Лучше один раз нарисовать, чем сто раз посмотреть
Выборки данных (почитать о них можно в нашем материале) часто представляют из себя таблицы, где каждая строка содержит различные числовые/строковые значения и является одним конкретным наблюдением. Рассмотрим для примера 3 случайные строки из выборки с данными пингвинов:
| Вид | Остров обитания | Длина верхнего гребня клюва (мм) | Глубина верхнего гребня клюва (мм) | Длина плавника (мм) | Вес (г) | Пол |
| Chinstrap | Dream | 49.6 | 18.2 | 193.0 | 3775.0 | MALE |
| Gentoo | Biscoe | 49.6 | 15.0 | 216.0 | 4750.0 | MALE |
| Adelie | Dream | 43.2 | 18.5 | 192.0 | 4100.0 | MALE |
Каждая строка описывает конкретного пингвина (то есть пингвин — наблюдение), значения строки называются признаками. Всего в выборке 344 наблюдения и 7 признаков. Это относительно немного, но даже при таком размере выборки уже затруднительно делать какие-либо выводы, просто смотря на таблицу. Поэтому появляется необходимость представить данные другим способом — например, визуально.
Тысяча и один график: для каждой гипотезы и идеи — свой график
Визуализация данных происходит с помощью построения графиков. Существует огромное количество графиков — выбор типа графика зависит от цели, которую ставит исследователь.
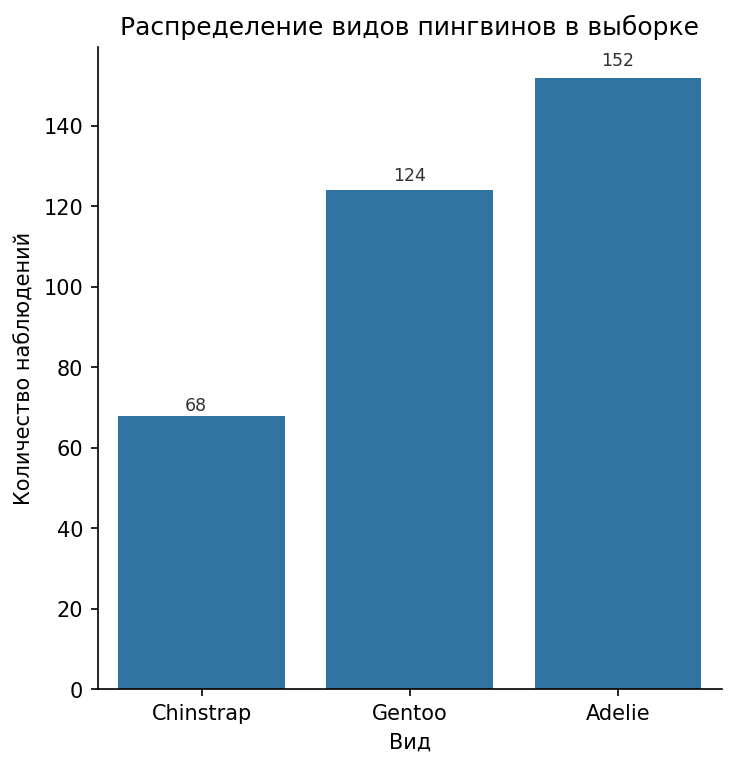
Например, если мы хотим понять, сколько пингвинов каждого вида есть в нашей выборке (другими словами — мы хотим узнать распределение видов в выборке), то мы можем использовать столбчатую диаграмму (bar plot):
А можно использовать круговую диаграмму (pie chart):
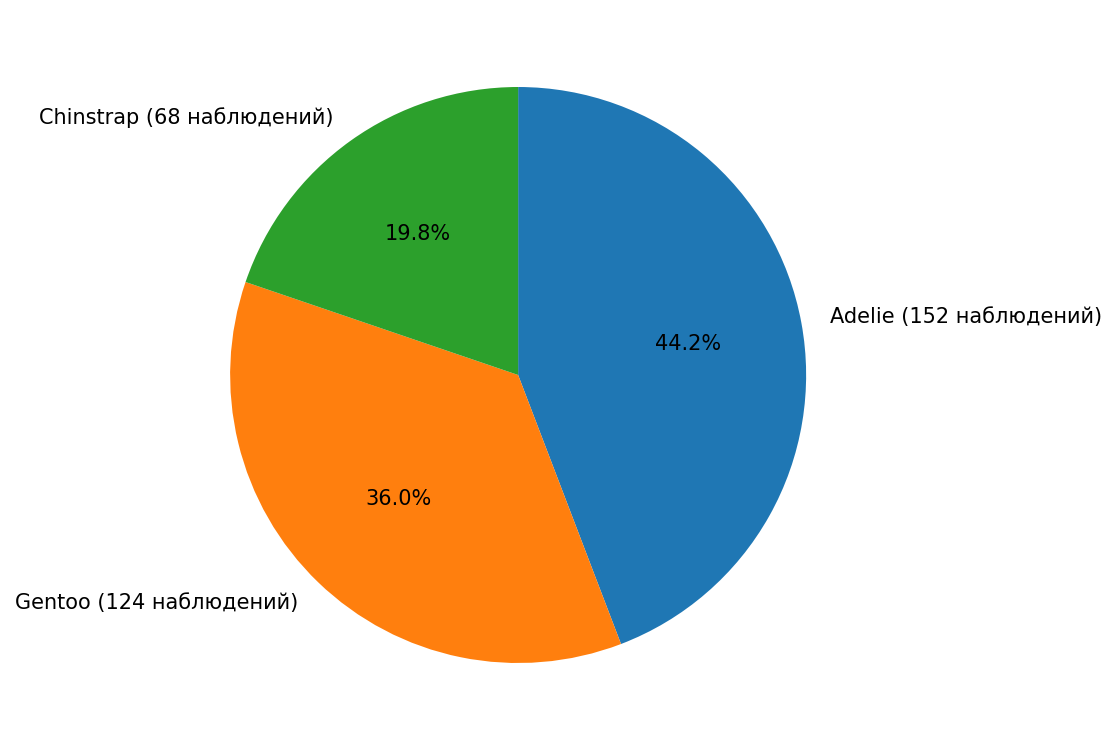
Благодаря этим графикам, мы можем понять, что больше всего у нас данных о пингвинах Adelie, а меньше всего — о Chinstrap. Теперь рассмотрим более подробно один конкретный вид (Gentoo). Для этого построим гистограмму (histogram) длин плавников пингвинов этого вида:

Гистограмма строится следующим образом:
- Берутся значения признака всех наблюдений, содержащихся в выборке. В нашем случае мы берём длины плавников пингвинов Gentoo, сведения о которых есть в выборке.
- Находим минимальное и максимальное значения признака: 172 мм и 231 мм соответственно. Эти значения — границы гистограммы.
- Числовой отрезок делим на отрезки равной длины. В нашем примере длина отрезка равна 5.
- Для каждого полученного отрезка считаем количество наблюдений, у которых значение рассматриваемого признака попадает в этот отрезок. После этого строим столбик, высота которого равна полученному числу. Например, если посмотреть на гистограмму из примера, то первый столбик, соответствующий отрезку [172, 177], имеет высоту 3, то есть в выборке три пингвина, у которых длина плавника находится в пределах от 172 до 177.
Гистограмма позволяет понять, как распределены значения изучаемого признака (длина плавника). Например, по построенному графику видно, что в выборке больше всего пингвинов с длиной плавника от 187 мм до 192 мм, а меньше всего пингвинов — с длиной плавника от 172 мм до 177 мм.
Следует отметить, что от длины отрезков, на которые разбивается числовая прямая, напрямую зависит вид гистограммы, а следовательно, и выводы, которые делаются по ней. Выбор оптимальной длины отрезка — отдельная большая тема.
Теперь нарисуем гистограммы длин плавников для разных видов:
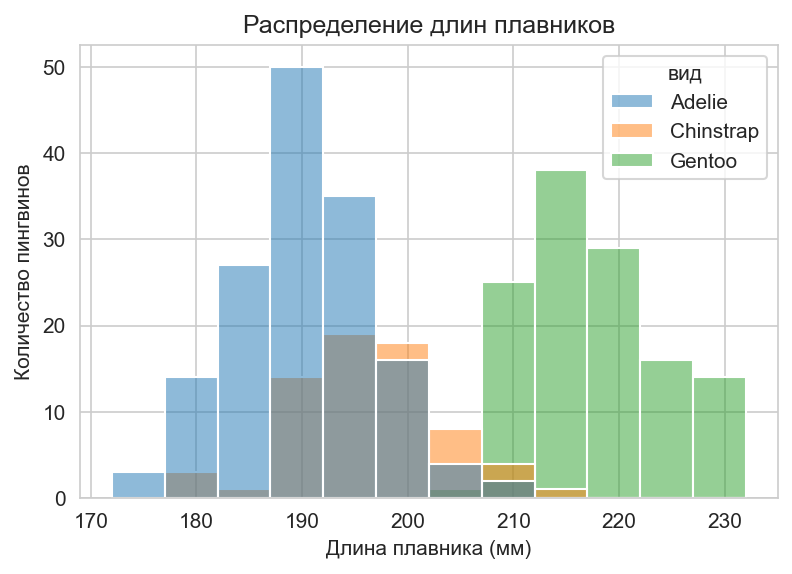
На построенном графике уже три гистограммы, для каждого вида гистограмма имеет свой цвет. Исходя из этого графика, можно сделать выводы, что у пингвинов вида Adelie плавники короче, чем у пингвинов Gentoo, поскольку синяя гистограмма расположена левее зелёной.
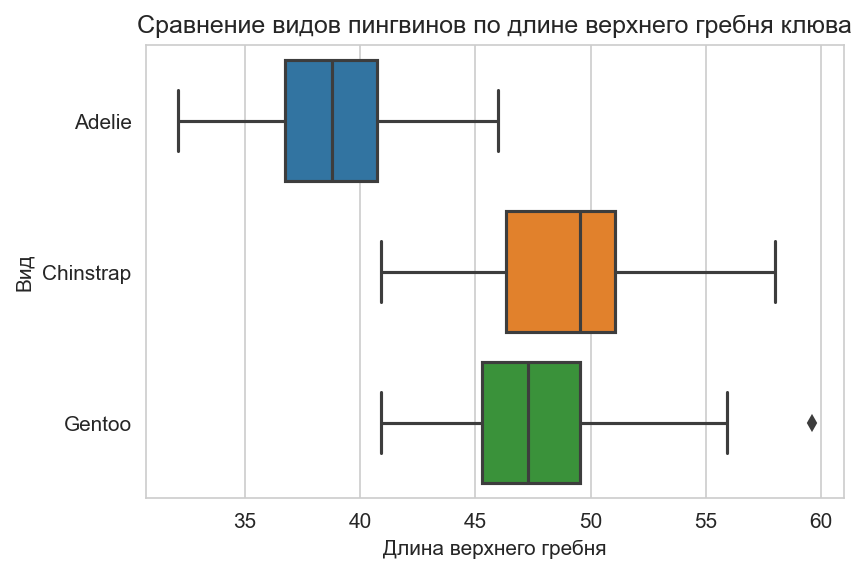
Допустим, вы хотите провести аналогичное сравнение видов пингвинов, но уже по длине верхнего гребня клюва. Можно было бы опять нарисовать гистограммы, но есть и другой вид графика, который подходит для такого рода задач, — ящик с усами (boxplot):
Ящик с усами представляет из себя прямоугольник (ящик) с двумя отрезками (усами) по обе стороны ящика.
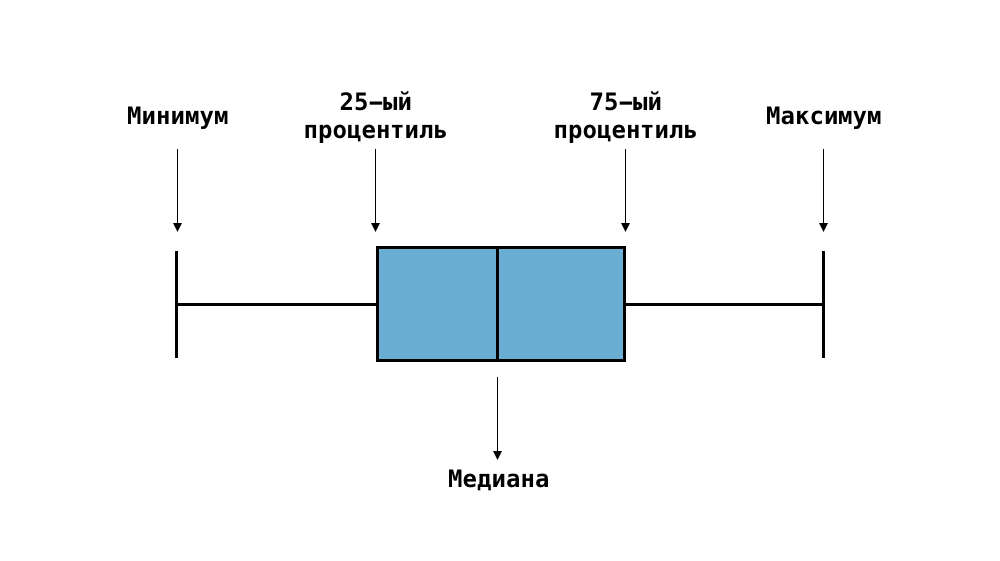
Концы усов отображают минимум и максимум исследуемого признака без учёта выбросов. Выброс — аномальное наблюдение, которое сильно отличается от всех остальных наблюдений; зачастую (но не всегда) причиной появления выброса в выборке является ошибка измерений. Так, у Gentoo минимальная длина верхнего гребня клюва равна 40,9 мм, а максимальная — 59,6 мм. Границы ящика обозначают 25-й и 75-й процентили.
25-й процентиль — это такое число, что у 25% наблюдений в выборке значение признака меньше его. Например, у пингвинов Gentoo 25-й процентиль равен 45,35 мм, это означает, что у 25% пингвинов этого вида длина верхнего гребня клюва меньше 45,35 мм. Аналогично определяется 75-й процентиль. Чем шире ящик, тем более разнообразные значения принимает признак (то есть имеет большую дисперсию); чем уже ящик, тем более значения признака однообразны. Ромбики, которые располагаются по разные стороны от усов, соответствует выбросам — тем значениям признака, которые сильно отличаются от большинства (они не учитываются при подсчёте минимальных и максимальных значений)
Вернёмся к нашему графику:
Судя по нему, можно сделать вывод, что самые длинные клювы — у Chinstrap, а самые короткие — у Adelie. При этом в выборке есть аномальное наблюдение (изображено ромбиком справа), а именно пингвин Gentoo с очень длинным клювом. Вполне вероятно, что была совершена ошибка, а может быть, действительно существует такой длинноносый пингвин. Также отметим, что наибольший разброс значений признака — у Chinstrap, то есть если вы «померяете» несколько пингвинов этого вида, то ваши измерения будут сильно меняться от пингвина к пингвину.
Можно задать еще множество вопросов про пингвинов и ответить на них с помощью построения графиков, но помимо выборок-таблиц есть и другие виды данных, визуализация которых не всегда столь же тривиальна.

Пингвины — это хорошо, но…
Не всегда данные представляются в виде таблицы, у которой можно взять столбец (то есть значения определённого признака всех наблюдений) и построить график, который будет отображать статистические характеристики выборки. Например, как «визуализировать» тексты? Можно ли визуализировать работу нейронной сети? На эти вопросы мы ответим далее.
Для начала разберёмся с текстами. Возьмем выборку из статей BBC за 2004-2005 года. Допустим, мы хотим выделить из этой выборки темы, о которых писали журналисты BBC, а также слова, которые характеризуют каждую тему. Для этого сделаем следующее:
- Каждую статью преобразуем: объединим заголовок и текст статьи → в полученном тексте уберём знаки препинания, цифры и стоп-слова (предлоги, союзы, артикли и тд.) → проведём лемматизацию (приведём слова к нормальной форме).
- К каждому преобразованному тексту применим TF-IDF, то есть, говоря простым языком, сопоставим тексту слов набор чисел, который его «характеризуют». Поставить в соответствие тексту набор чисел можно и другими способами: Word2Vec, BERT, UniLM.
- Проведем кластеризацию полученных наборов чисел, т.е разобьем их на группы таким образом, что в каждой группе наборы похожи друг на друга, а наборы разных групп — нет. Про кластеризацию можно почитать здесь.
По сути, на этом этапе мы сгруппировали статьи по их тематической схожести. Осталось понять, к какой теме относится каждая группа текстов и какие слова характерны этой теме. Для этого мы воспользуемся облаками слов (тегов).

Облако слов строится по корпусу текстов. Размер слова в облаке определяется частотой встречаемости слова в корпусе — чем чаще встречается слово, тем слово больше, и наоборот.
Применим эту визуализацию к нескольким полученным группам:
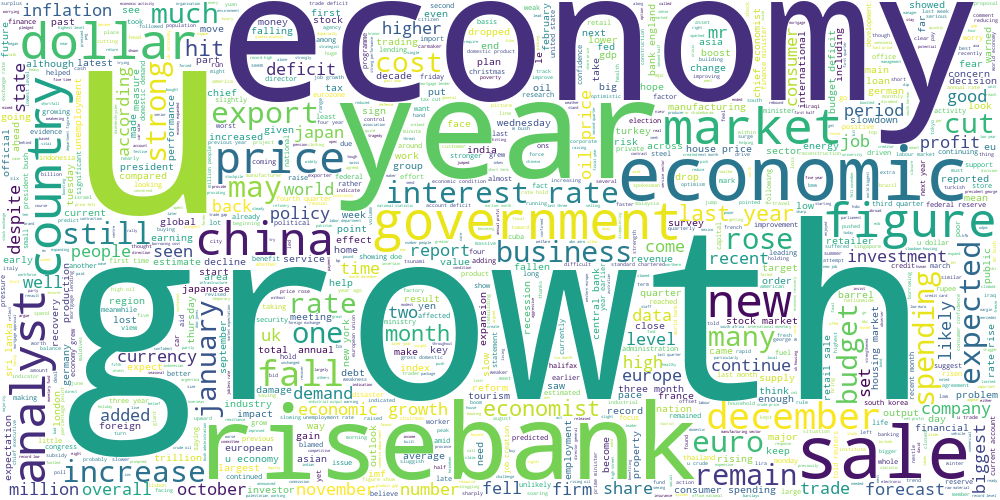
Судя по самым частотным словам (economy, growth, market..), эта группа текстов про экономику.
Следующая группа — про политику:
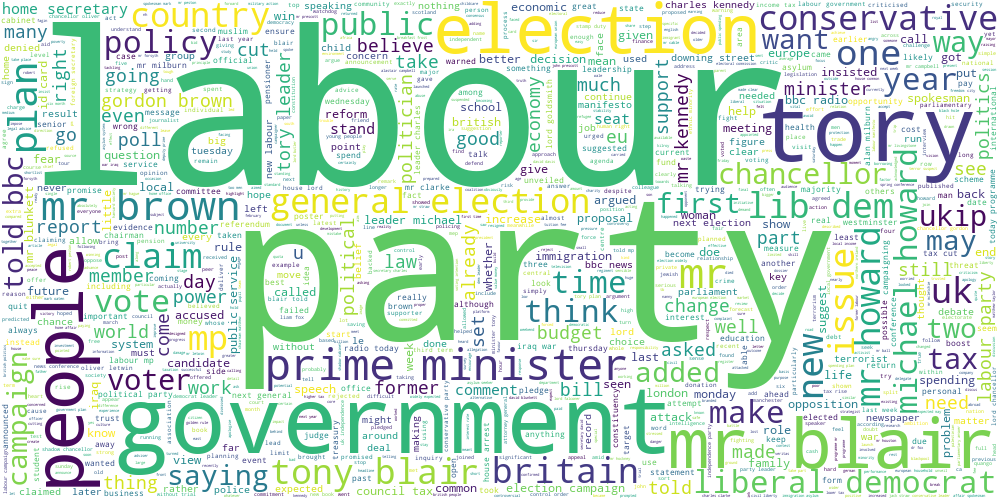
И последняя — про кино:
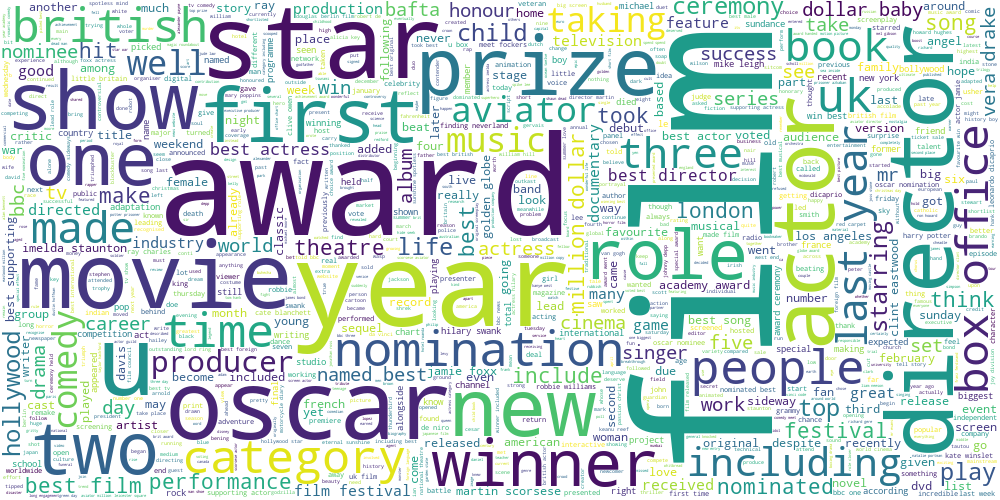
Благодаря несложным методам NLP и облакам слов мы смогли выделить темы в большом корпусе статей и наглядно проиллюстрировать их.
Какие секреты таят в себе нейросети?
Инструменты визуализации данных помогают не только компьютерным лингвистам, журналистам и аналитикам, но и исследователям искусственного интеллекта. Современные нейросети устроены чрезвычайно сложно, что делает их тяжело интерпретируемыми. То есть понять, каким образом нейросеть решает задачу, на что она «полагается», непросто. Понимание, как модель работает «внутри», важно не только в исследовательских целях, но и в практических применениях: например, если решение о выдаче кредита генерируется моделью, то необходимо иметь возможность объяснить клиенту, почему модель вынесла именно такой вердикт.
В случае популярного метода Word2Vec, с помощью визуализации можно понять свойства представлений слов, которые он извлекает. Word2Vec сопоставляет слову вектор или, другими словами, набор чисел — обычно в наборе либо 64, либо 300 элементов. Векторы всех слов образуют пространство. Пространство характеризуется размерностью — количеством чисел в каждом векторе (наборе). К примеру, координаты в пространстве являются наборами из трех чисел: координата по ширине, по высоте и по глубине — все такие наборы образуют трехмерное пространство. Человеческому мозгу вполне реально представить двумерное или трехмерное пространство, но сложно представить себе трехсотмерное пространство. Но из трехсотмерного пространства можно «перейти», например, в двумерное. Для этого используются так называемые техники снижения размерности, которые позволяют «сжать» информацию из множества измерений в несколько таким образом, чтобы оставить наиболее важные отличительные характеристики вектора.
Существует ряд подобных техник, в нашем случае мы будет использовать метод tSNE. Особенность этого метода в том, что он работает нелинейно: более похожие друг на друга векторы в исходном пространстве будут представлены более близкими векторами в итоговом, а поэтому посмотрев на изображение, будет проще увидеть кластеры похожих объектов.
В этом примере мы получили благодаря обученной Word2Vec-модели векторы различных слов, которые можно отнести к трем категориям: еда (борщ, сметана), животные(хомяк, лисица) и цветы (герань, незабудка). Размерность каждого вектора равна 300. Затем мы использовали tSNE, чтобы «сжать» 300 чисел в два, и в конце нарисовали полученные двумерные векторы на графике.
Каждая синяя точка соответствует «сжатому» с помощью tSNE вектору модели Word2Vec. Слова из каждой группы объединились в кластеры, расстояния внутри которых меньше, чем между словами разных кластеров.
Модель Word2Vec устроена так, что чем чаще слова используются в одном контексте, тем ближе друг к другу их векторы. Это заметно и на визуализации: например, герань и фиалка (домашние цветы) находятся немного поодаль от полевых цветов — маргаритки или незабудки. Сельскохозяйственные животные (корова и свинья) находятся на расстоянии от диких — лисицы или кабана. То есть с помощью tSNE мы смогли сжать исходные 300-мерные векторы, которые невозможно нарисовать и представить, в двумерные векторы, которые легко визуализируются. Таким образом визуализация позволила наглядно проверить свойство модели, которое авторы явно закладывали в нее. Однако методами понижения размерности стоит пользоваться аккуратно — сжимая высокоразмерные данные в низкоразмерные, мы обязательно теряем часть информации. Поэтому полученные подобным образом визуализации не отображают все особенности исходных данных.
Также с помощью методов визуализации можно сравнивать разные нейросети. Например, в статье [1] авторы, визуализируя работу разных моделей, предназначенных для поиска изображений по текстовому описанию, доказывают эффективность своего подхода:
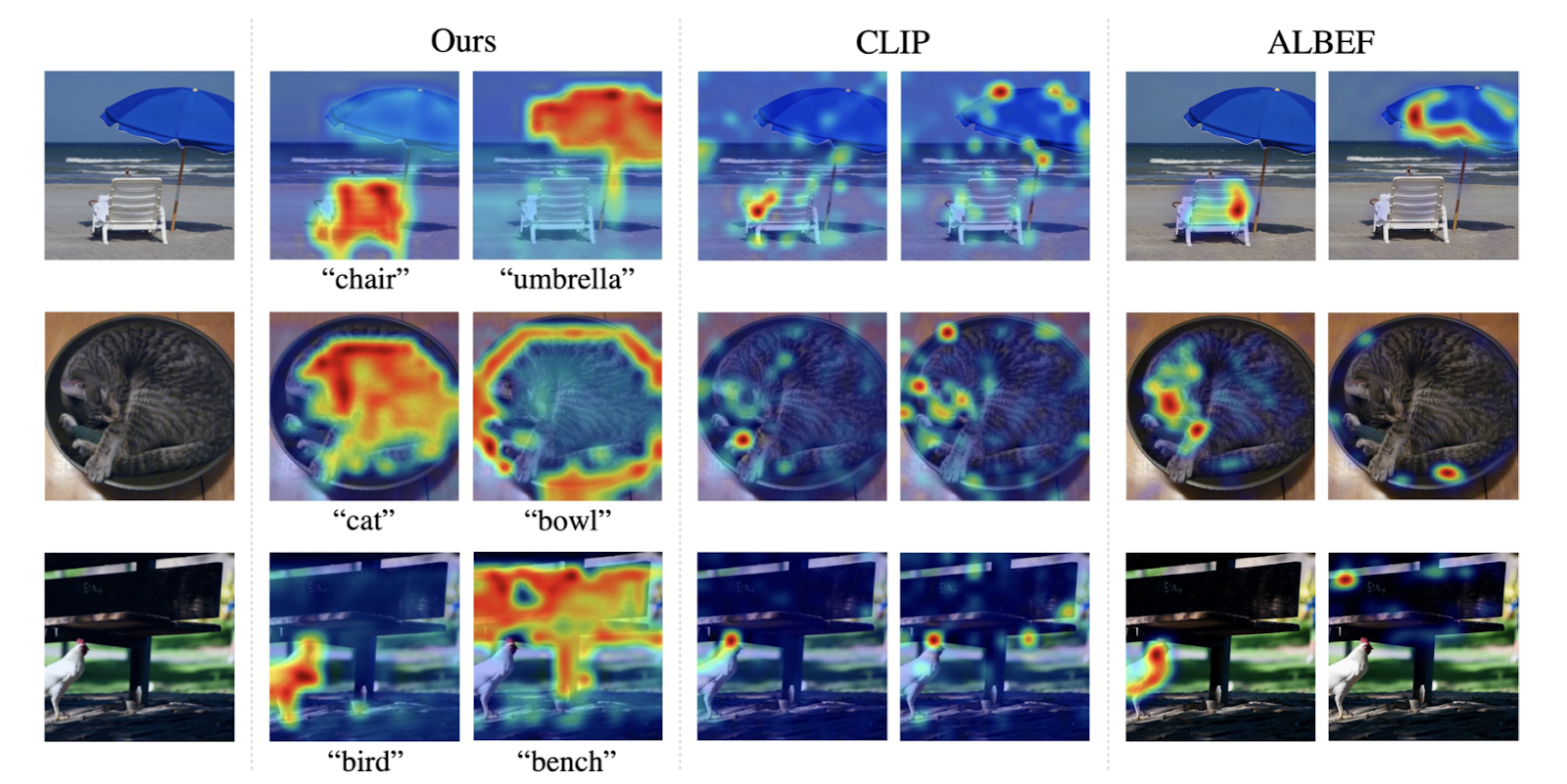
В первой колонке показаны изображения, на которых тестируются модели. Далее идут визуализации работы разных моделей: вторая и третья колонки соответствуют модели, представленной в статье, следующие две — модели CLIP [2], и последние две — модели ALBEF [3]. На каждой визуализации разными цветами (от синего до красного) выделены участки изображения, которые, по мнению модели, соответствуют слову. Чем теплее окрашен участок, тем более уверена модель. Например, предложенная авторами модель уверенно выделила на первом изображении стул (второе изображение в первом ряду), а моделям CLIP и ALBEF это не удалось (четвёртое и шестое изображения в первом ряду). Особенно разница работы нейросетей видна в случае изображения кошки в миске — выделить кошку и миску смогла только одна модель.
Визуализация в реальной жизни
В этом материале мы рассказали только о небольшом множестве способов визуализации данных. В реальной жизни часто приходится отходить от стандартных методов и проявлять креативность. Вот несколько примеров графиков дата-отдела «Системного Блока»:
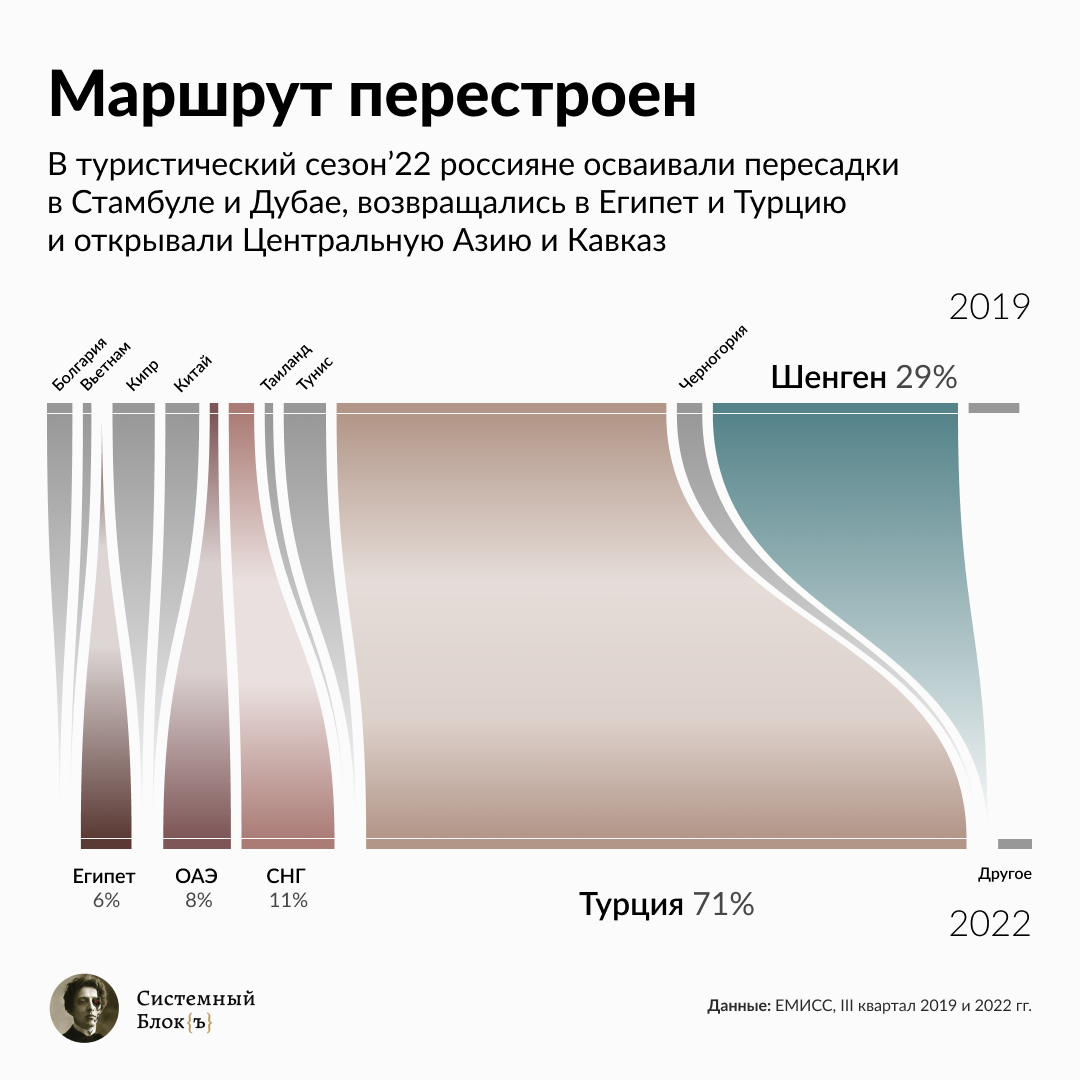

Помимо статичных изображений, также можно использовать динамические и интерактивные визуализации, как в этой статье.
Глаза (не) врут
Хоть визуализация и позволяет извлекать полезные знания из данных, стоит скептически относиться к выводам, которые получаются благодаря ней. Визуализация в большинстве случаев позволяет отобразить один или несколько аспектов данных, но не все разом. Поэтому при формулировании выводов по визуализациям легко упустить что-то значимое. Также важно обращать внимание, на каких данных строилась визуализация — визуализация, построенная на нерепрезентативных данных, не несет никакой ценности, как и сами данные.
Источники
[1] Jang, Jiho, et al. «Unifying Vision-Language Representation Space with Single-tower Transformer.» arXiv preprint arXiv:2211.11153(2022).
[2] Radford, Alec, et al. «Learning transferable visual models from natural language supervision.» International conference on machine learning. PMLR, 2021.
[3] Li, Junnan, et al. «Align before fuse: Vision and language representation learning with momentum distillation.» Advances in neural information processing systems 34 (2021): 9694-9705.



