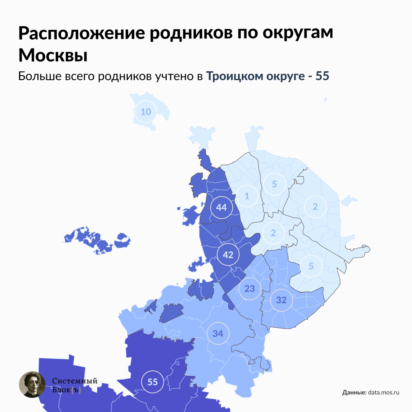
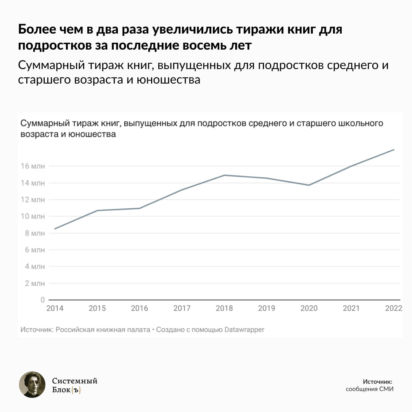
На последнем дыхании: туберкулёз в России в цифрах и фактах
Туберкулёз относится к числу социально значимых заболеваний, способных ухудшать не только жизнь одного человека, но и всего общества. «Системный Блокъ» изучил с опорой на данные, насколько туберкулёз распространён в России, от чего зависит заболеваемость, почему пациенты до сих пор остаются стигматизированными и как уберечь себя и своих близких от заражения.