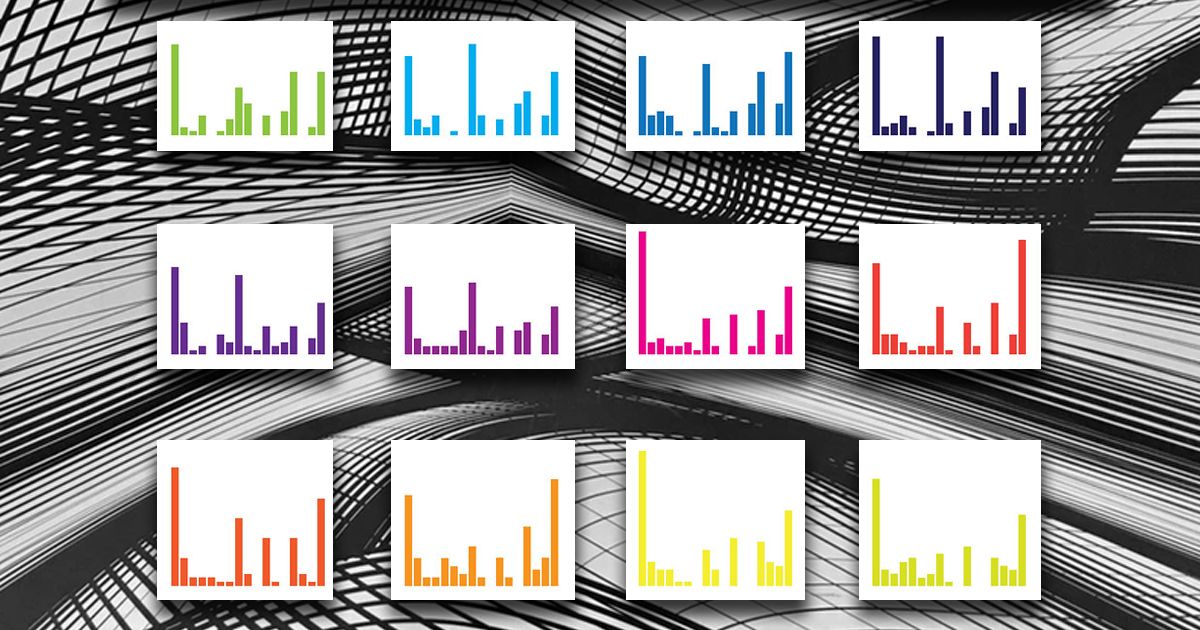
TopicModellingTool — это удобный инструмент с графическим интерфейсом. Он, как любая привычная программа, принимает на вход файлы и складывает результат работы в отдельную папку.
Для тематического моделирования в TopicModellingTool нужна коллекция документов в формате txt. Но на вход программе можно подавать и один документ, тогда каждый абзац будет считаться за отдельный текст.
Итак, перед работой вам нужно где-нибудь скачать полный текст книги в формате txt. Его лучше предобработать. В одном из наших гайдов мы рассказали, как привести все слова в книге к начальной форме программой MyStem. Это можно сделать, если хотите, чтобы разные формы слова не считались за одно и то же.
Также нужно разбить текст книги на главы. Это удобно сделать в Notepad++, сохраняя каждую новую главу в новую вкладку (которая открывается комбинацией клавиш Ctrl+N). Сохраните все документы-главы в одну папку, с ней мы в дальнейшем будем работать.
Теперь смоделируем темы. Для того, чтобы найти темы в TopicModellingTool, подадим программе на вход коллекцию файлов, в каждом из которых содержится одна глава книги.
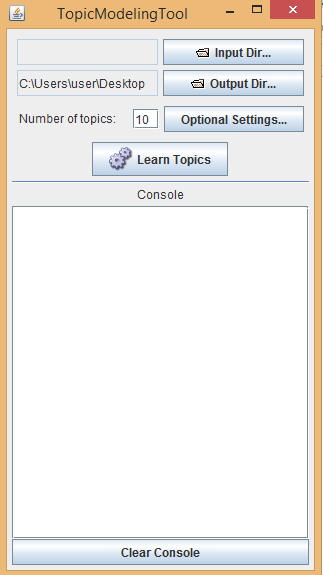
Для этого, нажав по кнопке Input Dir, нужно указать входную директорию для работы программы. Все файлы формата txt, находящиеся в папке, программа примет на вход.
Параметр Number of topics позволяет менять число находимых тем, а на вкладке «Optional settings» можно указать путь к файлу со стоп-словами (Stopword file…) или количество итераций поиска тем (number of iterations). Чем больше итераций, тем более «поляризованными» получаются топики: в этом случае они целиком занимают документы, в которых содержатся. Если ваша цель — найти для каждого документа-главы «ведущую тему» — можно увеличить число итераций поиска (например, до 10 000). Другое возможное решение — снизить число тем так, чтобы оно было маленьким по сравнению с числом документов.
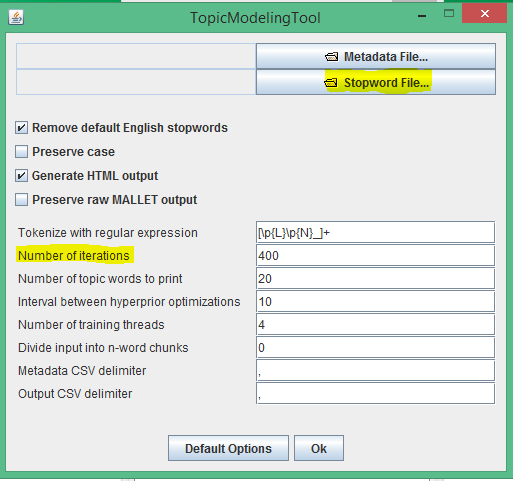
Две последних настройки на вкладке optional settings, поля metadata CSV delimiter и output CSV delimiter, помогут изменить разделитель в CSV-файлах, генерируемых программой на выходе. CSV — формат файла, название которого означает «comma separated values», то есть «значения, разделенные запятой», но вместо запятой можно подставить любой другой символ (программа Tableau по умолчанию предполагает, что разделителем будет пробел, но мы покажем, как изменить эту настройку).
По результатам тематического моделирования TopicModellingTool сформирует две папки — output_csv и output_html. Файл topics_metadata позднее пригодится для визуализации в Tableau. Файл all_topics из папки output_html, по умолчанию открываемый в браузере, покажет сгенерированные списки тем в удобном представлении. На каждый из топиков можно нажимать, чтобы увидеть, в каких документах он превалирует. В свою очередь, нажатие на имя документа покажет, из каких тем он состоит.
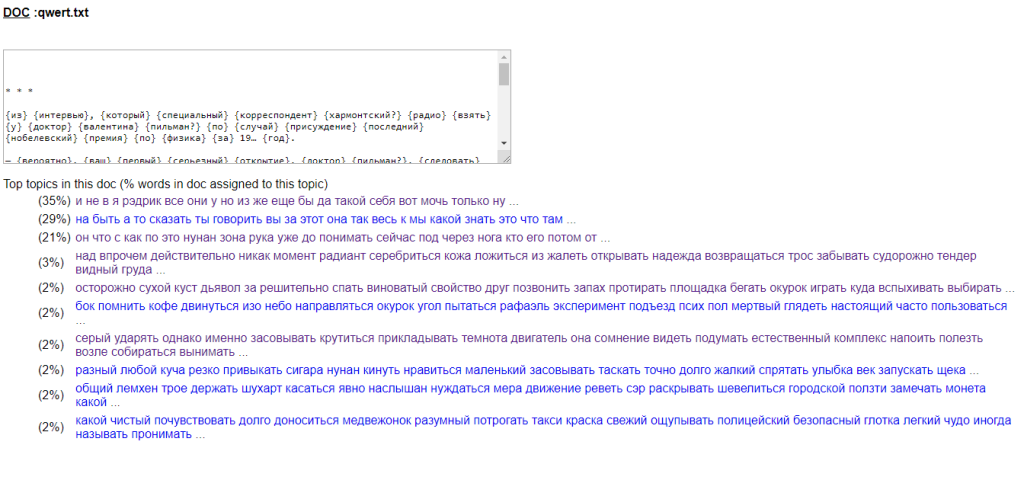
Теперь у нас есть папки с результатами выдачи Topic Modelling Tool.
Можно нарисовать график по полученным данным: например, в Tableau.
Версия Public бесплатна и её можно скачать здесь. Для того, чтобы это сделать, нужно зарегистрироваться на сайте.
Итак, вы скачали и установили Tableau. Что делать дальше? Чтобы построить график, нам нужно основываться на файле выдачи «topics-metadata» из папки output_csv. Загружаем его в Tableau. Для этого выбираем в столбце «To a File» — «Text file». Затем выбираем файл «topics-metadata» во всплывающем окне проводника.
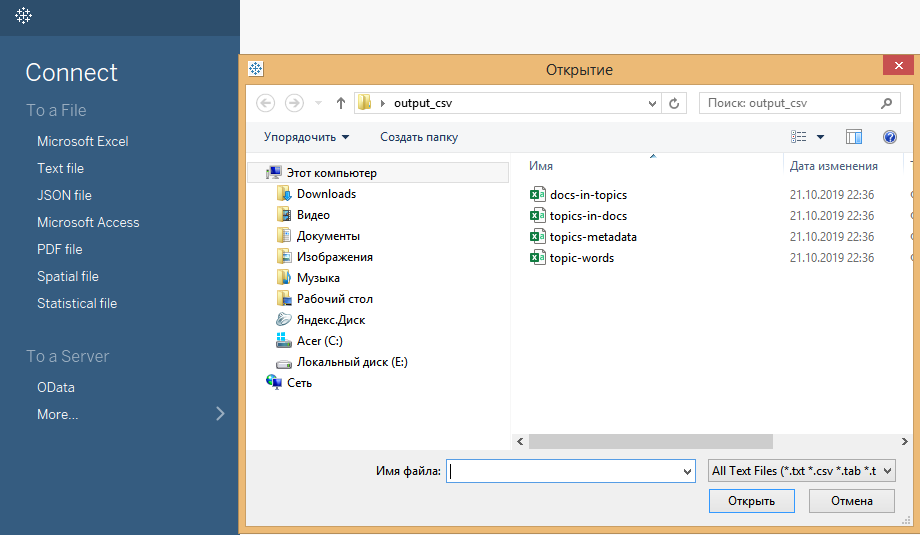
Данные выбраны, можно строить график. Но подождите, это не похоже на нормальную таблицу!
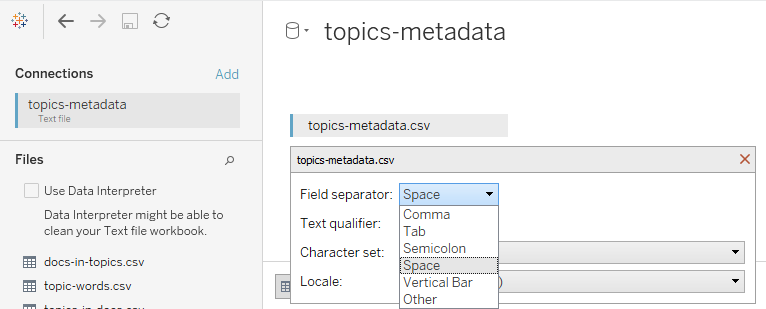
Верно. Нужно настроить то, как Tableau читает и отображает файл. Формат, в котором мы получили данные — csv, в этом формате разделителем колонок является запятая. Во всплывающем меню файла нужно выбрать «Text file properties» и в появившемся окне — «Text qualifier» — «Comma». Остальные параметры по умолчанию — кодировка, например — подходят для нашего файла.
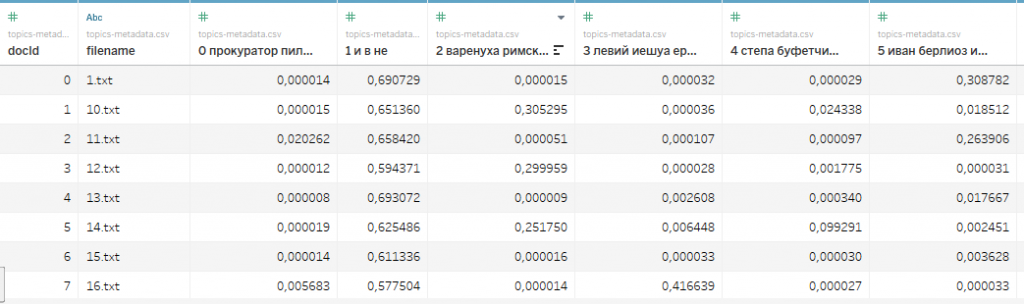
А ещё можно назвать колонки более наглядно, чем просто порядковыми номерами — это позволяет сделать опция «Field names are in first raw». Готово! Теперь таблица выглядит читаемо, и по ней можно построить график.
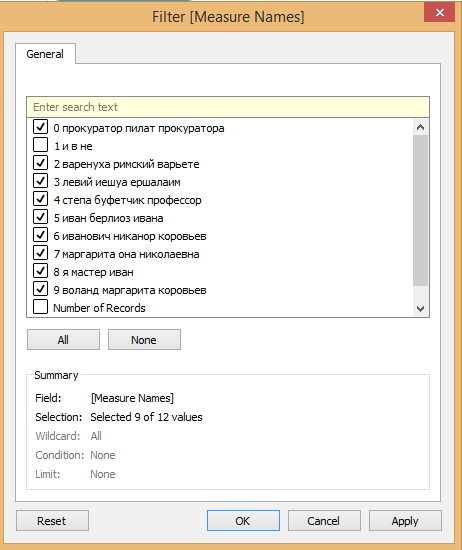
Переходим во вкладку Sheet 1 в левом нижнем углу и приступаем к графику. Нам необходимо, чтобы по одной оси отображались номера документов, а по другой — вероятностей тем. Поэтому берём эти значения из поля данных слева и переносим в «rows» и «columns». Для того, чтобы в столбцах суммарной вероятности разные темы как-то отличались друг от друга, в «Marks» добавляем «Measure names», и слева от него меняем отображение на цвет. Теперь все темы на графике видны, но большую его часть занимают номера частей, пока что прибавляемые в Tableau к значениям, и количество записей (Number of records, DocID). Их нужно отфильтровать, поэтому в фильтры переносим «Measure names», и в меню этого фильтра выбираем все имена, кроме этих двух.
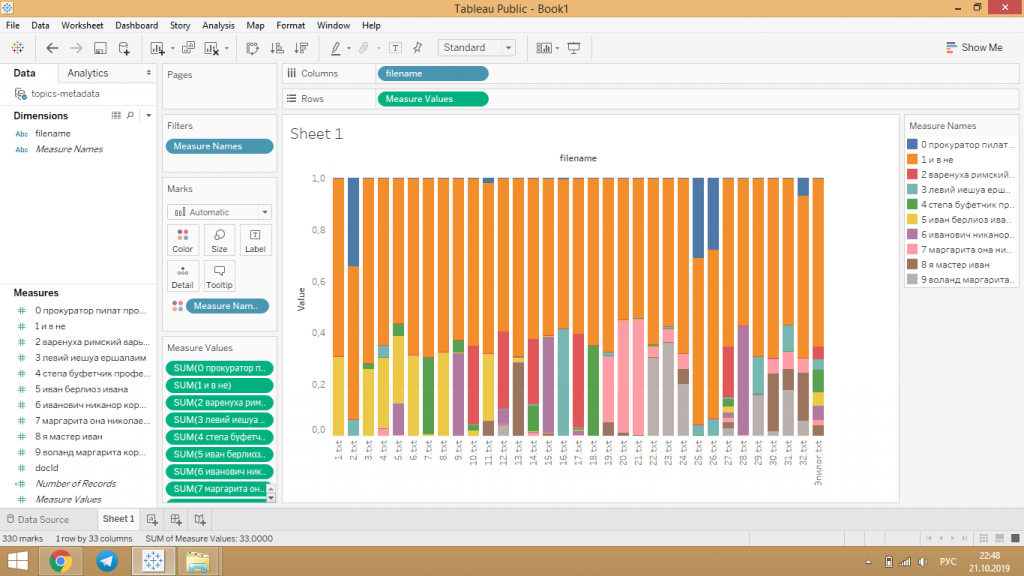
Вот теперь готово — на графике отображаются вероятности тем для каждого документа, документы подписаны, темы на графике отличаются.
К сожалению, в бесплатной версии Tableau нет возможности сохранять файлы на компьютере — только в удалённом репозитории на сайте.
Темы можно отфильтровывать — например, на скриншоте лучше скрыть оранжевую тему под номером 2.
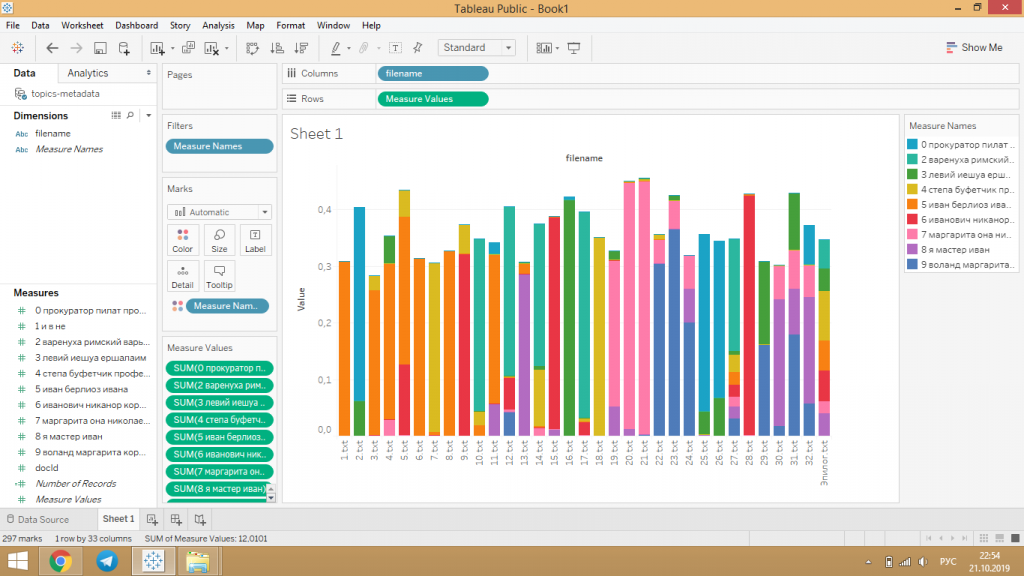
Цвета графика и подписи на нем, как и название, можно изменять:
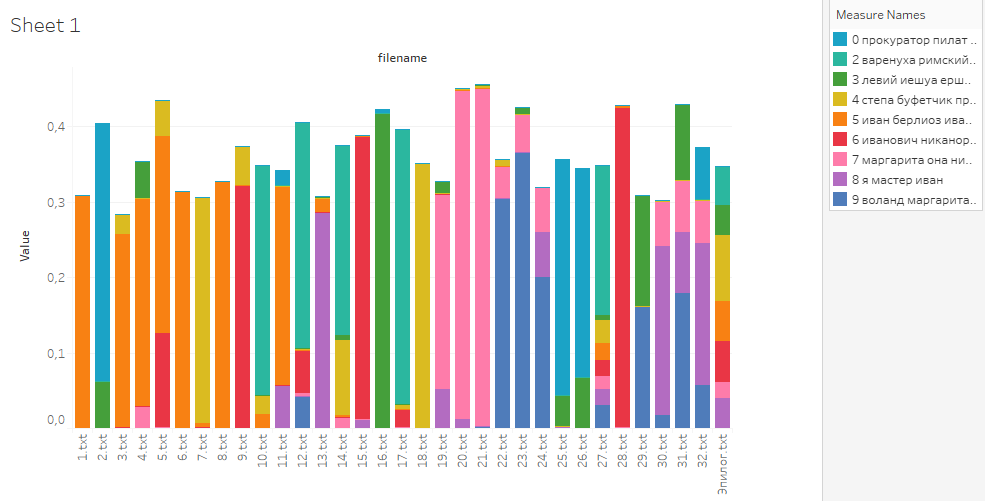
Вот такая визуализация у вас получится, если все делать по инструкции из этого гайда. Теперь вы знаете, как безболезненно, без работы с командной строкой можно исследовать текстовый корпус!

