

Что такое дата-журналистика?
Дата-журналистика — это направление журналистики, в котором для создания статей и материалов используются количественные данные. Например, данные о заболеваемости ВИЧ, частота встречаемости слов в романе или контракты госзакупок. На основе данных журналисты выявляют закономерности и не видимые на первый взгляд проблемы, а результаты публикуют в виде расследований, статей, мультимедийных проектов или визуализаций. В «Системном Блоке» этому посвящена целая рубрика «Инфографика», из которой можно узнать о том, как бездомность сокращает жизнь, как политические события влияют на книжный рынок и сколько в российских школах учителей-мужчин.
Как работает дата-журналист?
Этапы создания дата-журналистского исследования: выбор темы, постановка вопроса и выработка гипотез, поиск и подготовка данных, проверка выдвинутых гипотез, визуализация, подготовка текста.
Выбор темы
При выборе темы журналист отталкивается от интереса читателя либо от запроса издания, в котором будет опубликован материал. Проще всего узнать интересы целевой группы — изучить социологические опросы, обратить внимание на потенциально популярные, виральные или острые темы, провести анализ поисковых запросов.
Бывают случаи, когда текст рождается из данных, то есть мы видим аномальное значение или большой рост показателя и пишем об этом. Например, в 2024 году число призывников, проходящих альтернативную гражданскую службу, рекордно выросло. В подобных случаях мы пишем об аномалии и ищем экспертов, которые могут объяснить это. Но сами данные нам не раскроют причину, только покажут явление.
Борис Ги, дата-журналист
Постановка гипотез
Когда тема сформулирована, можно выдвинуть несколько гипотез, которые вы будете проверять впоследствии.
Гипотеза — это предположение, которое формулируется перед началом исследования и которое подтверждается или опровергается эмпирически по ходу работы. Гипотеза описывается формально, она включает в себя возможный ответ на вопрос, раскрывающий тему исследования. Часто требуется перепроверять и корректировать идеи, поэтому не нужно бояться выдвигать новые гипотезы.
Например, в исследовании «Системного Блока» про призыв в Великую Отечественную войну была сформулирована гипотеза о том, что доля населения, призванная в армию из разных республик, была примерно одинаковой. Но в процессе анализа эта гипотеза не подтвердилась. В то же время у исследователей были вопросы, на которые они хотели получить ответ (например, как повлияли на призыв сталинские ограничения на призыв некоторых народов на фронт). Иногда не гипотезы, а именно исследовательские вопросы задают направление работы: например, как повлияли на статистику негласные запреты на призыв в отношении некоторых народов СССР.
Еще направление работы могут подсказать сами данные. Но что делать, когда данные только предстоит найти в соответствии с выбранной темой и гипотезами?
Сбор данных
Получить данные можно разными способами. Например:
- Скачать из открытых источников
Готовые датасеты — это общедоступная информация, размещенная в Интернете под свободной лицензией для бесплатного и неоднократного использования. Они чаще всего публикуются в форматах XLSX, CSV, JSON, что упрощает их автоматизированную обработку. Таких датасетов много, их источниками являются государственные органы (открытые данные Минкультуры РФ, данные о государственных муниципальных учреждениях, открытые данные Росстата, государственная статистика ЕМИСС), негосударственные организации (платформа открытых данных «Если быть точным», проект Инфокультуры «Госзатраты», карта ДТП), международные проекты (Google Data Search, данные ВОЗ, Kaggle Datasets, World Inequality Database). Их недостаток в том, что, вероятно, они уже были неоднократно исследованы, поэтому стоит удостовериться, что вы собираетесь показать на них что-то новое. - Собрать автоматически с нужных сайтов
Можно воспользоваться специальным программным обеспечением для парсинга, либо написать парсер самому. О том, как это сделать, можно подробно почитать в нашем материале. - Попросить у операторов данных
Некоторые компании предоставляют агрегированные данные по запросу. К самой базе данных доступ никто не даст, в чем и заключается сложность: по полученному запросу PR-отдел компании должен сформулировать задачу для аналитика, а он ее решить. На это может не быть ресурсов. - Легально получить доступ к неопубликованным данным
Можно направить официальный запрос в инстанцию, хранящую желаемые данные. Государственные ведомства и Росстат публикуют далеко не все показатели, которые собирают. Например, один из немногих показателей, который характеризует заболеваемость ожирением — это темпы прироста первичной заболеваемости ожирением на ЕМИСС. Из опубликованных данных непонятно, сколько людей имеют этот диагноз. Но мы можем запросить данные формы наблюдения № 12 у Росстата и получить информацию в разрезах по регионам и возрастным группам. - Собрать самостоятельно.
Это можно сделать с помощью изучения документов или опроса. Однако репрезентативный соцопрос — это сложная задача, для которой нужна группа исследователей. Такие материалы обычно возможны только в партнерстве. В качестве примера можно привести совместное исследование «Если быть точным» и «Таких дел» о том, что знает и думает про ВИЧ российская молодежь.
Главное при выборе источников данных — убедиться, что они отражают предмет исследования. Если вы пользуетесь готовыми датасетами, важно понимать, кем и как они получены, и что именно описывают данные. Вопросы о том, кто собрал данные, когда, где, при каких обстоятельствах и с какой целью, позволяют полноценно понять их специфику, дают возможность избежать неверных трактовок. Журналист должен найти верную методологию расчета или форму статистического наблюдения.
В качестве примера можно рассмотреть такой показатель, как статистика абортов. На ЕМИСС есть показатель «Число прерываний беременности» (их два, первый собирает Росстат, второй — Минздрав). Нужно взять первый, поскольку Росстат включает и негосударственные клиники. На первый взгляд, эти данные можно интерпретировать как число «искусственных» абортов, то есть случаев, когда женщина приходит в больницу и прерывает беременность. Для проверки нужно открыть форму 1-здрав (можно найти по ссылке в паспорте показателя). Раздел формы называется немного иначе — «Сведения о беременности с абортивным исходом», а в общее число входят как медицинские, так и самопроизвольные аборты (т.е. выкидыши).
Иногда необходимо возобновлять отбор данных, так как ход работы показывает, что на основе имеющихся невозможно сделать выводы, что они нерепрезентативны. У данных могут быть ограничения, незаметные на первый взгляд. О них можно узнать от экспертов, профильных специалистов или из литературы, но не из самой формы. Например, официальные данные по ожирению занижены, поскольку ожирение часто идет сопутствующим, а не основным, заболеванием и не попадает в статистическую карточку, которую заполняют в больнице.
Предобработка данных
После того, как данные найдены, переходим к их подготовке для дальнейшего изучения. Очистка данных, или препроцессинг, — один из обязательных этапов, поскольку готовых машиночитаемых данных практически не бывает.
Некоторые открытые данные приходится конвертировать в нужный формат, так как расширение, в котором они опубликованы (например, .pdf), не позволяет считывать хранящуюся в них информацию корректно. Конвертируют данные в машиночитаемый формат (например, XLSX, CSV и т. д.) с помощью библиотек python или другого языка, онлайн инструментов и т. п., а в самых простых случаях с помощью копирования и вставки.
После конвертации данные проверяются на ошибки и чистятся вручную. Это можно сделать с помощью, например, табличных операторов: подсчитать суммы по регионам и сравнить их с данными, которые есть (строчка «Россия» должна совпадать с суммой по регионам); унифицировать названия показателей, регионов; проверить опечатки (вместо запятой может быть точка или запятая может быть в неправильном месте) и т. д.
Обработка большого объема информации (проверка на наличие ошибок, удаление или замена пропусков и дублей) занимает немало времени, но это обязательно условие для того, чтобы получить «чистый» датасет. Важно, чтобы полученная таблица была единой (а не несколько разных таблиц на одном листе, как часто бывает в Excel).
Вот чек-лист самых важных шагов предобработки:
- Загрузка и проверка структуры данных. Убедитесь, что файл открывается, столбцы читаются корректно, а данные соответствуют ожидаемой структуре.
- Обработка пропусков. Найдите пустые значения и заполните их (например, средним, медианой, «N/A») или удалите строки, если это оправдано.
- Приведение данных к единому формату. Убедитесь, что даты, числа и текстовые значения приведены к одному стилю (например, YYYY-MM-DD, десятичные числа через точку, текст в нижнем регистре).
- Унификация категорий. Приведите значения к единому виду (например, «Москва» и «москва»).
- Удаление ненужных данных. Уберите лишние столбцы и строки с некорректными значениями.
- Сохранение результата. Сохраните очищенный файл в удобном для анализа формате (например, CSV).
В исследовании «Системного Блока» о призыве в Великую Отечественную войну работа с данными началась с предварительного анализа. У исследователей были оцифрованные архивные карточки о военных потерях, госпиталях, военно-пересыльных пунктах и многом другом. Один из авторов исследования, Илья Воронцов, объяснил, что после просмотра данных они решили остановиться на военно-пересыльных пунктах, так как эти данные были наиболее понятны по сравнению с другими.
Считать число Михаилов на фронте можно, но бессмысленно. Считать деревни, в которых проживали призывники тоже было нецелесообразно: много опечаток, одинаковых названий для разных мест и, главное, пропусков. В итоге мы взяли даты и места призыва на фронт.
Илья Воронцов, один из авторов исследования о призыве, сотрудник ИОГен РАН
После подготовки данных у авторов получились таблицы такого формата:
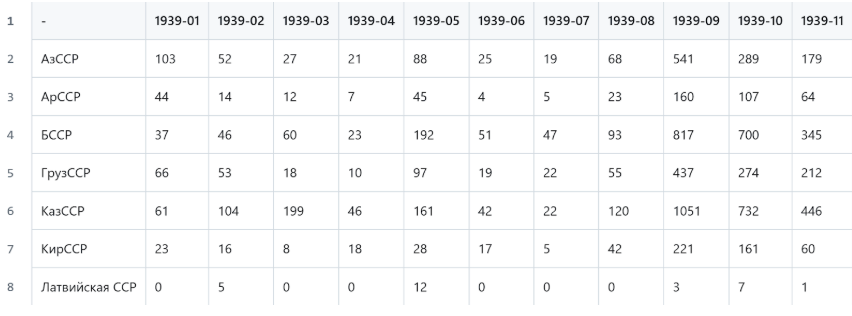
Это пример машиночитаемой таблицы без объединенных ячеек, декоративных элементов или пропусков. По строкам в ней расположены объекты, а по столбцам — их характеристики.
Анализ данных
После подготовительной части исследования дата-журналист приступает к поиску ответов на исследовательские вопросы и проверке выдвинутых гипотез. Поставленные гипотезы надо перевести на формальный язык: что и как надо измерять, чтобы проверить гипотезу, что будет считаться её подтверждением или опровержением. Это обязательно нужно сделать до начала расчетов, иначе есть риск влияния полученного результата на выводы. В процессе работы полезно изучить разные срезы данных. Например, можно подсчитать среднее значение, медиану или моду, а также проанализировать выбросы. Стоит посмотреть и на конкретные примеры данных. Это может привести к уточнению гипотез и появлению новых.
Например, при работе «Системного Блока» над исследованием о призыве выяснилось, что в данных место призыва порой указывалось с административно-территориальным делением. Чтобы посмотреть, откуда и в какое время призывались люди, был сделан простой фильтр на регулярных выражениях. Таким образом удалось вычленить месяцы призыва и места — республики, области, края и прочие крупные регионы.
Как выглядел код
def normalize_place(place)
place
.sub(/\b(([УГРОКП]?|Обл|Респ|УО)ВК) /i, '\1, ')
.sub(/\b(ССР|АССР|АО|НО) /, '\1, ')
.sub(/\b(область|обл\.?|край|уезд|губ\.?|воеводство|воев\.?|волость|вол\.?) /, '\1, ')
end
def tokenize(place)
place.split(',').map(&:strip).reject(&:empty?).uniq.sort
end
def is_republic(str)
str.match(/\b(ССР|АССР|АО|НО|Германия|Австрия|Польша|Болгария)\b/i)
end
def is_subrepublic(str)
false # fake function
end
def is_oblast(str)
str.match(/\b(область|обл\.?|край|уезд|губ\.?|воеводство|воев\.?|волость|вол\.?|Восточная Пруссия)\b/i)
end
В ходе работы исследователи искали таблицы переписи, по которым можно было бы нормировать уровень призыва на размер региона. Так как регионов получилось слишком много, они были укрупнены до уровня союзных республик. Для этого число призванных делили на население республики, а потом умножали на тысячу, чтобы получить число призванных (но только учтенных в БД) на 1000 человек.
Также была предпринята попытка заполнить как можно больше пропусков в данных. Например, плохо заполненные карточки, в которых не был указан месяц призыва, а только год, распределяли между разными месяцами года в тех же пропорциях, что и хорошо заполненные карточки того же региона.
Чтобы проанализировать динамику процесса призыва, исследователи разбили данные по возрастам призывников, а также посмотрели, почему в каких-то регионах резко росло или падало число призывов в определенные годы. Это позволило обнаружить несколько факторов, влияющих на призыв: крупные территориальные изменения, приказы о призыве, ограничения на службу для лиц некоторых национальностей, трудовая мобилизация и прочее.
Многие сюжеты, которые развивались во время исследования, не попали в итоговый материал, потому что их не удавалось «докрутить» и статистически подтвердить. Например, это случаи, когда призывники родились в одной республике, но были призваны в другой, а также вопросы, касающиеся военно-учетных специальностей, рангов призывников, разницы в призыве на военную службу мужчин и женщин. Такой подход показывает, что зачастую приходится развивать несколько идей, чтобы получить хотя бы один достойный публикации результат.
Подготовка материала
Создание законченной журналистской истории является целью всех предшествующих этапов. Материал должен собрать всю фактуру, данные, визуализацию, полученные выводы. По формату это может быть:
- большой текст, где в центре находятся данные и пояснение того, о чем они;
- истории конкретных людей, которые параллельно дополняются данными;
- заметка или новость, раскрывающая через данные текущую повестку.
Итогом исследования может стать сложная интерактивная визуализация (например, граф) или карта, в таком случае текст помогает объяснить найденные связи и закономерности. Порой текст почти не нужен, к примеру, когда не требуется дополнительно пояснять результаты, так как они сполна раскрыты при помощи графиков и их интерфейса.
Визуализация данных
Получив результат анализа данных, можно переходить к визуализации. Инструментами визуализации могут быть графики, карты или схемы. Они помогают читателю увидеть, к чему вы пришли, и убедить его в достоверности ваших выводов. В этом материале «Системного Блока» подробно рассказывается о разных видах визуализации.
В процессе анализа данных строится много черновых визуализаций. Они могут быть некрасивыми и перегруженными. Главное, что они позволяют лучше понять, что есть в данных и чего в них нет.
Вот примеры черновых визуализаций, которые создавались во время работы над нашим исследованием школьного литературного канона.
Какими инструментами пользуется дата-журналист?
Во время работы над материалом дата-журналисты используют инструменты для сбора, очистки, анализа и визуализации данных. В большинстве своем они бесплатные, или бесплатной версии программы достаточно для работы даже небольшой команды. Также нередко дата-журналисты учатся программировать, так как с помощью кода некоторые задачи решаются быстрее.
Скрейпинг
Иногда данные нельзя скачать в виде готовых файлов. При этом видно, что данные есть, например, каталог онлайн-магазина или решения суда из ГАС «Правосудие». Такие данные можно спарсить, написав код на Python. Некоторые сайты предоставляют API для более легкого доступа к данным и чтобы сайт не перегружали запросами.
Плагины для скрейпинга
Данные с простых сайтов можно собирать с помощью плагинов для браузера. Тогда вам не потребуется программирование. Например, можно использовать WebScraper. Существуют также плагины для захвата таблиц с сайта, например, Table Capture, которые часто используют в простых случаях.
Нейросети
Если вы не умеете программировать, можно использовать любую доступную вам нейросеть, чтобы написать код для скрейпинга.
Excel / Google Sheets
Подходит для первичного анализа данных, можно убрать дубликаты, посмотреть число пропусков, а с помощью сводных таблиц сгруппировать данные по нужным категориям. Также можно построить первые графики. Минусы: не откроет большие файлы.
OpenRefine
Подойдет, когда есть много однотипных строк, например, адресов (Санкт-Петербург, Санкт Петербург, Петербург, Ст. Петербург и т. п.), которые нужно привести к одному виду.
AntConc или Voyant Tools
Программы для текстового анализа, которые позволяют не только исследовать тексты количественно, но и визуализировать результаты. Инструкции по их использованию можно прочитать здесь, здесь и здесь.
Gephi
Пригодится, если вы работаете с сетевыми данными, например, пользователями социальной сети. Можно визуализировать граф, выделить главные узлы — участников сети. О том, как это сделать, можно прочитать в нашем материале.
VSCode / Jupyter Notebook / Google Colab
едактор кода. Даже если вы сами не пишите код, вполне возможно, что вам пришлют его коллеги и скажут «просто запустить». В редакторе кода это будет сделать проще. Jupyter Notebook позволяет запускать код пошагово и сразу видеть результаты. Google Colab его онлайн аналог, преимущество последнего — вы можете задействовать мощности виртуальной машины, если вам не хватает своей.
Python / R
Python — универсальный язык, с помощью которого можно собирать данные, чистить, анализировать и визуализировать. R чаще используют исследователи.
ChatGPT или аналоги
ChatGPT пишет код, в том числе и для скрейпинга сайтов, очистки и анализа данных, визуализации и вообще для всего, что попросишь и что реализуемо на языках программирования. Подсказки модели часто эффективнее, чем поиск по Stackoverflow. Натренированная модель сможет отредактировать ваш текст, исправить опечатки и ошибки, убрать лишнее. С поиском данных модели пока справляются не очень хорошо.
Tableau
Можно использовать его или аналогичные системы для анализа, рабочих визуализаций, даже очистки данных и расчетов.
Datawrapper
Онлайн-инструмент для создания графиков и карт. Есть шаблоны для всех основных типов графиков, много можно кастомизировать с помощью подписей и верстки в них. Можно выгрузить график как SVG и довести его до идеала в редакторе. Готовые графики можно легко встроить на сайт.
Flourish
Еще один онлайн-инструмент. Как и в DW, есть шаблоны, здесь их даже больше. В отличие от Datawrapper, дает больше возможностей для интерактивных форматов. Визуализации в Flourish можно объединить в одну историю и встроить на сайт единым слайдшоу. Минусы: не работает без VPN в России.
RAWgraphs
Конструктор визуализаций, подходит для создания черновых заготовок графиков.
Figma
Графический редактор, в котором ваши визуализации можно довести до финального вида, если вам не хватает функциональности готовых инструментов. Также можно использовать другие редакторы: Abobe Photoshop, Adobe Illustrator, Krita, InkSpace и пр.
QGIS
Для работы с картами, на случай, если не получается сделать карту в Datawrapper.
NodeBox
Нодовый редактор, позволяет делать сложные визуализации и анимировать их.
Tilda
Конструктор сайтов, на котором вы можете создать страницу своего материала и с помощью блоков собрать на ней текст и графики.
GitHub Pages
Если вы уже положили ваш код в гит-репозиторий, то там же можно сверстать ваш материал.
WordPress и другие CMS
Если вы планируете полноценную работу редакции и постоянный выпуск материалов, можно посмотреть в сторону различных CMS. Самой популярной остается WordPress, к ней можно найти множество шаблонов и плагинов, которые решают основные задачи при создании сайта (настройка аналитики, оптимизация контента и пр).
Какие примеры дата-журналистских материалов стоит посмотреть, чтобы вдохновиться?
«Как российские регионы борются с ВИЧ и где ситуация хуже всего: рейтинг “Если быть точным”». Авторы исследуют борьбу с ВИЧ в России и составляют рейтинг наиболее и наименее благополучных регионов.
«От Слоновой до Мухинской: животные в названиях российских улиц». Исследование на материале данных Яндекс.Карт об особенностях упоминаний животных в названиях российских улиц.
«В погоне за “Оскаром”». Проект РИА Новостей о фильмах, которые созданы с целью получить «Оскар» за самые престижные номинации фестиваля.
«Как месяц рождения влияет на успехи в спорте». Материал Т—Ж об эффекте относительного возраста — феномене, при котором дети, рождённые в начале года, могут иметь преимущество в спорте по сравнению с одногодками, рождёнными позже позже.
У «Системного Блока» тоже есть примеры дата-исследований.
«Классное чтение: школьная программа по литературе от Октябрьской революции до ЕГЭ». Исследование состава программ по литературе с 1919 по 2022 годы.
«Миссия России, деградация Европы: какие патриотические фильмы заказывает Минкульт РФ». Материал рассказывает, о чем снимают патриотические фильмы, какое финансирование от Минкульта они получают и как окупаются в прокате.
«Восток, пираты и митрополит: что происходит на книжном рынке». Анализ состояния книжного рынка в 2023 году: самые продаваемые книги и самые издаваемые авторы.
«Замкнутый круг: в каких городах России не строят метро, но обещают». Исследование перспектив и темпов строительства метро в российских городах.
«9988 слов о последнем десятилетии». Текстовый анализ того, как новый учебник истории для 11 класса рассказывает о современных событиях.
Что почитать о дата-журналистике?





Где учиться дата-журналистике?
Представляем подборку образовательных программ в российских вузах, где можно обучаться дата-журналистике.
Программы бакалавриата
- Бакалаврская программа «Журналистика» в НИУ ВШЭ
- Бакалаврские программы «Журналистика» и «Медиакоммуникации» в МГУ, внутри которых доступен индустриальный модуль «Интернет-журналистика» (вариативная часть)
- Бакалаврская программа «Журналистика и новые медиа» в ТГУ
- Бакалаврская программа «Журналистика» с профилем «Журналистика новых медиа» в РЭУ им. Г. В. Плеханова
- Бакалаврская программа «Мультимедийная журналистика и современные медиатехнологии» в РГГУ
- Бакалаврская программа «Мультимедийная журналистика» в РУДН
Магистерские программы
- Магистерская программа «Современная журналистика» в НИУ ВШЭ с треком «Журналистика данных»
- Магистерская программа «Цифровая журналистика» в МГУ.
- Магистерская программа «Научная коммуникация» в ИТМО с курсом «Научного сторителлинга» от Александра Богачева
- Магистерская программа «Журналистика больших данных» в РУДН
- Магистерская программа «Журналистика и медиатехнологии» в РАНХиГС
Курсы
- Видеокурс по дата-журналистике на Stepik
- Интерактивный курс Data Communication Concepts на DataCamp
- Курс «Введение в журналистику данных» Андрея Дорожного
- Курс «Визуализация для журналистики данных» на Coursera
Программы зарубежной магистратуры
- Data and Multimedia Journalism on the MA Online Journalism, Birmingham City University, United Kingdom
- Computational and Data Journalism (MSc), Cardiff University, United Kingdom
- Master’s programme in Investigative Journalism, University of Gothenburg, Sweden
- Investigative Journalism, Data and Visualization, University Rey Juan Carlos of Madrid, Spain
- Data and Media Communication Concentration (DMC), Hong Kong Baptist University, China
- Data Journalism Concentration, DePaul University, USA
- Strategic Communication and Data Journalism, University of Missouri, USA
На кого подписаться?
- @sysblok — Системный Блокъ
Анализ и визуализация данных в культурных и общественных сюжетах. О чём писали в дневниках 1917 года? На какие «запрещенные» произведения вырос спрос последние годы? Сколько камер приходится на квадратный километр в Москве? Как выросло потребление алкоголя за последние 5 лет? «Системный Блокъ» станет вашим Вергилием в 9 кругах Big Data. - @datajourschool — Мастерская дата-журналистики «Системного Блока»
Рассказываем о летней школе дата-журналистики от цифрового издания «Системный Блокъ». - @rationalnumbers — Рациональные числа
Световое загрязнение и неравенство в мире, самые популярные топонимы и статистика по ДТП в России, обнуления политических лидеров, частота использования букв алфавита в русском языке — в канале можно найти исследования и примеры интересных визуализаций данных. Материалы сгруппированы тематически, охватывают все сферы жизни на Земле и даже выходят на орбиту. - @designing_numbers — Designing Numbers
Канал ведет Надя Андрианова — победительница Всероссийской премии по визуализации данных и дата-арту Moscow Datavis Awards и призерка международных премий Malofiej и Information is Beautiful Awards. В своем канале она не только любуется оригинальными решениями, но и рассказывает о том, как устроен дата-арт. Тут много референсов для тех, кто работает с данными, и вдохновения — для тех, кто создает цифровое искусство. - @nastengraph — Настенька и графики
Настя настолько любит инфографику, что замечает барчарты даже в рядом стоящих скалах. Здесь вы найдете советы по BI-разработке, дашборды, интересные графики и лайфхаки визуализации данных. Профессионалы могут следить за новостями из мира датавиза, новички — вдохновляться и осваивать современные инструменты. - @chartomojka — Чартомойка
Как и следует из названия, здесь происходит что-то вроде «бизнес-линча» над визуализациям Автор разбирает конкретные кейсы визуализации данных, анализирует ошибки и сильные стороны, даёт конкретные советы не только по матчасти, но и организации рабочего времени аналитика. Если вы только начали свой путь в датавизе и дата-сторителлинге, можно использовать канал как учебное пособие. Канал ведет автор книги «Графики, которые убеждают всех». - @data_csv — data.csv
Канал о журналистике данных и дата-сторителлинге, который ведет аналитик в службе дата-журналистики Яндекса Алексей Смагин. Здесь можно найти интересные и впечатляющие дата-журналистские работы, красивую визуализацию данных и критические разборы действительно ужасных графиков. Выбор тем, как и предполагает жанр канала, авторский, а вкусу автора блога можно доверять. - @data_publication — Дата-сторителлинг
Эксперт по анализу и визуализации данных Андрей Дорожный рассказывает в канале о том, как работает дата-сторителлинг даже там, где вообще нет графиков. Увлекательно разбирает удачные нарративы, показывает, как устроена манипуляция данными (например, как англичане занижали рост Наполеона в газетах), рассказывает об инструментах работы с данными, которые можно применять без программирования. - @tochno_st — Если быть точным
Команда собирает данные о социальных проблемах в России и делится своими исследованиями и датасетами. Миграционный кризис, статистика абортов, данные об онкологии, исследования преступности и экологических проблем — «Если быть точным» показывает, как много об общественных процессах могут рассказать данные, и даёт пример их профессиональной обработки и визуализации. - @awfulcharts — Отвратительные графики
Индекс Деда Мороза, продажи автобусов по регионам, обращение детей с деньгами — трудно понять, что объединяет эти визуализации данных, но одного взгляда на них достаточно, чтобы убедиться: все они отвратительные. Этот канал — сборник вредных советов для тех, кто начинает работать с визуализацией.
Над проектом работали
Авторы: Полина Налобина, Дарья Половникова
Редактор: Системный Блокъ
Иллюстрации: Евгения Родикова, София Лекомцева
Эксперты: Борис Ги, Илья Воронцов, Ксения Тихомирова
Куратор проекта: Илья Булгаков